In previous articles, we described the MapReduce paradigm, and also showed how to implement and execute a MapReduce application on the Hadoop stack in practice. It is time to describe the various techniques that allow you to effectively use MapReduce to solve practical problems, and also to show some features of Hadoop, which allow you to simplify the development or significantly speed up the implementation of the MapReduce task on a cluster.
Map only job
As we remember, MapReduce consists of the stages Map, Shuffle and Reduce. As a rule, in practical tasks the Shuffle stage is the hardest, since data is sorted at this stage. In fact, there are a number of tasks in which you can get by with only the Map stage. Here are examples of such tasks:
- Filtering data (for example, “Find all records from the IP address 123.123.123.123” in the web server logs);
- Data conversion (“Delete column in csv-logs”);
- Downloading and uploading data from an external source (“Insert all records from the log into the database”).
Such tasks are solved with the help of Map-Only. When creating a Map-Only task in Hadoop, you need to specify the zero number of reducer'ov:
Configuration example map-only tasks on hadoop:
| Native interface |
Hadoop Streaming Interface |
Specify zero number of reducer when configuring job'a:
job.setNumReduceTasks(0);
A more extensive example of the link. |
We do not specify a reducer and indicate zero number of reducer. Example:
hadoop jar hadoop-streaming.jar \ -D mapred.reduce.tasks=0\ -input input_dir\ -output output_dir\ -mapper "python mapper.py"\ -file "mapper.py"
|
Map Only jobs can actually be very useful. For example, in the Facetz.DCA platform, in order to identify the characteristics of users by their behavior, it is precisely one large map-only that is used, each mapper accepts user input and gives its characteristics to the output.
Combine
As I already wrote, usually the hardest stage when performing a Map-Reduce task is the shuffle stage. This happens because intermediate results (output mapper'a) are recorded on disk, sorted and transmitted over the network. However, there are tasks in which this behavior does not seem very reasonable. For example, in the same task of counting words in documents, you can pre-aggregate the results of the outputs of several mappers on one map-reduce node of the task, and transfer to the reducer the already accumulated values for each machine.
Combine. Taken by reference
In hadoop for this, you can define a combining function that will handle the output of the mapper part. The combining function is very similar to reduce - it accepts the output of a part of the mappers and gives an aggregated result for these mappers, so the reducer is often used as a combiner. An important difference from reduce is that not all values corresponding to the same key fall on the combining function.
Moreover, hadoop does not guarantee that the combining function will be executed at all to exit the mapper. Therefore, the combining function is not always applicable, for example, in the case of searching for a median value by key. Nevertheless, in those tasks where the combining function is applicable, its use allows to achieve a significant increase in the speed of implementation of the MapReduce-task.
Using Combiner on hadoop:
| Native interface |
Hadoop streaming |
When configuring job-a, specify the Combiner class. As a rule, it coincides with Reducer:
job.setMapperClass(TokenizerMapper.class); job.setCombinerClass(IntSumReducer.class); job.setReducerClass(IntSumReducer.class);
|
In the command line parameters specify the command -combiner. As a rule, this command is the same as the reducer command. Example:
hadoop jar hadoop-streaming.jar \ -input input_dir\ -output output_dir\ -mapper "python mapper.py"\ -reducer "python reducer.py"\ -combiner "python reducer.py"\ -file "mapper.py"\ -file "reducer.py"\
|
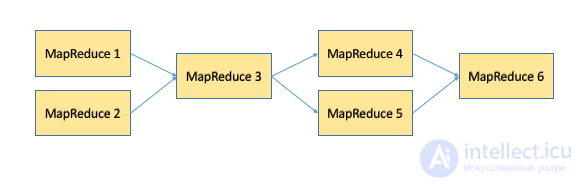
MapReduce task chains
There are situations when MapReduce is indispensable for solving a problem. For example, consider a slightly modified WordCount task: there is a set of text documents, you need to count how many words you meet from 1 to 1000 times in a set, how many words from 1001 to 2000, how many from 2001 to 3000, and so on.
To solve, we need 2 MapReduce jobs:
- Modified wordcount, which for each word will calculate in which of the intervals it fell;
- MapReduce, counting how many times in the output of the first MapReduce met each of the intervals.
Pseudocode solution:
#map1 def map(doc): for word in doc: yield word, 1
|
#reduce1 def reduce(word, values): yield int(sum(values)/1000), 1
|
#map2 def map(doc): interval, cnt = doc.split() yield interval, cnt
|
#reduce2 def reduce(interval, values): yield interval*1000, sum(values)
|
In order to perform a sequence of MapReduce-tasks on hadoop, it is enough just as input to the second task to specify the folder that was specified as the output for the first one and run them in turn.
In practice, chains of MapReduce tasks can be quite complex sequences in which MapReduce tasks can be connected both in series and in parallel with each other. To simplify the management of such plans for performing tasks, there are separate tools like oozie and luigi, to which a separate article in this cycle will be devoted.
An example of a chain of MapReduce-tasks.
Distributed cache
An important mechanism in Hadoop is Distributed Cache. Distributed Cache allows you to add files (for example, text files, archives, jar files) to the environment in which the MapReduce task is performed.
You can add files stored on HDFS, local files (local for the machine from which the task is run). I have already implicitly shown how to use Distributed Cache with hadoop streaming: adding the mapper.py and reducer.py files with the -file option. In fact, you can add not only mapper.py and reducer.py, but arbitrary files in general, and then use them as if they are in a local folder.
Using Distributed Cache:
| Native API |
//конфигурация Job'a JobConf job = new JobConf(); DistributedCache.addCacheFile(new URI("/myapp/lookup.dat#lookup.dat"), job); DistributedCache.addCacheArchive(new URI("/myapp/map.zip", job); DistributedCache.addFileToClassPath(new Path("/myapp/mylib.jar"), job); DistributedCache.addCacheArchive(new URI("/myapp/mytar.tar", job); DistributedCache.addCacheArchive(new URI("/myapp/mytgz.tgz", job); //пример использования в mapper-e: public static class MapClass extends MapReduceBase implements Mapper { private Path[] localArchives; private Path[] localFiles; public void configure(JobConf job) { // получаем кэшированные данные из архивов File f = new File("./map.zip/some/file/in/zip.txt"); } public void map(K key, V value, OutputCollector output, Reporter reporter) throws IOException { // используем данные тут // ... // ... output.collect(k, v); } }
|
| Hadoop streaming |
#перечисляем файлы, которые необходимо добавить в distributed cache в параметре –files. Параметр –files должен идти перед другими параметрами. yarn hadoop-streaming.jar\ -files mapper.py,reducer.py,some_cached_data.txt\ -input '/some/input/path' \ -output '/some/output/path' \ -mapper 'python mapper.py' \ -reducer 'python reducer.py' \ пример использования: import sys #просто читаем файл из локальной папки data = open('some_cached_data.txt').read() for line in sys.stdin() #processing input #use data here
|
Reduce join
Those who are used to working with relational databases often use the very convenient Join operation, which allows them to jointly process the contents of some tables by combining them according to a certain key. When working with big data, this problem also sometimes arises. Consider the following example:
There are logs of two web servers, each log has the following form:
\t\t. Пример кусочка лога:
1446792139 178.78.82.1 /sphingosine/unhurrying.css 1446792139 126.31.163.222 /accentually.js 1446792139 154.164.149.83 /pyroacid/unkemptly.jpg 1446792139 202.27.13.181 /Chawia.js 1446792139 67.123.248.174 /morphographical/dismain.css 1446792139 226.74.123.135 /phanerite.php 1446792139 157.109.106.104 /bisonant.css
Необходимо посчитать для каждого IP-адреса на какой из 2-х серверов он чаще заходил. Результат должен быть представлен в виде:
\t. Пример части результата:
178.78.82.1 first 126.31.163.222 second 154.164.149.83 second 226.74.123.135 first
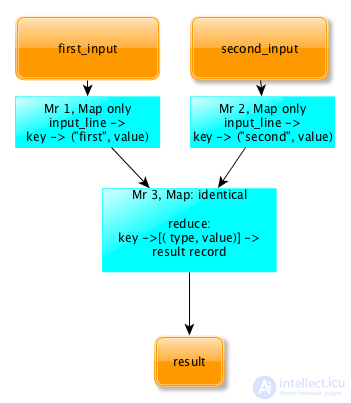
К сожалению, в отличие от реляционных баз данных, в общем случае объединение двух логов по ключу (в данном случае – по IP-адресу) представляет собой достаточно тяжёлую операцию и решается при помощи 3-х MapReduce и паттерна Reduce Join: Общая схема ReduceJoin
ReduceJoin работает следующим образом:
- For each of the input logs, a separate MapReduce (Map only) is launched, which converts the input data to the following form:
key -> (type, value)
Where key is the key by which you want to join the tables, Type is the type of the table (first or second in our case), and Value is any additional data associated with the key.
- The outputs of both MapReduce are fed to the input of the 3rd MapReduce, which, in fact, performs the union. This MapReduce contains an empty Mapper that simply copies the input. Next shuffle lays out the data on the keys and feeds the input to the controller in the form:
key -> [(type, value)]
Важно, что в этот момент на редьюсер попадают записи из обоих логов и при этом по полю type можно идентифицировать, из какого из двух логов попало конкретное значение. Значит данных достаточно, чтобы решить исходную задачу. В нашем случае reducere просто должен посчитать для каждого ключа записей, с каким type встретилось больше и вывести этот type. Mapjoin
Паттерн ReduceJoin описывает общий случай объединения двух логов по ключу. Однако есть частный случай, при котором задачу можно существенно упростить и ускорить. Это случай, при котором один из логов имеет размер существенно меньшего размера, чем другой. Рассмотрим следующую задачу:
Имеются 2 лога. Первый лог содержит лог web-cервера (такой же как в предыдущей задаче), второй файл (размером в 100кб) содержит соответствие URL-> Тематика. Пример 2-го файла:
/toyota.php auto /football/spartak.html sport /cars auto /finances/money business
Для каждого IP-адреса необходимо рассчитать страницы какой категории с данного IP-адреса загружались чаще всего.
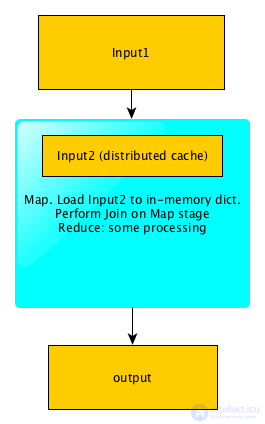
В этом случае нам тоже необходимо выполнить Join 2-х логов по URL. Однако в этом случае нам не обязательно запускать 3 MapReduce, так как второй лог полностью влезет в память. Для того, чтобы решить задачу при помощи 1-го MapReduce, мы можем загрузить второй лог в Distributed Cache, а при инициализации Mapper'a просто считать его в память, положив его в словарь -> topic.
Далее задача решается следующим образом:
Map:
# находим тематику каждой из страниц первого лога input_line -> [ip, topic]
Reduce:
Ip -> [topics] -> [ip, most_popular_topic]
Reduce получает на вход ip и список всех тематик, просто вычисляет, какая из тематик встретилась чаще всего. Таким образом задача решена при помощи 1-го MapReduce, а собственно Join вообще происходит внутри map (поэтому если бы не нужна была дополнительная агрегация по ключу – можно было бы обойтись MapOnly job-ом): Схема работы MapJoin Summary
В статье мы рассмотрели несколько паттернов и приемов решения задач при помощи MapReduce, показали, как объединять MapReduce-задачи в цепочки и join-ить логи по ключу.
В следующих статьях мы более подробно рассмотрим архитектуру Hadoop, а также инструменты, упрощающие работу с MapReduce и позволяющие обойти его недостатки. Links to other articles of the cycle
» Часть 1: Принципы работы с большими данными, парадигма MapReduce
» Часть 2: Hadoop
» Часть 4: Hbase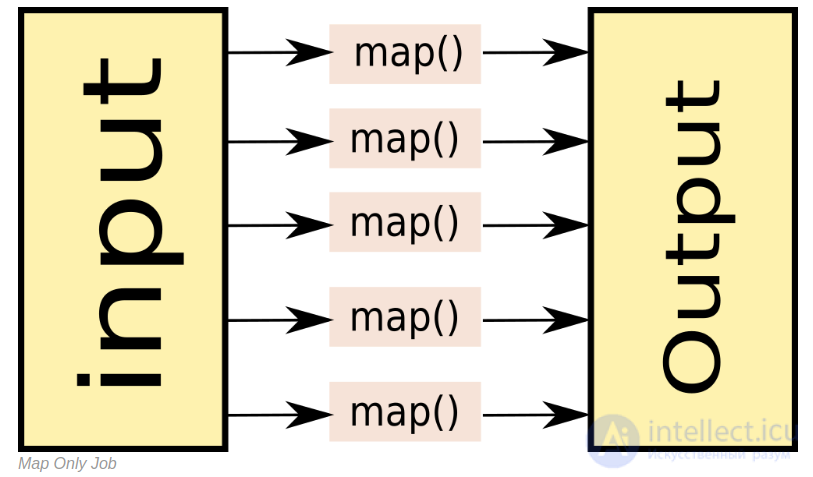


Comments
To leave a comment
Databases, knowledge and data warehousing. Big data, DBMS and SQL and noSQL
Terms: Databases, knowledge and data warehousing. Big data, DBMS and SQL and noSQL