ETL is an abbreviation for Extract, Transform, Load. These are enterprise-class systems that are used to generate single directories and load data from several different accounting systems into DWH and EPM.
Probably, the principles of ETL work are well known to most of those interested, but I haven’t found Habré as such the article describing the concept of ETL without being tied to a specific product This was the reason to write a separate text.
I want to make a reservation that the description of the architecture reflects my personal experience with ETL tools and my personal understanding of the “normal” use of ETL - the intermediate layer between the OLTP systems and the OLAP system or corporate repository.
Although, in principle, there are ETL, which can be placed between any systems, it is better to solve the integration between accounting systems with a bunch of MDM and ESB. If you need ETL functionality to integrate two dependent accounting systems, this is a design error that needs to be corrected by reworking these systems.
Why ETL system is needed
The problem, which basically resulted in the need to use ETL solutions, is in the business needs to obtain reliable reporting from the mess that is created in the data of any ERP system.
This mess is always there, it is of two types:
- As random errors that occurred at the level of input, data transfer, or due to bugs;
- Like differences in reference books and data specification between adjacent IT systems.
Moreover, if the first type of mess can be overcome, then the second type for the most part is not an error - controlled differences in the data structure, this is a normal optimization for the goals of a particular system.
Because of this feature, ETL systems should ideally solve not one, but two tasks:
- Bring all the data to a single system of values and detail, simultaneously ensuring their quality and reliability;
- To provide an audit trail when transforming (Transform) data so that after the transformation it was possible to understand from which source data and amounts each line of transformed data was collected.
Remembering these two tasks can be very useful, especially if you are writing the ETL process manually, or doing it using low-availability frameworks that do not have a predefined structure for intermediate tables.
It is easy to miss the second task and have many problems finding the causes of errors in the transformed data.
How the ETL system works
All the main functions of the ETL system fit into the following process:

In terms of data flow, there are several source systems (usually OLTP) and a receiver system (usually OLAP), as well as five stages of conversion between them:
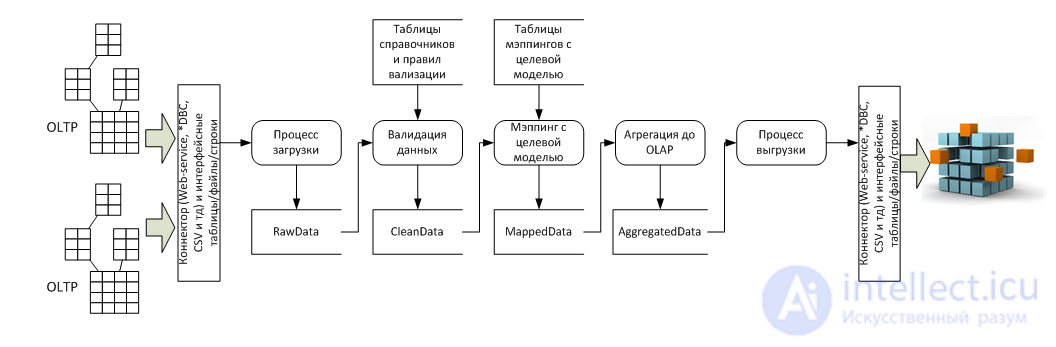
- Loading process - Its task is to tighten data of arbitrary quality in ETL for further processing, at this stage it is important to verify the amounts of incoming lines, if the source system has more lines than in RawData, then - the download went wrong;
- The process of data validation - at this stage, the data are consistently checked for correctness and completeness, an error report is compiled for correction;
- The process of mapping data with the target model - at this stage, n-columns are attached to the validated table by the number of directories of the target data model, and then by the mapping tables in each attached cell, each line contains the values of the target directories. Values can be put as 1: 1, and *: 1, and 1: * and *: *, for setting the last two options, use the formulas and mapping scripts implemented in the ETL tool;
- The process of data aggregation - this process is needed because of the difference in data granularity in OLTP and OLAP systems. OLAP systems are, in fact, a fully denormalized fact table and the reference table tables surrounding it (asterisk / snowflake), the maximum detail of the OLAP amounts is the number of permutations of all elements of all directories. A OLTP system may contain several amounts for the same set of reference elements. It would have been possible to kill the OLTP detailing at the entrance to the ETL, but then we would have lost the “audit trail”. This trace is needed to build a Drill-down report, which shows - from which OLTP lines, the sum was formed in the cell of the OLAP system. Therefore, firstly, a mapping on OLTP details is done, and then in a separate table, the data is “collapsed” for loading into OLAP;
- Uploading to a target system is a technical process of using a connector and transferring data to the target system.
Architecture features
The implementation of processes 4 and 5 from the point of view of architecture is trivial, all the difficulties are technical in nature, but the implementation of processes 1, 2 and 3 requires additional explanation.
Boot process
When designing the data loading process, you need to remember that:
- It is necessary to take into account the business requirements for the duration of the entire process. For example: If data is to be loaded within a week from the moment it is ready in the source systems, and 40 load iterations occur until the normal quality is obtained, the package loading time cannot be longer than 1 hour. ( Moreover, if on average there are no more than 40 downloads, then the loading process cannot be more than 30 minutes, because in half of the cases there will be more than 40 iterations, well, or more precisely, we should consider the probabilities :) ) The main thing is if you do not fit your calculation, Do not rely on a miracle - demolish everything, re-do it. you do not fit;
- The data can be downloaded by the oncoming wave - with a consistent update of data from the same period in the future for several successive periods. ( for example: updating the forecast for the end of the year every month ). Therefore, in addition to the “Period” directory, the “Download period” technical reference must be provided, which will allow you to isolate the data loading processes in different periods and not to lose the history of changing numbers;
- The data tend to be reloaded many times, and it is good if there is a technical version “Version” with at least two elements “Working” and “Final” to separate the cleared data. In addition, the creation of personal versions, one total and one final, allows good control of loading in several streams;
- The data always contains errors: Rebooting the entire package in [50GB -> +8] is not very economical in terms of resources and you most likely do not fit into the schedule, therefore, you need to correctly divide the downloadable file package and design the system so that it allows updating package in small pieces. In my experience, the best way is technical analytics “source file”, and an interface that allows you to pull down all the data from just one file and insert updated ones instead. And it is reasonable to divide the package itself into files by the number of executors responsible for filling them ( either admins of systems preparing unloading or users filling in manually );
- When designing the division of a package into parts, it is necessary to take into account the possibility of the so-called “enrichment” of data ( for example: When last year’s January 12 taxes are considered according to management accounting rules, and in March-April they overload amounts calculated by accounting ), this is solved on the one hand correct design of dividing a data packet into parts so that for enrichment it was necessary to overload an integer number of files ( not 2,345 files ), and on the other hand, the introduction of another technical reference with enrichment periods, which would not lose the change history for these reasons).
Validation process
This process is responsible for identifying errors and gaps in the data transferred to ETL.
The actual programming or customization of the verification formulas does not raise questions, the main question is how to calculate possible types of errors in the data, and by what indicators should they be identified?
The possible types of data errors depend on the type of scale applicable to this data. ( A link to a wonderful post explaining what types of scales exist - http://habrahabr.ru/post/246983/).
Closer to the practice in each of the transmitted data types in 95% of cases the following errors are possible:
| Data types |
Inside the field |
In relation to other fields |
Compatibility of formats for transfer between systems |
| Listing and text |
- Not from the list of allowed values
- No required values
- Non-compliance with the format ( All contracts must be numbered "DGVxxxx .." )
|
- Not from the list of allowed values for a related item
- Missing required items for related item
- Non-compliance with the format for the associated element ( for example: for the product "AIS" all contracts must be numbered "AISxxxx .." )
|
- Characters allowed in one format are not allowed in another
- Encoding
- Backward compatibility ( Directory reference was changed in the target system without adding mapping )
- New values ( no mapping )
- Obsolete values ( not from allowed list on target system )
|
| Numbers and orders |
- Not a number
- Not within the allowed range of values
- The ordinal value is missing ( for example: the data did not reach )
|
- The relation y = ax + b is not fulfilled ( for example: VAT and Revenue, or Counter-sums are equal )
- Element "A" is assigned the wrong sequence number.
- Differences due to different rounding rules ( for example, the calculated VAT never converges in 1C and SAP )
|
- Overflow
- Loss of accuracy and marks
- Incompatibility of formats when converting to a non-number
|
| Dates and periods |
|
- Day of the week does not match the date
- The sum of time units does not correspond due to the difference of working / non-working / holiday / short days
|
- Date format incompatibility when transferring text ( for example: ISO 8601 to UnixTime, or different formats to ISO 8601 )
- Error of the point of reference and accuracy when transmitting by number ( for example: TimeStamp in DateTime )
|
Accordingly, error checks are implemented either by formulas or by scripts in the editor of a specific ETL tool.
And if at all by and large, then most of your validations will be in accordance with reference books, and this is [select * from a where a.field not in (select ...)]
At the same time, in order to preserve the audit trail, it is reasonable to keep two separate tables in the system - rawdata and cleandata with 1: 1 connection support between the rows.
Mapping process
The mapping process is also implemented using the appropriate formulas and scripts, there are three good rules for its design:
- The table of jammed data should include two sets of fields at the same time — old and new analytics, so that you can make a select from the original analytics and see which target analytics are assigned to them, and vice versa:

- The table of locked elements must have a separate PK-field so that when connecting 1: * and *: * you can create many rows in MappedData for one row in CleanData and save the audit trail
- The MappedData table must be separate from CleanData for the same reasons as clause 2.
Conclusion
In principle, these are all architectural techniques that I liked in the ETL tools I used.
In addition, of course, there are also service processes in real systems — authorization, data access control, automated change reconciliation, and all solutions are of course a compromise with performance requirements and the maximum amount of data.

Comments
To leave a comment
Databases, knowledge and data warehousing. Big data, DBMS and SQL and noSQL
Terms: Databases, knowledge and data warehousing. Big data, DBMS and SQL and noSQL