Lecture
This chapter examines the possibilities of data recovery after system failures, i.e. Property (D) - durability of transactions.
The main requirement for the longevity of these transactions is that the data of committed transactions must be stored in the system, even if the next time the system fails. It would seem that the easiest way to provide such a guarantee is to record all changes on disk media at once during each operation. This method is not satisfactory, since There is a significant difference in the speed of work with operational and external memory. The only way to achieve acceptable performance is to buffer in-memory database pages. This means that the data fall into the external long-term memory not immediately after making changes, but after some (long enough) time. However, something in the external memory should remain, because otherwise there is no place to get information for recovery.
The requirement of transaction atomicity states that incomplete or rolled back transactions should not leave traces in the database. This means that the data must be stored in a redundant database, which allows you to have information on which the state of the database is restored at the time of the start of a failed transaction. This redundancy is usually provided by the transaction log. The transaction log contains details of all data modification operations in the database, in particular, the old and new values of the modified object, the system transaction number, the modified object, and other information.
Database recovery can be performed in the following cases:
In all three cases, the basis for recovery is data redundancy provided by the transaction log.
Like the database pages, the data from the transaction log is not written directly to disk, but is pre-buffered in RAM. Thus, the system supports two kinds of buffers — database page buffers and transaction log buffers.
Database pages whose contents in the buffer (in RAM) differ from the contents on the disk are called “dirty” pages . The system constantly maintains the list of dirty pages - the dirty list . Writing dirty pages from buffer to disk is called popping pages into external memory . Obviously, it is necessary to provide such rules for pushing out database buffers and transaction log buffers that would provide two requirements:
Thus, there are two reasons for periodically pushing pages into external memory — a lack of RAM and the possibility of failures.
The basic principle of a consistent policy of pushing out a log buffer and database page buffers is that the record about changing a database object must go into the external log memory before the changed object is in the external memory of the database. The corresponding logging protocol (and buffering management) is called Write Ahead Log ( WAL ) - “ write to the log first, ” and if you need to push a modified database object to external memory, you must ensure that the external log is pushed to external memory. records of its change. This means that if there is an object in the external memory of the database to which some modification command has been applied, then the external memory of the transaction log contains a record of this operation. The reverse is not true - if the external memory of the journal contains a record of some change in the object, then the external object itself may not have the changed object in the external memory.
An additional condition for ejecting buffers is imposed by the requirement that every successfully completed transaction must actually be recorded in external memory. Whatever failure occurs, the system must be able to restore the state of the database containing the results of all transactions recorded at the time of the failure.
The third condition for ejecting buffers is that the database and transaction log buffers are limited. Periodically or upon the occurrence of a certain event (for example, the number of pages in the dirty list exceeded a certain threshold, or the number of free pages in the buffer decreased and reached a critical value), the system receives a so-called control point . Accepting a checkpoint includes pushing the contents of the database buffers to an external memory and a special physical record of the checkpoint , which is a list of all the transactions currently being performed.
It turns out that the minimum requirement to guarantee the possibility of restoring the last consistent state of the database is to push all transactions to change the database when the transaction is committed to the external log memory . In this case, the last entry in the log, produced on behalf of this transaction, is a special record of the end of this transaction.
In order to be able to perform an individual transaction rollback on the transaction log, all entries in the log from this transaction are linked to the reverse list. The beginning of the list for non-expiring transactions is the record of the latest database change made by this transaction. For completed transactions (individual rollbacks of which are no longer possible), the beginning of the list is the record of the end of the transaction, which is necessarily pushed into the external log memory. The end of the list is always the first record of a database change made by this transaction. Each record has a unique transaction system number so that you can restore a direct list of database change records for a given transaction.
Individual transaction rollback is performed as follows:
Despite the WAL protocol, after a soft failure, not all physical database pages contain modified data, because Not all dirty database pages have been pushed into external memory.
The last moment when the dirty pages were pushed out guaranteed is the moment of the last checkpoint. There are 5 options for the status of transactions in relation to the time of the last checkpoint and the time of failure:
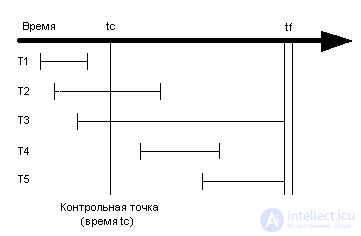
Figure 1 Five Transaction Options
The last test point was taken at time tc. A mild system crash occurred at time tf. T1-T5 transactions are characterized by the following properties:
System recovery after a mild failure is performed as part of the system reboot procedure . When the system is rebooted, transactions T2 and T4 must be partially or completely repeated, transaction T3 - partially rolled back, and no actions need to be taken for transactions T1 and T5. When rebooting, the system performs the following actions:
In case of a hard failure, the database on the disk is physically broken. The basis for recovery in this case is the transaction log and a backup copy of the database . An archive copy of the database should be created periodically, namely, taking into account the speed of filling the transaction log.
Recovery begins with a reverse copy of the database from an archive copy. It then scans the transaction log to identify all transactions that ended successfully before the failure. (Transactions that ended with a rollback before the occurrence of a failure can be disregarded). After that, the transaction log in the forward direction repeats all successfully completed transactions. At the same time, there is no need to roll back transactions that were interrupted as a result of a failure, since The changes made by these transactions are missing after the database is restored from a backup.
The worst case is when both the database and the transaction log are physically destroyed. In this case, the only thing that can be done is to restore the state of the database at the time of the last backup. In order to prevent such a situation from occurring, the database and transaction log are usually located on physically different disks managed by physically different controllers.
The SQL language standard does not contain data recovery requirements, leaving these questions to the discretion of database developers.
The main requirement for the longevity of these transactions is that the data of committed transactions must be stored in the system, even if the next time the system fails. The redundancy of data storage, allowing to recover the system after a failure, is usually provided by the transaction log .
Database recovery can be performed in the following cases:
Pages of the database and transaction log are not written directly to disk, but previously buffered in RAM. Database pages whose contents in the buffer are different from those on disk are called dirty pages . Writing dirty pages from buffer to disk is called popping pages into external memory .
The basic principle of a consistent policy of pushing out a log buffer and database page buffers is the Write Ahead Log ( WAL ) logging protocol — write to a log first .
The minimum requirement to ensure that the last consistent state of the database can be restored is to push all records of database changes by this transaction while committing a transaction to the external log memory .
Individual transaction rollback is performed using the transaction log.
System recovery after a mild failure is performed as part of the system reboot procedure . When the system is rebooted, the transactions go through an identification procedure to identify completed and interrupted transactions as a result of a failure. Transactions that successfully completed before the occurrence of a failure, and data about which are missing in the database, are repeated again. Transactions that did not have time to complete by the time of the failure, and data about which are available in the database, are rolled back.
System recovery after a hard failure is performed using a backup copy of the database and transaction log.

Comments
To leave a comment
Databases, knowledge and data warehousing. Big data, DBMS and SQL and noSQL
Terms: Databases, knowledge and data warehousing. Big data, DBMS and SQL and noSQL