Lecture
After the stage of the infological database design, which actually determines its semantic content in terms of entities , their properties and relationships , the design stage of the datological conceptual data model begins. Now we will speak about the data models themselves, in which the data itself, the structural organization, and the construction rules are the objects of research.
When talking about data models, three interrelated components of a model are usually considered:
When considering different data models, their comparison with each other is usually carried out by the way these three positions are implemented.
This training course focuses on systems based on the relational data model. At present, these systems dominate the market for database systems, almost crowding out systems based on other approaches. Nevertheless, it makes sense to at least briefly consider the features of systems preceding relational ones in order to correctly understand the reasons for the transition to relational systems. In addition, many low-level mechanisms for the functioning of relational databases are based on the use of early approaches. The most well-known of such dorilelation systems are systems based on inverted lists , hierarchical databases, and network databases [1, 4]. Regarding these systems, the following can be noted.
The database structure, organized using inverted lists , is to a certain extent similar to the relational one — the data is stored in the form of tables (Fig. 5.1), but, unlike the relational database, the stored data tables and access paths are visible and accessible to the user. In this case, the rows (records) of the tables are ordered by the system in a certain physical sequence. For each table, you can define an arbitrary number of search keys for which indexes are built. These indexes are automatically maintained by the system, but are clearly visible to users.

Fig. 5.1 Database table based on inverted lists
Manipulation of data. A typical set of operators on addressable entries:

Data structures Ordered data structures are used, organized in the form of “trees” (Fig. 5.2). Such a tree structure consists of one root record and an ordered set of subordinate descendants (tree branches). For the root record, it is necessary to form the key value. Each child record has a link (pointer) to the corresponding parent record, forming a hierarchy of subordination from the lowest level of the records - “tree leaves” - to the top level formed by the root record.
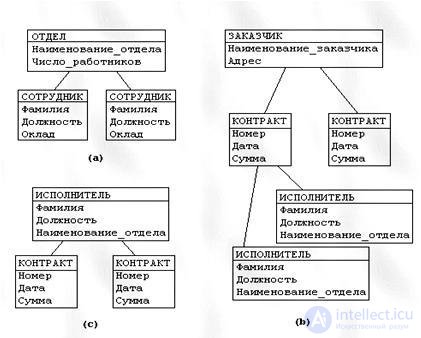
Fig. 5.2 Example of data structure in a hierarchical database
Manipulation of data. Data manipulation operators navigate hierarchical structures using links (pointers) to move from one level to another. Operations on data:
Integrity constraints Of integrity constraints, only the integrity of links between ancestor records and descendant records is automatically maintained (the main rule is that no “descendant” can exist without its “parent”).
A common feature of all early channeling systems is that they are not based on any abstract data models supported by the corresponding mathematical apparatus. Moreover, the very concept of a data model as applied to database systems began to be used precisely with the advent of the relational approach, which was largely born from an analysis of the features, advantages and, to a large extent, disadvantages of the existing data management systems.
In early systems, access to data in the database was carried out directly at the record level. The database navigation, search, selection and recording of data in these systems were carried out by the user using standard procedural programming languages, expanded by the functions of working with the DBMS, requiring the user to understand the low-level features of data storage and the connections between them. The possibility of interactive access to data was realized much more limited only by creating appropriate application software. As already mentioned, early systems had rather weak means of maintaining data integrity.
Low-level means of navigation and data manipulation made it possible, however, in early systems to ensure high efficiency of the implementation of these functions by application programs and the economical use of the memory of the computing system. This can be attributed to the advantages of such systems, especially given the level of computing systems of the time (1960-70s). One of the consequences of the low level of language tools used in these models for working with data was the complexity of creating application software systems and the need to know the features of physical presentation and data storage. Ultimately, this led to greater complexity or even the impossibility of fulfilling a set of requirements for information systems with databases, discussed in previous sections, for example, implementing the requirements of multidimensional data use, ensuring data independence from the logic of the programs using them, etc.

Comments
To leave a comment
Databases, knowledge and data warehousing. Big data, DBMS and SQL and noSQL
Terms: Databases, knowledge and data warehousing. Big data, DBMS and SQL and noSQL