Lecture
Human needs for the performance of computing systems are constantly growing. One of the possible solutions is the development and application of systems with mass parallelism - clusters, Grid-systems , multiprocessor complexes, systems on multi-core processors.
There is a change of priorities in the development of processors, systems based on them and, accordingly, software. The direction of changing priorities is associated with overcoming three, so-called "walls", when new ones replace the old truths:
- Energy wall . The old truth is that energy is worth nothing, transistors are expensive. New truth - the road is energy, transistors are not worth anything.
- The wall of memory . The old truth is that memory is fast, and floating point operations are slow. New truth - system performance holds memory back, operations are performed quickly.
- Wall concurrency at the command level . The old truth is that productivity can be enhanced by the quality of compilers and architectural improvements such as pipelines, extraordinary command execution, super-long command word (Very Long Instruction Word, VLIW), explicit command parallelism (Explicitly Parallel Instruction Computing, EPIC), and others. New Truth - natural parallelism, commands are valid and long, and short, but they are executed in parallel, on different cores.
One can speak of two noticeably different trends in the process of increasing the number of nuclei. One is called multi-core. In this case, it is assumed that the cores are high-performance and relatively few of them, but according to Moore's law, their number will periodically double. There are two main disadvantages: the first is high energy consumption, the second is the high complexity of the chip and, as a result, the low percentage of the output of finished products. When producing an 8-core IBM Cell processor, only 20% of the crystals produced are usable. The other way is multi - core (many-core). In this case, a larger number of nuclei are assembled on the crystal, but with a simpler structure and consuming power per milliwatt. Now the number of cores varies from 40 to 200, and if Moore's law is fulfilled for them, then we can expect the appearance of processors with thousands and tens of thousands of cores.
The traditional means of improving the performance of processors has always been an increase in clock frequency, but the increase in energy consumption and problems with heat dissipation forced developers to increase the number of cores instead. However, multi-core processors, if it all comes down to placing a larger number of classic simple cores on a single substrate, cannot be taken as a solution to all problems. They are extremely difficult to program, they can be effective only on applications with natural multithreading.
The energy wall, the memory wall and the parallelism wall at the command level are a direct consequence of the von Neumann architecture. Due to technological constraints, John von Neumann chose a scheme based on a controlled flow of commands, a program that selects the data necessary for the teams. This determines the canonical composition of the architectural components that make up any computer — a command counter, an opcode, and operand addresses; It remains unchanged to this day. All conceivable and inconceivable improvements to the von Neumann architecture ultimately boil down to improving the quality of command flow control, data and command addressing methods, memory caching, and so on. At the same time, the consistent architecture does not change, but its complexity increases. It is obvious that the idea of a computer as a device that performs a given sequence of commands is best suited for those cases where the volume of data being processed is small and the data are static. But in modern conditions one has to deal with applications, where a relatively small number of commands processes data streams. In this case, it is advisable to assume that a computer can also be a device that has algorithms somehow embedded in it and is capable of processing data streams. Such computers could have a natural parallelism, and their programming would be reduced to the distribution of functions between a large number of cores.
You can assume the existence of the following alternative schemes. One, von Neumann, assumes that the computational process is controlled by a stream of commands, and the data, mostly static, are selected from some storage systems or from memory. The second scheme is based on the fact that the computation process is controlled by the input data streams that enter the prepared computing infrastructure with natural parallelism at the system input. From the point of view of implementation, the first scheme is much simpler, in addition, it is universal, programs are compiled and written into memory, and the second requires a special assembly of the necessary hardware configuration for a particular task. The second scheme is older; An example of this is the tabulators invented by Hermann Hollerith and successfully used for several decades. IBM has reached its power and has become one of the most influential companies in the United States, producing electromechanical tabs for processing large amounts of information that does not require logical operations. Their programming was carried out by means of switching on the remote control, and then the control device coordinated the work of other devices in accordance with a given program.
The anti-machine differs from the von Neumann machine by the presence of one or more data counters that control data flows. It is programmed using streaming software (Flowware), and the role of the central processor in it is played by one or several data processors (Data Path Unit, DPU). The central part of the anti-machine can be a memory with an automatic sequence (Auto-Sequence Memory) (Fig.1.1).
The asymmetry between the machine and the anti-car is observed in everything, except that the anti-car allows for parallelism of internal cycles, which means that it solves the problem of parallel data processing. In anti-machine access to the memory is provided not by the address of the command or data fragment recorded in the corresponding register, but by means of the universal address generator (Generic Address Generator, GAG). Its advantage is that it allows the transmission of blocks and data streams. At the same time, compilation, through which a specialized system is created for a specific task, is to combine the required number of configured data processors into a common array (Data Process Array, DPA), which runs Flowware algorithms and which can be reconfigurable.
The GAG methodology is inconsistent, and therefore has such advantages as the ability to work with two-dimensional addresses, which provides undeniable advantages when working with video data and when performing parallel calculations. Data counter - an alternative to the command counter in the von Neumann machine; its content is managed by Flowware. For the new methodology, a new name has been invented - twin.paradigm; it reflects the symbiosis of the computational cores of the two classes of both ordinary central processors, built on a von Neumann scheme, and data processors that implement anti-machines.
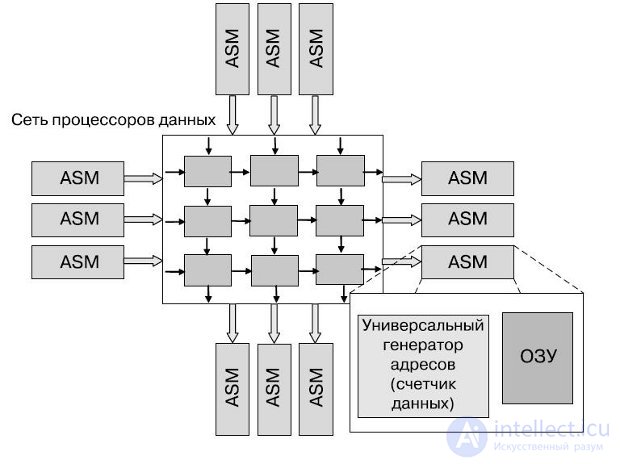
Fig.25.1. Antimachine
The main differences between the anti-machine and the von Neumann machine are that the anti-machine is by its nature parallel and, moreover, non-static — it needs to be programmed individually, and not just download different programs to a universal machine. There are developments that can at least give an idea of how and from what an anti-machine can be assembled. It can be implemented by means of reconfigurable computing.
Theoretically, there are three possible approaches to the creation of reconfigurable processors.
Specialized processors (Application-Specific Standard Processor). Processors that have a set of commands adapted to specific applications.
Configurable Processors (Configurable Processor). A kind of "blanks" to create specialized processors, contain the necessary set of components, adaptable to the requirements of applications. In this case, the design of a specialized processor is easier than from scratch.
Dynamic reconfigurable processors . Processors containing a standard core and a device that expands its capabilities, which can be programmed during execution; this is usually a programmable logic array (Field Programmable Gate-Array, FPGA).
As another way of developing computational tools, combining the transition to parallel systems and processors, and data management, we can call a gradual transition to systems based on or using artificial intelligence. Indeed, if we consider the traditional comparison of the characteristics of artificial intelligence systems with traditional software systems, it is clear that they imply both the adaptability of the structure and the high level of parallelism - thus, there is the potential to make the most of the capabilities of multi-core architectures.
It should also be noted that interest in systems based on artificial intelligence (AI) has increased - this is partly due to the successes in the field of semiconductor technology, allowing to obtain sufficiently compact devices that have enough resources to support AI applications. One of the directions of AI, which is close in structure to parallel systems, is artificial neural networks, which have a number of properties that make them indispensable in many applications. As applied to tasks, this is the ability to generalize, reveal hidden patterns, the ability to tune in to a task, and no need to build analytical models. With regard to the organization of computations, neural networks make the most complete use of the hardware resources of the system (in particular, the most complete load of computational cores is possible for a parallel system).
The widespread introduction of multi-core technologies allows for a new look at the computing capabilities of computers and generates a surge of creative activity in creating innovative solutions. Client application developers can explore new ways to use multitasking, which in the past had no practical meaning or were difficult to implement. For example, important system tasks can now be performed continuously — a continuous and proactive virus scan, automatic backups, ensuring that all work files are saved, an intelligent workflow monitoring system that can predict user needs and provide real-time information on demand. As the proliferation of multicore client PCs grows, the list of useful applications that can run continuously in the background will continue to grow.
There are several classes of applications that require significant computational resources and can be correlated with the term " HPC applications."
Applications processing large data files:
Applications needing increased RAM address space:
Applications working with large masses of transactions / users:
It was shown that multi-core processors can significantly reduce energy consumption while maintaining performance. This, in turn, opens up new areas of application:
Ensuring energy-efficient performance, the foundation of which is the transition to multi-core computing, will bring benefits to virtually all platforms.
As additional computational capabilities appear, developers will see prospects that lie far beyond the simple increase in application performance. Voice control, IP-telephony and video telephony, new electronic secretaries, access to real-time information, enhanced management via IP, multi-level search and data retrieval functions are just a few examples of the benefits that users of powerful computing systems with quick response can get .
Multiprocessor computing systems ( MAS ) can exist in various configurations. The most common types of AIM are:
Note that the boundaries between these types of AIM are blurred to some extent, and often the system may have such properties or functions that go beyond the listed types. Moreover, when configuring a large system used as a general purpose system, it is necessary to allocate blocks that perform all the listed functions.
MVS are an ideal scheme to increase the reliability of an information and computing system. Thanks to a unified view, individual nodes or components of the MIF can seamlessly replace faulty elements, ensuring continuity and trouble-free operation of even such complex applications as databases .
Disaster-resistant solutions are created based on the spacing of nodes of a multiprocessor system over hundreds of kilometers and providing mechanisms for global data synchronization between such nodes.
MVS for high-performance computing designed for parallel calculations. There are many examples of scientific calculations based on the parallel operation of several low-cost processors, ensuring the simultaneous execution of a large number of operations.
MVS for high performance computing are usually collected from many computers. The development of such systems is a complex process that requires constant coordination of issues such as installation, operation and simultaneous management of a large number of computers, technical requirements for parallel and high-performance access to the same system file (or files), interprocessor communication between nodes and coordination in parallel mode. These problems are most easily solved by providing a single operating system image for the entire cluster. However, to implement such a scheme is not always possible, and usually it is used only for small systems.
Multi-threaded systems are used to provide a single interface to a number of resources that can be arbitrarily increased (or reduced) over time. A typical example would be a group of web servers.
The main distinguishing feature of a multiprocessor computing system is its performance, i.e. the number of operations performed by the system per unit of time. There are peak and real performance . Under peak understand the value equal to the product of the peak performance of one processor on the number of such processors in a given machine. In this case, it is assumed that all devices of the computer are working in the most productive mode. Peak computer performance is unequivocally calculated, and this characteristic is the basic one, according to which high-performance computing systems are compared. The greater the peak performance , the (theoretically) faster the user will be able to solve their problem. Peak performance is a theoretical value and, generally speaking, unattainable when you run a particular application. The actual performance achieved on this application depends on the interaction of the software model in which the application is implemented, with the architectural features of the machine on which the application runs.
There are two ways to evaluate computer peak performance . Один из них опирается на число команд, выполняемых компьютером за единицу времени. Единицей измерения, как правило, является MIPS (Million Instructions Per Second). Производительность, выраженная в MIPS, говорит о скорости выполнения компьютером своих же инструкций. Но, во-первых, заранее не ясно, в какое количество инструкций отобразится конкретная программа, а во-вторых, каждая программа обладает своей спецификой, и число команд от программы к программе может меняться очень сильно. В связи с этим данная характеристика дает лишь самое общее представление о производительности компьютера.
Another way to measure performance is to determine the number of real operations that a computer performs per unit of time. The unit of measurement is Flops (Floating point operations per second) - the number of floating point operations performed by a computer in one second. This method is more acceptable to the user, because he knows the computational complexity of the program, and using this characteristic, the user can get a lower estimate of the time it was run.
However, peak performance is obtained only under ideal conditions, i.e. in the absence of conflicts when accessing memory with a uniform load of all devices. In real conditions, the implementation of a specific program is influenced by such hardware and software features of this computer as: features of the processor structure, instruction set, composition of functional devices, I / O implementation, compiler performance.
One of the determining factors is the time of interaction with memory, which is determined by its structure, volume and architecture of memory access subsystems. In most modern computers, the so-called multi - level hierarchical memory is used as the organization of the most efficient memory access . The levels used are registers and register memory, main memory, cache memory, virtual and hard drives, tape robots. In this case, the following principle of hierarchy formation is maintained: as the memory level rises, the processing speed of the data should increase, and the volume of the memory level should decrease. The efficiency of using this kind of hierarchy is achieved by storing frequently used data in top-level memory, the access time to which is minimal. And since such a memory is quite expensive, its volume cannot be large. The hierarchy of memory refers to those features of computer architecture that are of great importance for increasing their performance.
In order to assess the effectiveness of the computing system on real-world problems, a fixed set of tests was developed . The most famous of these is LINPACK , a program designed to solve a system of linear algebraic equations with a dense matrix with the choice of the main element along the line. LINPACK is used to form the Top500 list - five hundred of the most powerful computers in the world. However, LINPACK has a significant drawback: the program is parallelized, so it is impossible to evaluate the effectiveness of the communication component of the supercomputer.
At present, test programs taken from different subject areas and representing either model or real industrial applications have become widespread . Such tests allow you to evaluate the performance of a computer really on real tasks and get the most complete picture of the efficiency of a computer with a specific application.
Наиболее распространенными тестами, построенными по этому принципу, являются: набор из 24 Ливерморских циклов (The Livermore Fortran Kernels, LFK) и пакет NAS Parallel Benchmarks (NPB), в состав которого входят две группы тестов , отражающих различные стороны реальных программ вычислительной гидродинамики. NAS тесты являются альтернативой LINPACK , поскольку они относительно просты и в то же время содержат значительно больше вычислений, чем, например, LINPACK или LFK.
Чтобы дать более полное представление о многопроцессорных вычислительных системах, помимо высокой производительности необходимо назвать и другие отличительные особенности. Прежде всего, это необычные архитектурные решения, направленные на повышение производительности (работа с векторными операциями, организация быстрого обмена сообщениями между процессорами или организация глобальной памяти в многопроцессорных системах и др.).
Понятие архитектурывысокопроизводительной системы является достаточно широким, поскольку под архитектурой можно понимать и способ параллельной обработки данных , используемый в системе, и организацию памяти , и топологию связи между процессорами, и способ исполнения системой арифметических операций. Попытки систематизировать все множество архитектур впервые были предприняты в конце 60-х годов и продолжаются по сей день.
В 1966 г. М.Флинном (Flynn) был предложен чрезвычайно удобный подход к классификации архитектур вычислительных систем. В его основу было положено понятие потока, под которым понимается последовательность элементов, команд или данных, обрабатываемая процессором. Соответствующая система классификации основана на рассмотрении числа потоков инструкций и потоков данных и описывает четыре архитектурных класса:
SISD = Single Instruction Single Data
MISD = Multiple Instruction Single Data
SIMD = Single Instruction Multiple Data
MIMD = Multiple Instruction Multiple Data
SISD (single instruction stream / single data stream) – одиночный поток команд и одиночный поток данных . К этому классу относятся последовательные компьютерные системы, которые имеют один центральный процессор, способный обрабатывать только один поток последовательно исполняемых инструкций. В настоящее время практически все высокопроизводительные системы имеют более одного центрального процессора, однако каждый из них выполняет несвязанные потоки инструкций , что делает такие системы комплексами SISD-систем, действующих на разных пространствах данных. Для увеличения скорости обработки команд и скорости выполнения арифметических операций может применяться конвейерная обработка . В случае векторных систем векторный The data stream should be treated as a stream of single indivisible vectors. Examples of computers with SISD architecture are most Compaq, Hewlett-Packard, and Sun Microsystems workstations.
MISD (multiple instruction stream / single data stream) - a multiple stream of commands and a single data stream . Theoretically, in this type of machine, many instructions should be executed on a single data stream . Until now, no real machine that falls into this class has been created. As an analogue of the work of such a system, apparently, one can consider the work of a bank. From any terminal you can give a command and do something with the existing data bank. Since the database is one, and there are many commands, we are dealing with a multiple stream of commands and a single data stream .
SIMD (single instruction stream / multiple data stream) - single command stream and multiple data stream . These systems usually have a large number of processors, from 1024 to 16384, which can execute the same instruction for different data in a hard configuration. A single instruction is executed in parallel on many data elements. Examples of SIMD machines are the CPP DAP, Gamma II and Quadrics Apemille systems. Another subclass of SIMD systems is vector computers. Vector computers manipulate arrays of similar data just as scalar machines process individual elements of such arrays. This is done through the use of specially designed vector central processors. . Когда данные обрабатываются посредством векторных модулей, результаты могут быть выданы на один, два или три такта генератора тактовой частоты (такт генератора является основным временным параметром системы). При работе в векторном режиме векторные процессоры обрабатывают данные практически параллельно, что делает их в несколько раз более быстрыми, чем при работе в скалярном режиме. Примерами систем подобного типа являются, например, компьютеры Hitachi S3600.
MIMD (multiple instruction stream / multiple data stream) – множественный поток команд и множественный поток данных . Эти машины параллельно выполняют несколько потоков инструкций над различными потоками данных. Unlike the multi-processor SISD machines mentioned above, the commands and data are related because they represent different parts of the same task. For example, MIMD systems can perform multiple subtasks in parallel in order to reduce the execution time of the main task. The large variety of systems that fall into this class makes Flynn’s classification not fully adequate. Indeed, both the NEC's four-processor SX-5 and the thousand-processor Cray T3E fall into this class. This forces us to use a different classification approach, otherwise describing the classes of computer systems. The basic idea of this approach may consist, for example, in the following. We assume that the plural stream of commandsIt can be processed in two ways: either by a single conveyor processing device operating in the time-sharing mode for individual threads, or each stream is processed by its own device. The first possibility is used in MIMD-computers, which are usually called conveyor or vector ones, the second - in parallel computers . At the core of vector computers is the concept of pipelining, i.e. explicit segmentation of the arithmetic unit into separate parts, each of which performs its own subtask for a pair of operands. The parallel computer is based on the idea of using several processors working together for solving one task, and the processors can be both scalar and vector ones.
Классификация архитектур вычислительных систем нужна для того, чтобы понять особенности работы той или иной архитектуры, но она не является достаточно детальной, чтобы на нее можно было опираться при создании МВС, поэтому следует вводить более детальную классификацию, которая связана с различными архитектурами ЭВМ и с используемым оборудованием.
SMP (symmetric multiprocessing) – симметричная многопроцессорная архитектура . Главной особенностью систем с архитектурой SMP является наличие общей физической памяти , разделяемой всеми процессорами
( рис.25.2).
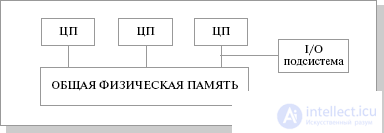
Рис.25.2. Схематический вид SMP архитектуры
The memory serves, in particular, for transmitting messages between processors, while all computing devices when accessing it have equal rights and the same addressing for all memory cells. Therefore, the SMP architecture is called symmetric. The latter circumstance allows you to very efficiently exchange data with other computing devices. The SMP system is built on the basis of a high-speed system bus (SGI PowerPath, Sun Gigaplane, DEC TurboLaser), to the slots of which functional blocks of the following types are connected: processors (CPU), input / output subsystem (I / O), etc. I / O modules use slower buses (PCI, VME64). The most famous SMP systems are SMP servers and workstations based on Intel processors (IBM, HP, Compaq, Dell, ALR, Unisys, DG, Fujitsu, etc.). The whole system runs under a single OS (usually UNIX-like, but for Intel-based platforms supported by Windows NT). The OS automatically (in the process of work) distributes the processes among the processors, but sometimes an explicit binding is also possible.
The main advantages of SMP-systems:
Disadvantages:
This significant drawback of SMP systems does not allow them to be considered really promising. The reason for the poor scalability is that at the moment the bus is able to process only one transaction, resulting in problems of resolving conflicts when several processors simultaneously access the same areas of the total physical memory . Computational elements begin to interfere with each other. When such a conflict occurs, it depends on the connection speed and on the number of computing elements. Currently, conflicts can occur in the presence of 8-24 processors. In addition, the system bus has a limited (albeit high) throughput (PS) and a limited number of slots. All this obviously prevents an increase in performance with an increase in the number of processors and the number of connected users. In real systems, you can use no more than 32 processors. Cluster or NUMA architectures are used to build scalable SMP systems. When working with SMP systems, they use a so-called shared memory paradigm.
MPP (massive parallel processing) is a massively parallel architecture . The main feature of this architecture is that the memory is physically separated. In this case, the system is built from individual modules containing a processor, a local bank of operating memory (RAM), communication processors (routers) or network adapters , sometimes hard drives and / or other input / output devices. In fact, such modules are full-featured computers (Figure 25.3). Only processors (CPUs) from the same module have access to the OP bank from this module. Modules are connected by special communication channels. The user can determine the logical number of the processor to which it is connected, and organize the exchange of messages with other processors. Two variants of operating system (OS) operation on MPP-architecture machines are used. In one, a full-fledged operating system (OS) works only on the controlling machine (front-end), on each separate module there is a heavily trimmed version of the OS, which ensures the operation of only the branch of the parallel application located in it. In the second version, a full-fledged UNIX-like OS runs on each module, installed separately.
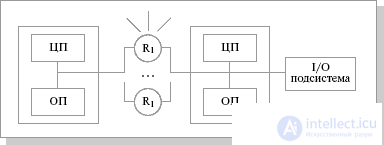
Fig.25.3. Schematic view of shared memory architecture
The main advantage of systems with separate memory is good scalability : in contrast to SMP systems, in machines with separate memory, each processor has access only to its local memory , and therefore there is no need for clockwise synchronization of processors. Practically all performance records for today are set on machines of such an architecture consisting of several thousand processors (ASCI Red, ASCI Blue Pacific).
Disadvantages:
Systems with separate memory are supercomputers MVS-1000, IBM RS / 6000 SP, SGI / CRAY T3E, ASCI systems, Hitachi SR8000, Parsytec systems.
SGI’s latest CRAY T3E series machines, based on Dec Alpha 21164 processors with a peak performance of 1200 MFlops / s (CRAY T3E-1200), can scale up to 2048 processors.
When working with MPP-systems use the so-called Massive Passing Programming Paradigm - the programming paradigm with data transfer (MPI, PVM, BSPlib).
NUMA (nonuniform memory access) - hybrid architecture.
The main feature is non-uniform memory access .
The hybrid architecture combines the advantages of systems with shared memory and the relative cheapness of systems with separate memory. The essence of this architecture is in a special organization of memory, namely: memory is physically distributed across different parts of the system, but logically it is common , so that the user sees a single address space . The system is built from homogeneous base modules (cards) consisting of a small number of processors and a memory block. Modules are integrated using a high-speed switch . A single address space is supported, access to remote memory is supported by hardware, i.e. to the memory of other modules. At the same time, access to local memory is several times faster than to the remote one. Essentially, NUMA is an MPP ( Massively Parallel ) architecture, where SMP (Symmetric Multiprocessor Architecture) nodes are taken as separate computational elements. Memory access and data exchange within one SMP node occurs through the local node memory and is very fast, while the processors of the other SMP node also have access, but slower and through a more complex addressing system.
Block diagram of a computer with a hybrid network: four processors communicate with each other using a crossbar within one SMP node. Nodes are connected by a butterfly network (Figure 25.4).
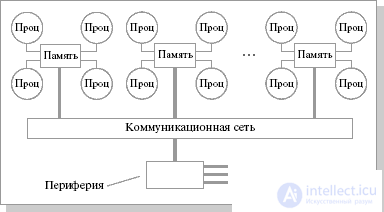
Fig.25.4. Block diagram of a computer with a hybrid network
For the first time, the idea of hybrid architecture was proposed by Steve Volloh, he embodied it in the systems of the Exemplar series. Volloh's variant is a system consisting of eight SMP nodes. HP bought the idea and implemented it on SPP series supercomputers. The idea was picked up by Seymour R.Cray and added a new element - coherent cache, creating the so-called cc-NUMA architecture (Cache Coherent Non-Uniform Memory Access), which stands for " heterogeneous memory access with cache coherence ". He implemented it on systems like Origin.
The concept of coherence caches describes the fact that all CPUs get the same values of the same variables at any time. Indeed, since the cache memory belongs to a single computer, and not to the entire multiprocessor system as a whole, the data falling into the cache of one computer may not be available to another. To avoid this, you should synchronize the information stored in the cache memory of processors.
To ensure the coherence of caches, there are several possibilities:
The most well-known cc-NUMA architecture systems are: HP 9000 V-class in SCA configurations, SGI Origin3000, Sun HPC 15000, IBM / Sequent NUMA-Q 2000. At present, the maximum number of processors in cc-NUMA systems can exceed 1000 (series Origin3000). Usually the whole system runs under the control of a single OS, as in SMP. There are also options for dynamic "divisions" of the system, when individual "partitions" of the system are running under different operating systems. When working with NUMA-systems, as well as with SMP, they use the so-called shared memory paradigm.
PVP (Parallel Vector Process) - parallel architecture with vector processors.
The main feature of PVP systems is the presence of special vector-conveyor processors, in which commands of the same type of processing of independent data vectors are provided that are effectively executed on conveyor-based functional devices . As a rule, several such processors (1-16) work simultaneously with shared memory (similar to SMP) within multiprocessor configurations. Multiple nodes can be combined using a switch (similar to MPP). Since the transfer of data in a vector format is much faster than in a scalar (the maximum speed can be 64 GB / s, which is 2 orders of magnitude faster than in scalar machines), the problem of interaction between data streams during parallelization becomes insignificant. And the fact that badly parallelized on scalar machines, well parallelized on vector ones. Thus, PVP architecture systems can be general purpose systems. However, since vector processors are very expensive, these machines cannot be publicly available.
Three PVP architecture machines are most popular:
The programming paradigm on PVP-systems provides for vectoring of cycles (to achieve reasonable performance of a single processor) and their parallelization (for simultaneous loading of several processors by one application).
In practice, it is recommended to perform the following procedures:
Due to the large physical memory (terabyte share), even poorly vectorized tasks on PVP systems are solved faster than on machines with scalar processors.
1. Changing priorities in the development of processors. Overcoming the three so-called "walls".
2. The generalized structure of anti-cars. The main differences between the anti-car and the von Neumann machine
3. Known approaches to the creation of reconfigurable processors.
4. The most common types of multiprocessor computing systems.
5. Methods for assessing peak computer performance.
6. Classification of computer architectures according to the degree of parallelism of data processing.
7. SMP, MPP and NUMA architectures.
8. PVP architecture.
продолжение следует...
Часть 1 Topic 18. Supercomputers. Parallel computing systems Lecture 25

Comments
To leave a comment
Computer circuitry and computer architecture
Terms: Computer circuitry and computer architecture