Lecture
How can I find out the life of the hard disk; Where is the face of wear, to achieve which the HDD is an urgent need to change? MTBF comes to the rescue - an indicator of time to failure
We all understand that the loss of data can affect each of us very, very negatively. For many of us, the loss of meaningful information occurs in the form of a hard drive failure (HDD). These can be various mechanical and electronic defects that make the information stored on the hard disk inaccessible for reading. There are dozens of possible causes for this type of failure, ranging from logical software errors to obvious or implicit physical damage to the HDD. However, we cannot fail to mention that all data storage devices have a limited lifespan.
Most of us can name some signs that the hard drive is on the verge of breaking down. For example, if your HDD disk makes sounds - from a pleasant buzz to the ear, grinding noise, then this is a sign that the hard disk is going to "glue the flippers." In addition, if data access on the PC slows down or strange actions or phenomena (damaged data, bad-sector and missing files) begin to appear, these are all reliable indicators of the hard disk's performance.
Unfortunately, there are no so-called scientific indicators for detecting a malfunction of the HDD and its future breakdowns or failure - although this would help prevent information loss and promptly resort to urgent repair of the HDD. At the same time, there are ways to monitor various "oddities" that occur with your laptop or desktop PC. You can also apply the same methodology to disk arrays for independent disks (RAID) through a remote data center.
So, how can business users, corporate and personal users predict when their hard drives will reach the verge of performance? The first step is to check the manufacturer’s estimate of the life span of the device. These estimates are usually given as the average time between failures, or MTBF. This is a common guide for hard drives. What does this actually mean and is the failure time rating, MTBF, calculated?
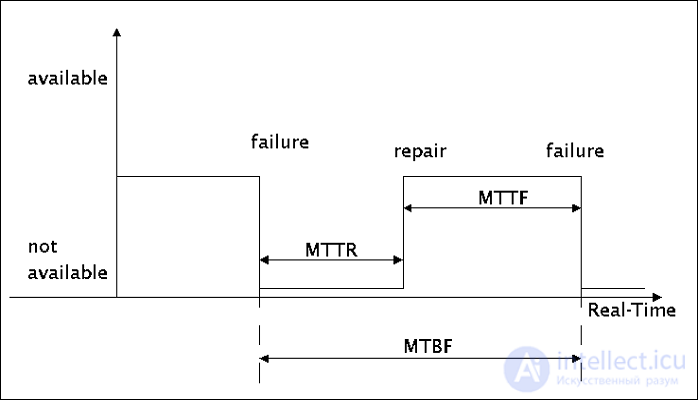
The MTBF rating stands for how it sounds. This is the average time period between one inherent error and the next in the lifetime of one component. In other words, if a malfunction was found and then repaired, the mean time between failures is a figure, the number of hours when the hard disk can be expected to function in normal mode before it breaks again or the smallest malfunction is found.
In the case of consumer hard drives, it is not uncommon to see MTBF in the range of about 300,000 hours. It is 12,500 days, or just over 34 years. Meanwhile, higher-end hard drives are advertised with MTB for up to 1.5 million hours, which is about 175 years. Would you like to imagine how a hard disk works reliably for hundreds of years? That would be a fairy tale for IT managers!
Unfortunately, there is a difference between the mean time between failure metrics and real life expectancy. The MTBF metric has a long and outstanding pedigree in military and aerospace engineering. Figures are taken from the error rate in a statistically significant number of drives operating for weeks or months at a time.
Studies have shown that, as a rule, MTBF in reality has a lower figure. In 2007, researchers at Carnegie Mellon University examined samples of 100,000 hard drives with an installed MTB, subject to time between failures from one million to 1.5 million hours. This results in an annual failure (AFR) of 0.88 percent. However, this study showed that the index, as a rule, exceeds one percent - from three to six percent to 13 percent in some information storage systems.
Manufacturers do not close their eyes to the discrepancy of the MTBF index to the actual lifespan of the HDD drive. Recently, Seagate and Western Digital manufacturers have stopped using mean time to failure metrics for their hard drives. Instead, the user is forced to use third-party software for diagnostics (for example, Victoria) or to investigate the SMART diagnostic indicators (read below).
In general, the MTBF indicator makes sense only when the device has a constant failure rate, i.e. failures are distributed exponentially. Hard drives, first of all, mechanical devices, with mechanical failures. That is, mechanical failures are generally distributed.
If we assume that the application uses a large number of hard drives, and the errors are distributed exponentially, the number of failures in any two intervals of the same size will be the same. The hard drive will generate errors in the 100th day, as in the 10,000th day. Hard drives in actual use have different wear. After the initial phase of "infant mortality" (when errors are minor), some point in time will occur when the failure rate increases dramatically. For typical mechanical hard drives, the wear point is between 3 and 5 years of continuous use.
How to check hard disk for errors?
Due to the fact that since the mean time to failure index is a relatively unreliable indicator of hard disk health, how else can we predict the end of the life of a hard disk or other storage device? Next, we will discuss the pros and cons of using SMART - a diagnostic tool that will allow you to determine the time of hard disk wear.
Average time between failures (MTBF ) is a technical parameter characterizing the reliability of the restored device, device or technical system.
The average duration of the device between failures, that is, shows what the average time between failures per failure. It is expressed in hours.
{\ displaystyle T = {\ sum _ {1} ^ {m} t_ {i} \ over m}} 
where t i - time between failures i; m is the number of failures.
It is measured statistically, by testing a variety of devices, or calculated by methods of the theory of reliability.
For software products, this usually means the period until the program is completely restarted or the operating system is completely rebooted.
Mean time to failure ( eng. Mean time to failure, MTTF ) is an equivalent parameter for an unrepairable device. Since the device is not recoverable, it is just the average time that the device will work until it breaks.
Hours - the duration or volume of work of the object, measured in hours, motorcycle hours, hectares, kilometers, cycles of inclusions, etc.
this applies to the theory of reliability of any systems .. not only hard drives or electronic devices
GOST 27.002-89 defines these parameters as follows:
In the English literature, MTBF (English Mean Time Between Failures - mean time between failures, time between failures) - mean time between occurrences of failures. [1] ; The term usually refers to the operation of equipment. The unit of dimension is the hour.
Systems related to security can be divided into two categories:
IEC 61508 (Eng.) Russian. quantifies this classification, establishing that the frequency of requests for the operation of the security system does not exceed once a year in the low request rate mode, and more than once a year in the high request rate mode (continuous operation).
The value of SIL (English) Russian. for security systems with a low request rate, it directly depends on the ranges of orders of the average probability that it will not be able to satisfactorily perform its security functions on demand, or, more simply, on the likelihood of a failure on request (PFD). The SIL value for security systems operating in the high request rate mode (continuous) directly depends on the probability of occurrence of a dangerous failure per hour (PFH).
In turn, λ = failure rate = 1 / MTBF (for exponential distribution of failures)
For one device:
For two devices. Failure of at least one device:
For two devices. Failure of all devices:
For 10 devices: Failure of at least one device:
For 100 devices: Failure of at least one device:
MTBF is the term reliability used to provide the number of failures per million hours for a product. This is the most common query about the longevity of a product, and also plays an important role in the end-user decision making process. MTBF is more important for industries and integrators than for consumers. Most consumers of prices are driven and will not take into account the mean time between failures, nor the data are often readily available. On the other hand, when equipment such as media converters or switches must be installed in mission-critical applications, time to failure becomes very important. In addition, MTBF may be an expected position in the Request for Proposals (Request for Cost). Without proper data, the equipment manufacturer will immediately disqualify ed.
Average Repair Time (MTTR) is the time it takes to repair a failed hardware module. In the operating system, repair usually means replacing the failed hardware. Thus, the hardware MTTR could be considered as the average time to replace the faulty hardware module. Taking too long to repair the product inflates the installation cost ultimately, due to the downtime, until a new part comes along and a possible window of the time needed to plan the installation. To avoid MTTR, many companies purchase replacement products, so replacing can be installed quickly. In general, however, customers will ask about the turnaround time of product repair, and indirectly, what could fall into the category of MTTR.
The mean time between replacements (MTBR) is typically used for non-recoverable components or subsystems in a recoverable system. For example, a light bulb in a car is replaced every Tp of working hours or replaced when it fails. The average time between replacements of metric describes the average time between two consecutive replacements under these conditions.
MTBF (MTTF) is the main indicator of reliability for non-recoverable systems. This average time is not expected until the failure of the first piece of equipment. MTTF is a statistical value, and is intended to be average for a long period of time and a large number of units. From a technical point of view, MTBF should be used only for the item being recovered, while MTTF should be used for non-recoverable items. However, time between failures is usually used for both recoverable and non-recoverable items.
The average running time at the Downing Event (MTBDE) describes the expected time between two consecutive Downing events for the system being restored.
Time Failure (FIT) is another way of presenting MTBF. FIT reports the number of expected failures per billion operating hours for a device. This term is used especially in the semiconductor industry, and is also used by component manufacturers. FIT can be quantified in a number of ways: 1000 devices for 1 million hours or 1 million devices for 1000 hours each, and other combinations. FIT and confidence intervals (CL) are often provided together. In general use, claiming 95% confidence in something, as a rule, is taken as an indication of virtual certainty. In statistics, a claiming 95% trustee simply means that the researcher has seen something happen, which happens only once every twenty or less. For example, component manufacturers will take a small sample of the component, test x number of hours, and then determine if there are any failures in the test bench. Based on the number of failures that occur, the CL will then be provided as well.

Comments
To leave a comment
Diagnostics, maintenance and repair of electronic and radio equipment
Terms: Diagnostics, maintenance and repair of electronic and radio equipment