Lecture
This section discusses some issues related to the physical storage of data on external direct access storage devices, that is, primarily on disk storage devices, and access to stored data when performing user information requests.
Earlier in section 3, a three-tier architecture of systems with databases was considered. As mentioned above, one of the reasons for the introduction of several levels of data presentation is to ensure the independence of application software systems from specific structures and ways of organizing data when stored on physical media. Such independence allows the development of application information systems to use higher-level and abstract forms (models) of data representation, as close as possible to the concepts of the domain being modeled. This makes it possible to significantly simplify the process of creating complex information systems without loading it with the need to operate with details related to the presentation of data at lower, including physical, levels.
However, in practice, unfortunately, it is not possible to ensure complete independence and isolation of various levels of data presentation in the design of applied information systems. One of the main reasons is the requirement to ensure that the application’s access to the stored data is efficient from the point of view of minimizing access time. The choice of the solutions that are most effective from the point of view of query execution time assumes knowledge of the features of the implementation of the processes implementing them that occur in subsystems that represent lower levels of the information system architecture.
For example, when using the SQL language for working with data, the same result can be obtained using various equivalent query forms. Actual execution time of these requests may vary significantly, especially with a large amount of processed data. In this regard, to select the most effective option, a competent developer already at the stage of forming a SQL query should understand what sequence of algebraic operations a particular query will be converted to, when executed by the DBMS subsystem, and what actions may be required from the disk subsystem to physically access the requested data on a specific medium.
The need for increased attention to the structures of stored data and methods of access to them is due to the fact that the real time of access to data in disk storage systems is substantially longer than the time of access to data placed in the computer’s main memory.
Consider the basic principles used to store relationships on disk storage devices, and methods for organizing access to stored data.
Figure 11.1 shows the scheme of interaction between the DBMS and other subsystems participating in the processes of access to the stored data.
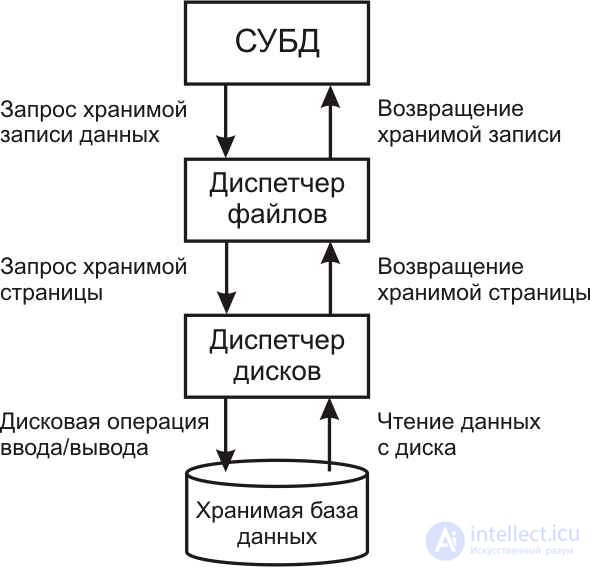
Fig.11.1. The scheme of interaction between the DBMS, the file manager and the disk manager when accessing the stored data
Schematically, from a DBMS point of view, database relationships look like a collection of file records. Typically, file writes are relationship tuples. Each record has a unique system identifier (RowID), which does not change throughout the life of the record. These entries can be viewed using the file manager. When performing a query to the data, the DBMS accesses the file system, which is a component of the operating system and provides access to the corresponding records of the files. In turn, from the point of view of the file system, the database stored in external memory and read into RAM looks like a set of data pages. The fact is that modern storage devices function in such a way that the minimum “portion” of data in an I / O operation is a page containing a certain fixed number of records.
Usually each card is stored in external memory entirely on one page. From here there is, by the way, a limitation in the DBMS on the maximum length of the tuple. As a rule, tuples of the same relationship are stored in one page, although solutions are possible when tuples of different logically related relationships are placed on the same page (see below for data clustering).
Actually data pages can be placed on disks or duplicated (cached) in RAM. The file manager determines the page where the record is located, and makes a request to access the corresponding page of stored data to the disk manager subsystem.
Disk Manager performs all disk I / O operations. It works directly with data stored on disks — it determines the physical location of the page you are looking for on disk media (cylinders, tracks, sectors) and provides appropriate hardware control to implement the data input / output process of a particular page.
In this multi-step procedure for accessing stored data, the most slow are the operations of direct reading / writing data on physical media, since they are associated with mechanical operations of positioning the read / write heads on the corresponding cylinders, tracks and sectors of the disk subsystem. During the real work of information systems with databases in queries to data usually appear not one, but many data records. Therefore, a significant impact on the time of access to such a set of data has how close to each other they are located on a physical medium, whether they are located in one or in different physical pages. The time spent by the disk subsystem for positioning the read / write heads during the transition from one record to another significantly depends on these factors.
In connection with the above, one should mention one of the methods used in industrial DBMS to increase the speed of access to stored data, known as data clustering. The idea of data clustering is to store logically related database records on physical media in such a way as to minimize the time required to move the read / write heads when moving from one record to another. This can be considered as intra-file clustering, when it comes to records of one relational database table, and cross-file clustering, when, for example, records of several tables linked with foreign keys are placed on one page in close proximity.
It is obvious that the physical placement of database records in accordance with their logical relationship in order to minimize data access time in practice is not always feasible. Especially when it comes to data that is dynamically changing over time. In addition, when searching for data on any conditions relating to attribute values, the requirements for optimal placement of table entries for different attributes may turn out to be (and, as a rule, turn out) contradictory. For example, it is not possible to sort the table entries in alphabetical order simultaneously by two or more attributes.
An effective method of increasing the speed of access to data without using their physical ordering and close placement on disk media is indexing.
Consider as an example a table with data about students and a request to select all students from a certain city N. If you do not use any special tricks, and if the relationship records are not ordered in accordance with the alphabetical order of the City field values, then to solve this problem all the records in the table should be reviewed and those from which the City attribute values are equal to those specified in the selection condition should be selected. value of " N ". At the same time, the actual number of selected records can be significantly less than the total number of records viewed when the query is executed.
The implementation of the described task can be significantly accelerated by creating, as shown in Fig. 11.2, an additional data structure, the so-called city index file , or simply an index ( index ). This file contains all the values of the file field corresponding to the City Student table, but already physically ordered alphabetically, with pointers to the corresponding entries in the Student table file. The search for the desired city in the index file can be carried out significantly faster than in the source table. Firstly, because of the arrangement of city names in alphabetical order, due to which there is no need to look through every single file entry. Secondly, the physical dimensions of the index file are substantially smaller than the Student's table file, it requires less physical pages to be placed, so reading it from the disk will be much faster.
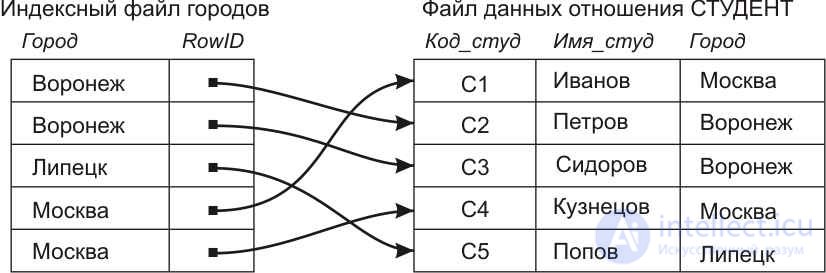
Fig.11.2. Using indexing to speed access to STUDENT relationship records
The indices shown in Figure 11.2 are sometimes referred to as inverted lists . If a regular relation file is a list of tuple pointers with the values of the corresponding fields, then the index file is a list of ordered attribute values with pointers of the corresponding tuple records.
For a single file representing a database relation, several index files for its various fields can be formed simultaneously. For example, for the one shown in Figure 11.2. file STUDENT can be formed index files for the fields COD_DESTER and NAME_STUD. Moreover, an index file can be generated by a composite attribute, that is, by a combination of fields. The combined index by the CITY field and the NAME_STUD field will be a list of pairs of values of these attributes, ordered by city values, and for identical values of the CITY field, by student names.
The disadvantage discussed above and presented in Fig. 11.2 of the index structure is that the effectiveness of such an index will fall with an increase in the number of records of the indexed file. In particular, due to the fact that the size of the index file will also increase and, in the end, will occupy not one, but a larger number of pages. In this regard, at present, to build index files, a more complex, but more efficient hierarchical structure of the B-tree ( B - tree ) type (“B” from the English binary ) is used.
The reason for using the B-tree type for indexing hierarchical structures is to avoid looking for all the pages of the index file according to its physical structure when searching for them. This can be achieved by creating the next level index already for the pages of the index file itself. As we know, data pages are always read from the disk into the RAM as a whole and, although we still have to consistently view the records inside the loaded page in RAM, this will be much faster than when searching for the necessary records on the disk. Obviously, the next level index will contain much fewer records than the first level index, which also helps to speed up the search. Such a second-level index is called a loose index, as opposed to a dense index, in which the number of records is equal to the number of records of the file being indexed.
The considered idea can be developed further in the direction of creating a multi-level tree-like index structure. An example of such a structure, called the B-tree, is shown in Figure 11.3.
From the point of view of the external logical representation, the B-tree is a balanced, highly branched tree in external memory. Balance means that the length of the path from the root of the tree to any leaf is the same. Tree branching is a property of each tree node to refer to a large number of descendant nodes. The physical organization of a ‑ tree is represented as a multi-list structure of external memory pages, that is, each tree node corresponds to an external memory page.
The index based on the B-tree consists of two parts. The first is a set of pages with sequences of values (keys) with pointers to records of an indexed file with real data (bottom row in Figure 13.3). The second is a set of loose indexes that provide quick access to the pages of a set of sequences. The combination of a sequence set and a set of indices is called a B-plus tree, or B + -tree.
At the topmost level of the B + tree there is a single element, the so-called root ( root ) page, and at the bottom of the tree a set of sequences indicating the records of the file being indexed, which are the “leaves” of the tree.
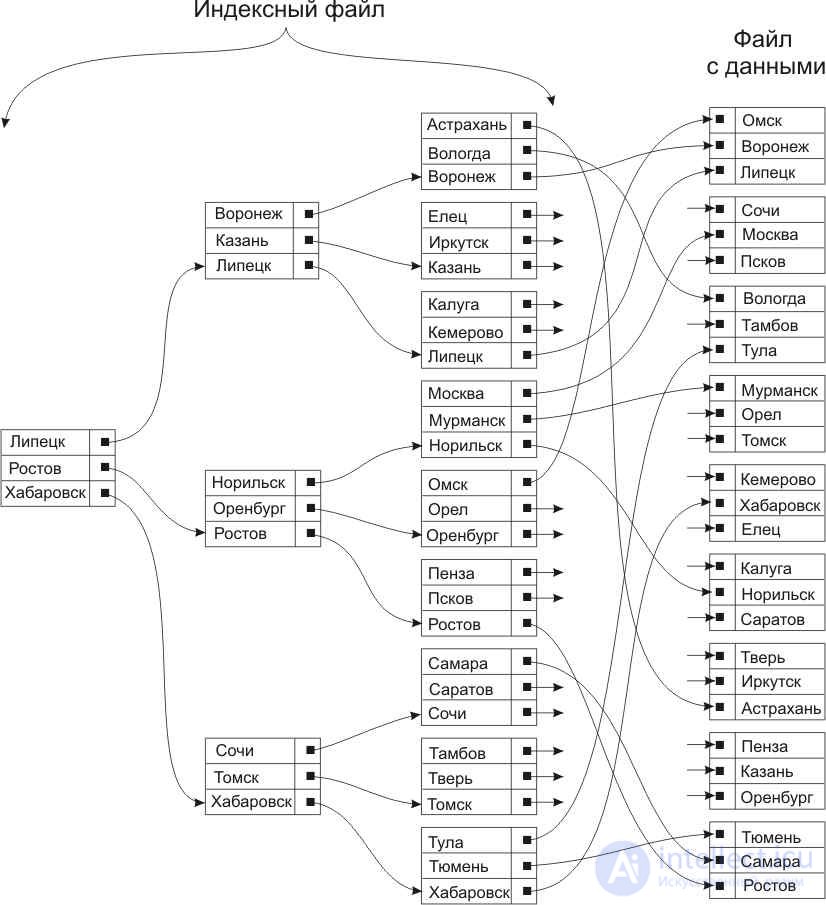
Fig.11.3. An example of an index structure of type B -tree
Consider, for example, how to search for a record of an indexed file, for which the field to be indexed is Moscow. Comparing this value with the values of the key root page of the index structure leads by the pointer to the second page of the next tree level (since Moscow is alphabetically located below Lipetsk, but higher than Rostov). Comparison of the sought value with the key values of the second page of the middle level leads by the pointer to the fourth page of the lower (leafy) level of the tree (Moscow alphabetically above Norilsk), in which the pointer to the corresponding record of the data file being indexed is located.
One of the drawbacks of conventional hierarchical tree structures is a violation of their balance after the operations of deleting and inserting tree elements. However, the advantage of B + -trees is that it is quite simply possible to automatically maintain the balance of the tree, that is, to maintain a more or less uniform filling of the pages of the index structure and the same path length from root to leaf of the tree to search for any values regardless of their location in the data file.
Consider the B-tree restructuring algorithm when inserting a new record into the file being indexed.
The B-tree searches for a leaf page that corresponds to the new value of the entry being entered. If the B- tree does not even contain a key with the specified value, then there is the page number in which it should contain the coordinates of this value inside the page.
Sheet page, in which you want to write, is read into the buffer memory. The operation of inserting a record is performed in this buffer, and its size must exceed the size of the external memory page.
If after inserting the record into the buffer, the size of the used part of the buffer does not exceed the size of the page, then this completes the insert write operation. The buffer can be either immediately unloaded into external memory, or temporarily stored in RAM, depending on the buffer management policy.
If a buffer overflow occurs (i.e., the size of its usable part has exceeded the page size), the page is split. For this, a new external memory page is requested, the used part of the buffer is split in half and the second half is written to the newly allocated page, and the old page size is modified by the amount of free memory. Naturally, the links on the list of leaf pages are modified.
To provide access from the root of the tree to the newly opened page, it is necessary to modify the inner page of the B- tree, which is the ancestor of the previously existing (split) leaf page, ie, insert the corresponding key value and the link to the new page. When performing this action, which is also carried out in the memory buffer, the internal page can now overflow again, and it will be split into two. As a result, you will need to insert a new key value and a link to a new page into the inner ancestor page up the tree hierarchy, etc.
The limiting case is the overflow of the root page of the B-tree. This page is also split into two, and a new root page of the tree is started, i.e. its depth is increased by one.
When deleting a record, the following actions are performed.
Search for an entry in the leaf page by key value. If the entry is not found, then nothing is deleted.
If a record is found, then its corresponding leaf page is read into the memory buffer. The buffer is used to actually delete the record.
If, after performing this sub-operation, the size of the area occupied by the buffer is such that its sum with the size of the occupied area in the leaf pages that are the left or right “brother” of this page is larger than the page size, the operation is completed.
Если эта сумма оказывается меньше размера страницы, то производится слияние данной страницы с ее левым или правым «братом», т. е. в буфере формируется образ новой страницы, содержащей общую информацию из данной страницы и ее левого или правого «брата». The leaf page that has become unnecessary is entered into the list of free pages. При этом соответствующим образом корректируется список листовых страниц.
Чтобы устранить возможность доступа от корня к освобожденной странице, нужно удалить соответствующее ключевое значение и ссылку на освобожденную страницу из внутренней страницы В-дерева, являющейся предком освобожденной страницы. При этом из-за уменьшения занятой области этой страницы-предка может возникнуть потребность в ее слиянии уже с левым или правым ее «братьями» и т. д.
The limiting case is the complete emptying of the root page of the tree, which is possible after the merging of the last two descendants of the root. В этом случае корневая страница освобождается.
Как видно из вышеизложенного, при выполнении операций вставки и удаления свойствосбалансированности В-дерева сохраняется, а внешняя память расходуется достаточно экономно, обеспечивая среднее заполнение страниц больше чем наполовину.
Говоря о повышении скорости доступа к данным при использовании индексирования полей, следует иметь в виду, что индексирование повышает эффективность именно операции выборки , т. е. чтения данных. Если же выполняется операция, связанная с изменением данных, т. е. вставка или удаление кортежа, изменение значения атрибута, по которому построен индексный файл, то наличие индексации приводит к замедлению операции . Дело в том, что каждое такое изменение приводит к необходимости соответствующей перестройки индексных файлов, относящихся к модифицируемым полям, что, очевидно, требует дополнительного времени.

Comments
To leave a comment
Databases, knowledge and data warehousing. Big data, DBMS and SQL and noSQL
Terms: Databases, knowledge and data warehousing. Big data, DBMS and SQL and noSQL