Lecture
Denormalization (eng. Denormalization) - deliberate reduction of the database structure to a state that does not meet the criteria for normalization, usually carried out in order to speed up read operations from the database by adding redundant data.
The elimination of data anomalies in accordance with the theory of relational databases requires that any database be normalized, that is, meet the requirements of normal forms. Compliance with the requirements of normalization minimizes data redundancy in the database and ensures the absence of many kinds of logical errors in updating and retrieving data.
However, when querying large amounts of data, the operation of connecting normalized relations is performed unacceptably long. As a result, in situations where the performance of such queries cannot be improved by other means, denormalization can be carried out - the composition of several relations (tables) into one, which, as a rule, is in the second, but not in the third normal form. The new relationship is actually the stored result of the join operation of the original relationship.
Due to this redesign, the join operation during the sampling becomes unnecessary and the sampling queries that previously required the connection are faster.
It should be remembered that denormalization is always performed by increasing the risk of data integrity problems during modification operations. Therefore, denormalization should be carried out as a last resort if other measures to increase productivity are impossible. Ideally, a denormalized database is used only for reading.
In addition, it should be noted that the acceleration of some requests for a denormalized database may be accompanied by a slowdown of other requests that were previously performed separately on normalized relations.
There are two main approaches for data denormalization:
Suppose we have tables of this structure:
users
id
name
city_id
cities
id
title
country
+ + | users | + + | id | | name | | city_id | + + + + | cities | + + | id | | title | | country | + ++ + | users | + + | id | | name | | city_id | + + + + | cities | + + | id | | title | | country | + ++ + | users | + + | id | | name | | city_id | + + + + | cities | + + | id | | title | | country | + ++ + | users | + + | id | | name | | city_id | + + + + | cities | + + | id | | title | | country | + ++ + | users | + + | id | | name | | city_id | + + + + | cities | + + | id | | title | | country | + ++ + | users | + + | id | | name | | city_id | + + + + | cities | + + | id | | title | | country | + ++ + | users | + + | id | | name | | city_id | + + + + | cities | + + | id | | title | | country | + ++ + | users | + + | id | | name | | city_id | + + + + | cities | + + | id | | title | | country | + ++ + | users | + + | id | | name | | city_id | + + + + | cities | + + | id | | title | | country | + ++ + | users | + + | id | | name | | city_id | + + + + | cities | + + | id | | title | | country | + +
Inserting a new user will look like this:
To select the name of the city or country of the user, we will need to make two queries or one JOIN:
SELECT * FROM users u JOIN cities c ON (c.id = u.city_id)
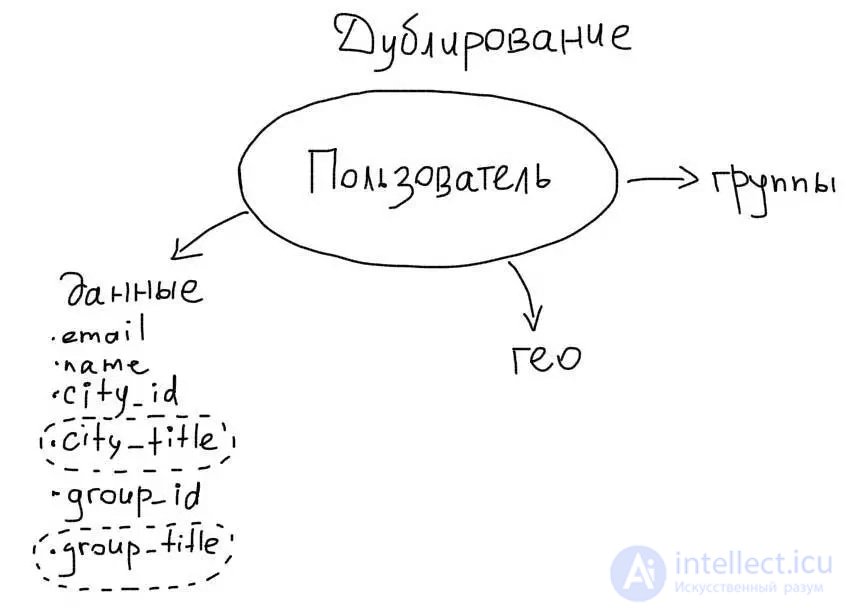
In order to take advantage of the duplication, we need to add the city_title column to the users table:
users
id
name
city_id
city_title
During the insertion of the user, in this column you will need to save the name of the city. Now the insertion of a new user will look like this:
$city = mysql_fetch_assoc( mysql_query('SELECT * FROM cities WHERE id = ' . $city_id) ); mysql_query('INSERT INTO users SET name = "' . $name . '", city_id = ' . $city_id . ', city_title="' . $city['title'] . '" ');
As a result, we will be able to select user data immediately with the name of the city in one simple request:
SELECT id, name, city_title FROM users
One-to-many links One-to-many relationships can also be optimized using duplication. Let's take as an example the table of posts with tags in the blog:
posts
id
title
body
tags
id
title
post_tags
post_id
tag_id
+ +
| posts |
+ +
| id |
| title |
| body |
+ +
+ +
| tags |
+ +
| id |
| title |
+ +
+ +
| post_tags |
+ +
| post_id |
| tag_id |
+ +
To select post labels, we need to make two separate queries (or one JOIN):
SELECT * FROM tags t JOIN post_tags pt ON (pt.tag_id = t.id) WHERE pt.post_id = 1;
Instead, we could save the list of tags in a separate text column, separated by commas:
posts
id
title
body
tags
Then, when displaying posts, there will be no need to make additional requests to get a list of tags.
2. Preliminary data preparation Aggregate requests are usually the most severe. For example, getting the number of records on a specific condition:
SELECT count(*) FROM users WHERE group_id = 17
In addition to duplicating data from one table to another, you can also save data that is calculated. Then it will be possible to avoid heavy aggregate samples. 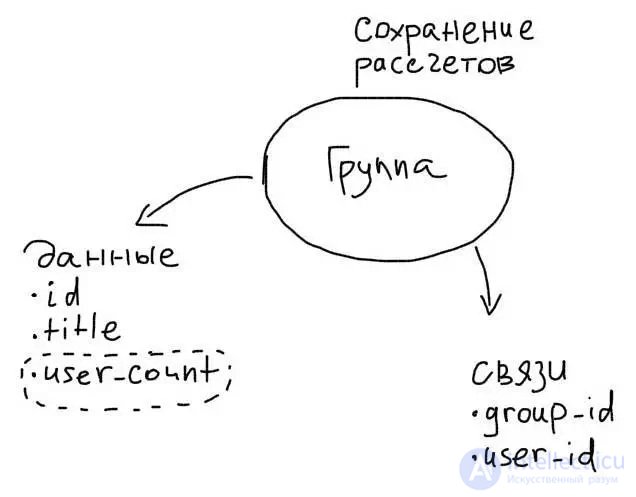
For example, to store the number of users in a group, you need to add an extra column:
groups
id
title
user_count
Then, each time a user is added, it will be necessary to increase the value in the user_count column by 1:
UPDATE groups SET user_count = user_count + 1 WHERE id = 17
Such a data storage scheme is usually called facts + measurements: 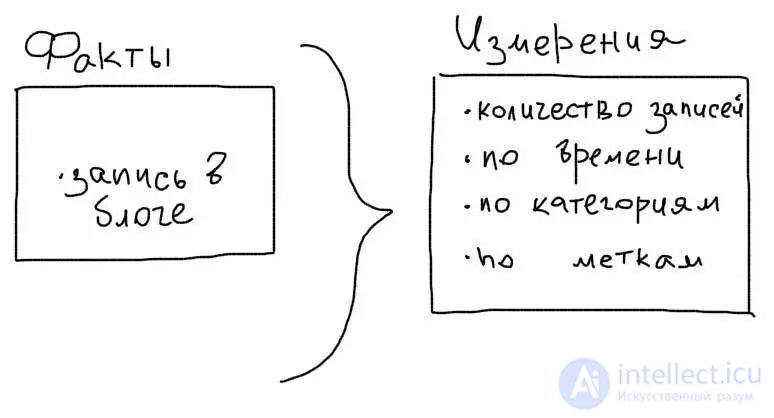
At the same time, we have tables with basic data (facts) and measurement tables, where the calculated data are stored.
Vertical tables The vertical structure uses table rows to store the field names and their values. 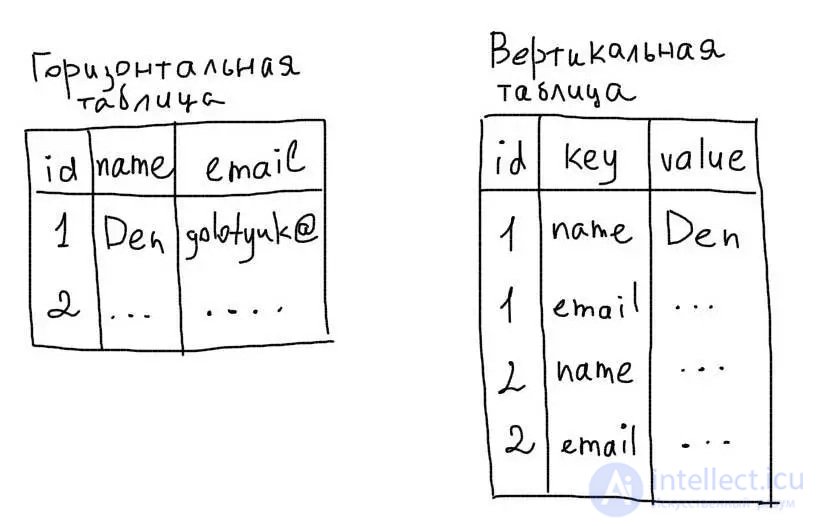
The advantage of storing data in this form is the possibility of convenient sharding. In addition, it will be possible to add new fields without changing the structure of the table. The vertical structure is well suited for tables in which columns can change.
The key structure of the database has a similar structure and advantages.
When is denormalization needed? .
Consider some common situations in which denormalization may be useful.
A large number of table joints.
In queries to a fully normalized database, it is often necessary to connect up to a dozen, if not more, tables. And each connection is a very resource-intensive operation. As a result, such requests consume server resources and are executed slowly.
In such a situation can help:
denormalization by reducing the number of tables. It is better to combine several tables with small size, containing rarely changeable (as they often say, conditionally constant, or reference data) information, and information that is closely related to each other.
In general, if a large number of queries are required to combine more than five or six tables, you should consider the option of denormalizing the database. Denormalization by entering an additional field in one of the tables. In this case, data redundancy appears, additional actions are required to preserve the integrity of the database.
Calculated values. Frequently, queries are executed slowly and consume a lot of resources, in which some complex calculations are performed, especially when using groupings and aggregate functions (Sum, Max, etc.). Sometimes it makes sense to add to the table 1-2 additional columns containing frequently used (and difficult to calculate) calculated data.
Suppose you need to determine the total cost of each order. To do this, you must first determine the cost of each product (according to the formula "the number of units of the product" * "the price of a unit of product" - a discount). After that it is necessary to group the costs by orders.
Execution of this query is quite complex and, if the database contains information about a large number of orders, it can take a long time. Instead of executing such a request, you can determine its cost at the stage of placing an order and save it in a separate column of the order table. In this case, to obtain the desired result, it suffices to extract the previously calculated values from this column.
Creating a column containing pre-calculated values saves a lot of time when executing a query, but requires timely changes to the data in this column.
Long fields. If we have large tables in the database that contain long fields (Blob, Long, etc.), then we can seriously speed up the execution of queries to such a table if we put long fields into a separate table. We want, for example, to create a catalog of photos in the database, including storing in the blob-fields and the photos themselves (professional quality, high resolution, and the appropriate size). From the point of view of normalization, the following table structure is absolutely correct:
ID photos
Author ID
Camera model id
photo itself (blob-field).
Now let's imagine how long the query will work, counting the number of photos taken by any author ...
The correct solution (although violating the principles of normalization) in such a situation would be to create another table consisting of only two fields - the photo ID and the blob field with the photo itself. Then the samples from the main table (in which there is no longer a huge blob-field) will go instantly, but when we want to see the photo itself - well, let's wait ...
How to determine when denormalization is justified?
Costs and benefits.
One way to determine whether these or other steps are justified is to conduct an analysis in terms of costs and possible benefits. How much will a denormalized data model cost?
Determine the requirements (what we want to achieve) -> determine the data requirements (which must be met) -> find the minimum step that satisfies these requirements -> calculate the cost of implementation -> implement.
Costs include physical aspects, such as disk space, the resources needed to manage this structure, and lost opportunities due to the time delays associated with maintaining this process. For denormalization you have to pay. A denormalized database increases data redundancy, which can improve performance, but will require more effort to control related data. The process of creating applications will be complicated, since the data will be repeated and more difficult to track. In addition, the implementation of referential integrity is not a simple matter - the associated data is divided according to different tables.
Benefits include higher performance when executing a request and the ability to get a faster response. In addition, you can get other benefits, including increased bandwidth, customer satisfaction and productivity, as well as more efficient use of tools from external developers.
Frequency requests and sustainability performance.
For example, 70% of the 1000 requests generated daily by an enterprise are requests of the level of summary rather than detailed data. When using the summary data table, queries are executed in about 6 seconds instead of 4 minutes, i.e. processing time is shorter by 2730 minutes. Even adjusting for those 105 minutes that need to be spent weekly to support summary tables, as a result, it saves 2,625 minutes a week, which fully justifies the creation of a summary table. Over time, it may happen that most of the requests will be addressed not to the summary data, but to the detailed data. The smaller the number of queries that use the summary data table, the easier it is to drop it without affecting other processes.
Other
The criteria listed above are not the only ones that should be considered when deciding whether to take the next step in optimization. There are other factors to consider, including business priorities and end-user needs. Users need to understand how, from a technical point of view, the requirement of users who want all requests to be executed in a few seconds affects the system architecture. The easiest way to achieve this understanding is to outline the costs associated with the creation of such tables and their management.
How to correctly implement denormalization.
Save detailed tables
In order not to limit the database capabilities important to business, it is necessary to adhere to the strategy of coexistence, not replacement, i.e. save detailed tables for in-depth analysis, adding to them denormalized structures. For example, the counter of visits. For business, you need to know the number of visits to the web page. But for the analysis (by periods, by countries ...) we are very likely to need detailed data - a table with information about each visit.
Use triggers
It is possible to denormalize the structure of the database and at the same time continue to take advantage of the normalization, if you use database triggers to preserve the integrity of the information, the identity of duplicate data.
For example, when adding a calculated field to each of the columns on which the calculated field depends, a trigger is called that calls a single stored procedure (this is important!), Which writes the required data into the calculated field. It is only necessary not to miss any of the columns on which the calculated field depends.
Software support
Naroimer, in MySQL version 4.1, there are no triggers or stored procedures at all. Therefore, application developers should take care of ensuring the consistency of data in a denormalized database. By analogy with triggers, there should be one function that updates all fields that depend on the variable field.
Summary
Let's sum up. When denormalizing, it is important to maintain a balance between increasing the speed of the base and increasing the risk of inconsistent data, between making life easier for programmers who write Selects, and complicating the task of those who provide the filling of the base and updating the data. Therefore, it is necessary to carry out denormalization of the base very carefully, very selectively, only where it is impossible to do without it.
If it is impossible to calculate in advance the pros and cons of denormalization, then it is initially necessary to implement a model with normalized tables, and only then, to optimize problem queries, to denormalize.
Denormalization is important to introduce gradually and only for those cases when there are repeated samples of related data from different tables. Remember, duplicating data will increase the number of records, but the number of reads will decrease. Calculated data is also conveniently stored in columns to avoid unnecessary aggregate samples.
In general, to study the database, the programmer should know and be able to use
Database |
|
|---|---|
Concepts |
|
Objects |
|
Keys |
|
SQL |
|
DBMS |
|
Components |
|


Comments
To leave a comment
Databases, knowledge and data warehousing. Big data, DBMS and SQL and noSQL
Terms: Databases, knowledge and data warehousing. Big data, DBMS and SQL and noSQL