Lecture
In Lecture 21, we became acquainted in detail with the scheme of a statistical computer experiment. In Lectures 21-26, we examined the practical implementation of all the basic blocks (see Fig. 21.3) of this scheme. Now it is important to learn how to organize the work of the last two blocks - the block for calculating statistical characteristics (BVSH) and the block for assessing the reliability of statistical results (AML).
So, we will consider how to fix the statistical values as a result of the experiment in order to obtain reliable information about the properties of the object being modeled. Recall that the generalized characteristics of a random process or phenomenon are average values.
The calculation of the average values during the experiment, which is repeated many times, and its result is averaged, can be organized in several ways:
Method 1. Calculate all statistics at the end. To do this, in the course of the experiment, the values of X i the output (studied) random variable X are accumulated in the data array. After the end of the experiment, the expectation (average) X and the variance D (the characteristic variation of the values relative to this expectation) are calculated.
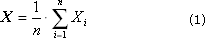
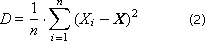
Often, the standard deviation σ = sqrt ( D ) is used.
Note that the disadvantage of the method is the inefficient use of memory, since it is necessary to accumulate and save a large number of values of the output value during the whole experiment, which can be very long.
The second minus is that you have to read the array X i twice, because using formula (2) as it is written here, we can only calculate the formula (1) (from 1 to n ), and then again banishing for the formula (2) the array X i .
A positive point is the preservation of the entire data set, which makes it possible to study it in more detail later if necessary to investigate certain effects and results.
Method 2. Calculation of all statistics in the calculation process (by recursive relations). This method provides the ability to store only the current value of the mathematical expectation X i and the variance D i corrected at each iteration. This saves us from the need to permanently store the entire array of experimental data. Each new Xi given is taken into account in the sum with a weighting factor - the more i terms accumulated in the Xi amount, the more important its value is relative to the regular amendment Xi , therefore the ratio of the weighting factors i / ( i + 1): 1 / ( i + 1).
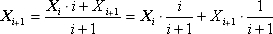
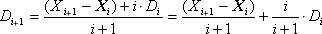
where X i is the next value of the experimental output value.
Method 3. Calculation of all statistics in class intervals. This method assumes that not all values of X i will be accumulated in the array, but only over significant intervals in which the random output value X i is distributed. The total interval of change of X i is divided into m subintervals, in each of which the number n i is recorded, which indicates how many times X i took a value from the i -th interval. With a small number of intervals ( m ≈ 1) we get method 1, with the number of intervals m = n we get method 2. In case 1 < m < n, we get an average solution - a compromise between the memory occupied and the information content of the output data.
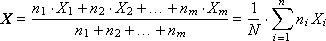
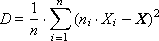
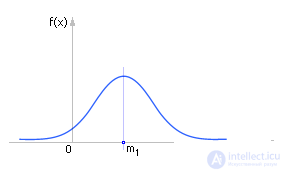
Even more informative is the calculation of the geometry of the distribution of a random variable. It is necessary in order to imagine more accurately the nature of the distribution. It is known that the value of the statistical moment can be approximately judged on the geometric form of the distribution.
The first moment (or arithmetic average) is calculated as follows:
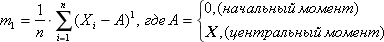
If A takes the value 0, then the first moment is called the initial moment, if A takes the value X , then the first moment is called central. (In principle, A can be any number given by the researcher.)
In practice, it is customary to use not the first moment itself, but its normalized value R 1 = m 1 / σ 1 .
The first moment indicates the center of gravity in the geometry of the distribution, see fig. 34.1.
| |
| Fig. 34.1. Characteristic position of the first moment on the graph of statistical distribution |
The second moment (or variance, scatter) is calculated as follows:
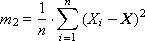
You are familiar with the concept of standard deviation associated with the second point:
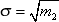
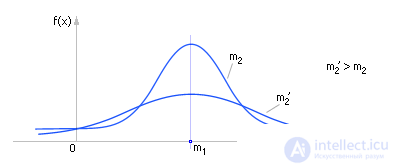
In practice, it is customary to use not the second moment itself, but its normalized value R 2 = m 2 / σ 2 .
Dispersion characterizes the magnitude of the spread of experimental data relative to the center of gravity m 1 . Thus, by the value of m 2 it is possible to judge the second parameter of the geometry of the distribution (see. Fig. 34.2).
| |
| Fig. 34.2. Characteristic change in the type of statistical distribution magnitude depending on the magnitude of the second moment |
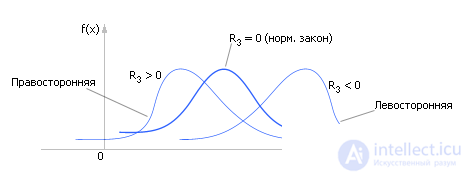
The third moment is characterized by asymmetry (or skewness) (see. Fig. 34.3) is calculated as follows:
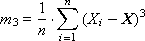
In practice, it is customary to use not the second moment itself, but its normalized value R 3 = m 3 / σ 3 .
| |
| Fig. 34.3. Characteristic change in the type of statistical distribution magnitudes depending on the magnitude of the third moment |
By determining the sign of R 3 , it is possible to determine whether the distribution has asymmetry (see Fig. 34.3), and if there is ( R 3 ≠ 0), then in what direction.
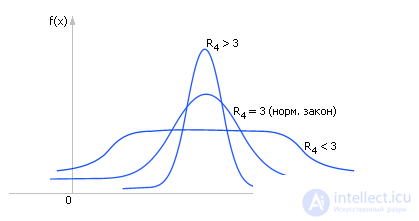
The fourth moment (see fig. 34.4) characterizes the excess (or peakedness) and is calculated as follows:
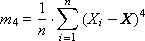
The normalized moment is: R 4 = m 4 / σ 4 .
| |
| Fig. 34.4. Characteristic change in the type of statistical distribution magnitudes depending on the magnitude of the fourth moment |
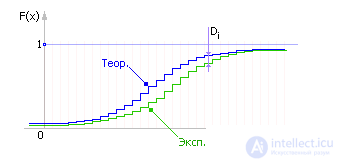
It is very important to find out which distribution most closely resembles the obtained experimental distribution of a random variable. The assessment of the degree of coincidence of the empirical distribution law with the theoretical one is carried out in two stages: the parameters of the experimental distribution are determined and then, according to Kolmogorov, the experimental distribution of the theoretical distribution is assessed.
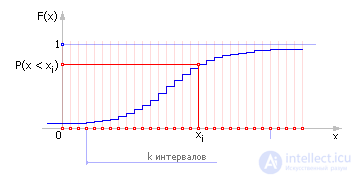
| |
| Fig. 34.5. Integral law of empirical distributions, discrete variant (example) |
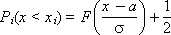
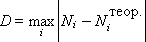
| |
| Fig. 34.6. Comparison of theoretical and empirical integral distributions of a random variable (discrete option) |
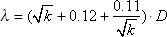
Next, using the table. 34.1 Kolmogorov, should accept or reject the hypothesis of whether the empirical distribution with a given probability Q is theoretical or not. To accept the hypothesis should be: λ < λ table. .
| Table 34.1. Kolmogorov criterion table | ||||||||||
|
Note Kolmogorov's criterion is not the only one that can be used for evaluation You can use the Chi-square criterion, the Anderson-Darling criterion and others.
The crucial question is how many experiments should be done so that you can trust the captured characteristics. If the experiments are not enough, then the characteristic is unreliable. Typically, the researcher sets the confidence level, that is, the probability with which he is willing to trust the captured characteristics. The more confidence is given, the more experiments will be required. Previously, we used other methods for estimating the required number of experiments (see Lecture 21, an example of a coin).
So now our estimate will be based on the central limit theorem (see Lecture 25, which states that the sum (or average) of random variables is non-random. The CLT claims that the values of the statistical characteristic we calculate will be distributed according to the normal law, n i is the number i-th outcomes of the values of the statistical characteristics in n experiments, p i = n i / n is the frequency of the i- th outcome.
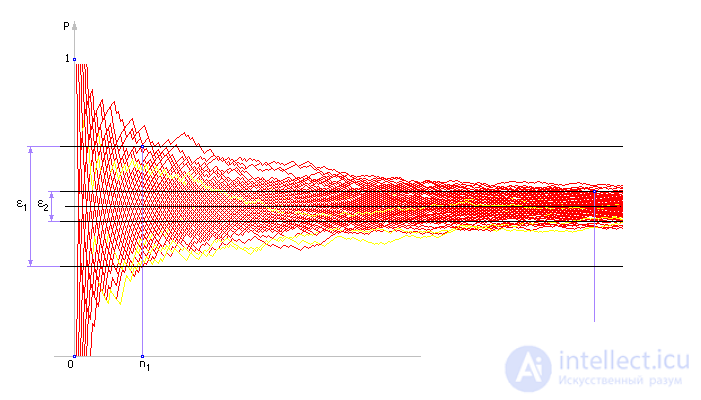
If n -> ∞, then p -> P (the frequency p tends to theoretical probability P ) and the empirical characteristics will tend to theoretical (see. Fig. 34.7). So, according to the CLT, p will be distributed according to the normal law with the expectation m and the standard deviation σ .
Moreover, m = P , σ = sqrt ( p · (1 - p ) / n ).
Let Q be the confidence probability , that is, the probability that the frequency p differs from the probability P by no more than ε . Then, by the Bernoulli theorem:

The value of ε is called the confidence interval. The meaning of ε is that in the series (each by sample n ), on average, ε · 100% confidence intervals contain the true value of the statistical characteristic p . As before (see Lecture 25), F is an integral of the function of the normal distribution law, an integral function of Laplace.
| |
| Fig. 34.7. Illustration for calculating the number of experiments in magnitude confidence interval according to the central limit theorem |
From here we can express the number of experiments required for a confidence probability ( F –1 is the inverse Laplace function):
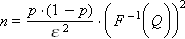
Example. When modeling an enterprise’s products as a result of imitating its work, the following output data were obtained for 50 days (see Table 34.2).
| Table 34.2. Experimental Simulation Statistics | |||||||||||||||
|
That is, the total was carried out: 15 + 10 + 5 + 20 = 50 experiments ( n = 50). From the table of experiments, the answer of the problem follows, that the frequency (probability) of the release of products of grade 1 is 15/50, the frequency (probability) of release of products of grade 2 is 10/50, the frequency (probability) of release of products of grade 3 is 5/50, the frequency (probability a) release of products 4 grade equal to 20/50.
Let us set the confidence probability for the model answers Q = 0.9 and the confidence interval ε = 0.05.
Now we have to answer the question: is it possible to trust the calculated answer with probability Q ?
We will evaluate the result of statistical experiments according to the worst probability, such in our problem is p = 0.4, since the probability, for example, 0.1 is much better defined.
Very important note . In general, the probabilities (particulars) close to 0 or 1 are very attractive as an answer, since they completely determine the solution. Probabilities close to 0.5 indicate that the answer is very uncertain, the event will happen "50 to 50". It is difficult to call such an answer satisfactory, it is not very informative.
Formula
after substituting the values of F –1 (0.9) = 1.65 (see the Laplace table), then ( F –1 (0.9)) 2 = 2.7, p = 0.4, ε = 0.05 gives N = 0.4 · 0.6 · 2.7 / 0.05 2 or finally N = 250.
That is, our experiment and its answer is unreliable with respect to given Q and ε : 50 experiments are not enough to answer, 250 are required. That is, it is necessary to continue the experiments and conduct 200 more experiments to achieve the required accuracy.
Very important note . The formula uses itself recursively. It is not possible to immediately calculate the number of experiments with it. To calculate n , it is necessary to conduct a test series of experiments, estimate the value of the desired statistical characteristic p , substitute this value in the formula, and determine the necessary number of experiments.
For certainty, this procedure should be carried out several times with different values of n obtained successively.
So, in the block of reliability assessment (AML) (see lecture 21), the degree of reliability of statistical experimental data taken from the model is analyzed (taking into account the accuracy of the result Q and ε given by the user) and the number of statistical tests required for this is determined n .
With a large number of experiments n, the frequency of occurrence of an event p , obtained experimentally, tends to the value of the theoretical probability of occurrence of an event P. If the fluctuation of the frequency of occurrence of events relative to the theoretical probability is less than the specified accuracy, then the experimental frequency is accepted as an answer, otherwise the generation of random input actions is continued, and the simulation process is repeated. With a small number of tests, the result may be unreliable. But the more trials, the more accurate the answer, according to the central limit theorem. The number of required experiments n are given for comparison in Table. 34.3 and tab. 34.4 with various combinations of p and ε .
| Table 34.3. The number of experiments n required for calculating a valid response with a trusted probability Q = 0.95, ( F –1 (0.95)) 2 = 3.84, p = 0.1 | ||||||||||||
|
| Table 34.4. The number of experiments n required for calculating a valid response with a trusted probability Q = 0.95, ( F –1 (0.95)) 2 = 3.84, p = 0.5 | ||||||||||||
|
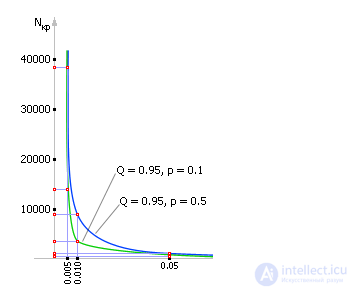
In fig. 34.8 the graph of dependence n ( ε ) is displayed at Q = 0.95 and p = 0.5.
| |
| Fig. 34.8. The dependence of the number of required experiments on the value of the confidence probability ε and the confidence interval Q for the case of a frequent occurrence of a random event p = 0.5 |
Important : evaluation is carried out at the worst of frequencies. This provides a reliable result at once on all the removed characteristics of the model.
Note It should be borne in mind that this estimate of the number of CCT experiments is not the only one existing. There are similar analogous estimates of Bernoulli, Muavre-Laplace, Chebyshev.
How to explain why the curve of the experimentally removed statistical characteristic behaves so strangely (see Fig. 34.7 and Fig. 34.8)? For large n, the curve very slowly approaches the true value, although at first (for small n ) the process proceeds at high speed — we quickly enter the region of an approximate answer (large ε ), but slowly approach the exact answer (small ε ).
For example, suppose we conducted N tests. The fallout of the event in these tests amounted to the number N 1 . Let the probability of occurrence of an event be close to N 1 / N = 0.5 or N = N 1 · 2.
Suppose we want to conduct another test ( N + 1) -e. Taking the answer (frequency N 1 / N ) with N for 100%, let us estimate how much the percentage will change the answer after the next experiment? Make up the proportion:
N 1 / N - 100%
( N 1 + 1) / ( N + 1) - X %
From here we have: X = ( N 1 + 1) · 100 · N / ( N 1 · ( N + 1)), with N 1 = N / 2 (probability 0.5) we get that X = 100 · ( N + 2) / ( N + 1).
And the value of X forms the series: 150%, 133%, 125%, 120%, ..., 100.1%, ..., ... -> 100%. This means that first the improvement in the response to one additional experiment was 50%, by 2 - 33%, by 3 - 25%, by 4 - 20%, ..., by 100% - by only 0.1%.
It can be seen that the accuracy improvement for each new experiment ( X values) is very good at first, and then insignificant, after 100 experiments this value changes only by a fraction of a percent per one additional experiment! The result: a change in the estimate based on the amount, after a series of experiments, ceases to change strongly !!!
Results It is important .

Comments
To leave a comment
System modeling
Terms: System modeling