Lecture
For real-time integration, the existing batch method must be replaced with processes that continuously monitor the state of the source systems, capture and transform changes in the data as they occur, and then upload these changes to the Storage; and the closer they are to real time, the better.
Recently, new technologies such as messaging and enterprise application integration (EAI) have provided better opportunities for building active data warehouses and better integrated analytics.
XML and messaging
At the end of the 1990s, companies viewed XML as a universal means for transferring timely transactional data to the Vault. The idea was to provide constant synchronous updates of decision support systems as transactions occur. But, although this concept seemed simple, it has a number of hidden features. First, for each transaction, the transactional system must generate a document in a fixed format, and this can be time consuming. Secondly, documents often become large in scope due to tags and metadata. For example, transactions based on the XMPP (extensible messaging and presence protocol) protocol contain opening and closing tags for each data point.
That is, the record itself contains only 8 characters, and the transmitted document - 55 characters. An even greater amount arises from the description of types, headers, etc. As a result, XML protocols cannot be widely used in very large repositories where millions of transactions arrive per day. However, XML is very useful for sending short messages, as well as in web applications for transferring transactions to a DBMS.
Individual vendors chose a different messaging approach and created interface standards, such as electronic data interchange (EDI), or IDocs, which simplify the formatting and transmission of transactional records. The reduction in overhead associated with the use of these formats allowed companies to automatically transfer records to their newly created Repositories in real time.
Instant messaging for operational reporting in a data warehouse
In 2003, the main contenders for standardizing instant messaging were XMPP and SIMPLE.
As already mentioned, XMPP is convenient for processing short entries, such as SMS traffic. But it causes serious overhead when transferring large volumes of transactions. On the other hand, the disadvantage of its competitor (SIMPLE) is that it provides support for simple text messages, but does not work for other formats. Therefore, each supplier has to develop its own extensions, which in the end turn out to be incompatible. Another problem with the SIMPLE protocol is support for old user data protocols (user data protocol - UDP), as well as TCP protocol at the transmission level. Since UDP does not provide for serious quality control, data packets may be lost, and the ability to resume and control the process is limited. This is very bad for large reporting systems, the quality of which directly depends on timely, accurate and complete data.
Thus, the first versions of SIMPLE were not widely used for real-time data warehouses and reporting systems.
Microsoft becomes an application integration provider
Although a number of problems arise with the SIMPLE protocol, it has nevertheless become a good platform for many suppliers. In 2003, Microsoft developed a project called Real-Time Communication Server, which extends the SIMPLE protocol. And in 2004, a new version of the messaging product, known as BizTalk Server 2004, was launched. It was designed to solve two important goals. First of all, it was supposed to ensure the integration of B2B [1]. Secondly, this product was to become a platform for the integration of enterprise applications, including transactional systems and reporting tools within the organization.
Microsoft has provided a more convenient alternative to the very complex standardization process, which covered several dozen overlapping standards and approaches to EAI. The core architecture of BizTalk Server is a simplified server system. To support decision making in the EAI, Biztalk infrastructure provides Business Activity Services (BAS) installed on the source system to provide messages. In addition, the Warehouse Administrator can monitor the boot process from multiple source systems using the Business Transaction Monitoring Tool (BAM), included with Biztalk.
Biztalk 2004 was a good step forward in EAI. In the process of development, the product was supplemented by network load balancing (network load balancing - NLB) and an enhanced management console (enhanced management console - MMC), designed to remotely control and configure many source systems with the BAS service installed. In 2006, a new version of BizTalk Server 2006 was released, incorporating a number of design changes.
Data warehouses are a relatively new technological solution that was widely used only in the early 90s. The twentieth century, after Bill Inmon, now widely accepted as the “father of the data warehouse concept,” published his first book on the subject (WH Inmon, Building the Data Warehouse, QED / Wiley, 1991). Although some elements of this concept and their technical implementation existed earlier (in fact, from the 70s of the last century), only towards the end of the 80s. the need to integrate corporate information and properly manage it was fully recognized, and technical capabilities appeared for creating the appropriate systems, originally called information repositories, and then, with the release of Inmon's book, which received its current name of “data repository”.
Today, there are two main approaches to the architecture of data warehouses. This is Bill Inmon's so-called Corporate Information Factory (CIF abbreviation) (Fig. 1.7) and Ralph Kimball's data warehouse with bus architecture (Data Warehouse Bus, abbr. BUS) (Fig. 11.8). Let's consider each of them in more detail.
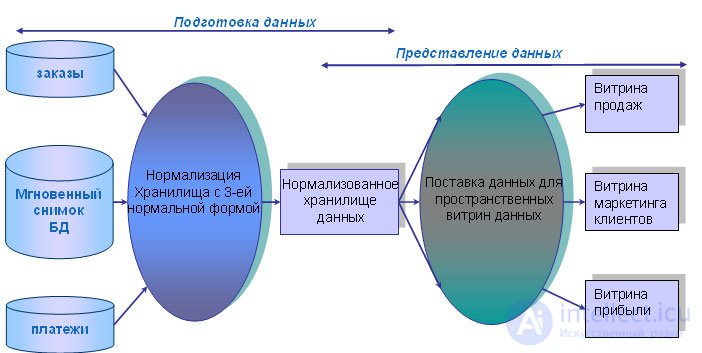
Fig. 11.7. Enterprise Information Factory Architecture
The operation of the storage shown in Fig. 11.7 begins with a coordinated extraction of data from sources. After that, the relational database with the third normal form is loaded, containing atomic data. The resulting normalized storage is used to fill information with additional repositories of presentation data, i.e., data prepared for analysis. These repositories, in particular, include specialized repositories for studying and “mining” data (Data Mining), as well as data marts. Distinctive features of Bill Inmon's approach to the data warehouse architecture are:
In fig. 11.8 is a diagram of a data warehouse with bus architecture.
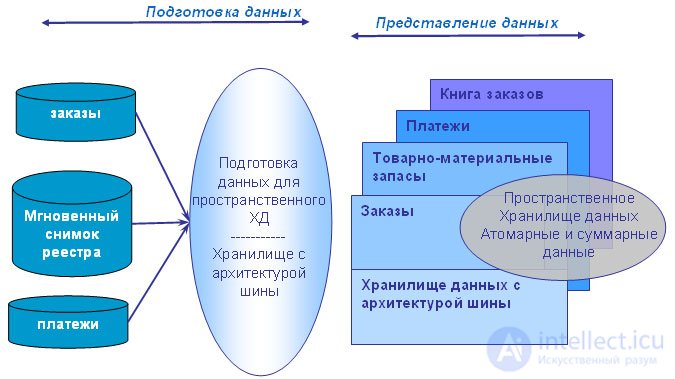
Fig. 11.8. Bus architecture storage
Unlike Bill Inmon's approach, spatial models are built to serve business processes (which, in turn, are related to business metrics or business events), rather than business departments. For example, data on orders that should be available for corporate use is only entered once into the spatial data warehouse, unlike the CIF approach, in which they would have to be copied three times into the data windows of the marketing, sales, and finance departments. After information about the main business processes appears in the repository, consolidated spatial models can provide their cross-sectional characteristics. The corporate data warehouse matrix with bus architecture identifies and enhances the relationship between business process metrics (facts) and descriptive attributes (dimensions).
Summarizing all of the above, we can note the typical features of the Ralph Kimball approach.
The advantages and disadvantages of each approach directly stem from their architectural solutions. It is believed that a spatial organization with a star architecture facilitates access to data and requires less time to complete queries, and also simplifies work with atomic data. On the other hand, proponents of Bill Inmon's approach criticize this scheme for the lack of necessary flexibility and vulnerability of the structure, believing that spatially organized atomic data is more difficult to make the necessary changes.
The relational scheme for organizing atomic data slows down access to data and requires more time to complete queries due to the different organization of atomic and summary data. But on the other hand, this scheme provides ample opportunities for manipulating atomic data and changing their format and presentation method as necessary.

Bill Inmon
Bill Inmon recommends building the data warehouse that follows the top-down approach. In Inmon’s philosophy, it is starting with building a big centralized enterprise data warehouse where all available data from transaction systems are consolidated into a subject-oriented, integrated, time-variant and non-volatile collection of data that supports decision making. then data marts are built for analytic needs of departments.

Ralph Kimball
Contrast to Bill Inmon approach, Ralph Kimball recommends building the data warehouse that follows the bottom-up approach. In Kimball’s philosophy, it first starts with mission-critical data marts that serve analytic needs of departments. Then it is integrating these data marts for data consistency through a so-called information bus. Kimball makes uses of the dimensional model to address the needs of departments in various areas within the enterprise.
Here are the most important criteria how to choose between Kimball vs Inmon approach.
| Characteristics | Kimball | Inmon |
|---|---|---|
| Business decision support requirements | Tactical | Strategic |
| Data integration requirements | Individual business requirements | Enterprise-wide integration |
| The structure of data | KPI, business performance measures, scorecards… | Data that meet multiple and varied information needs and non-metric data |
| Persistence of data in source systems | Source systems are quite stable | Source systems have high rate of change |
| Skill sets | Small team of generalists | Bigger team of specialists |
| Time constraint | Urgent needs for the first data warehouse | Longer time is allowed to meet business’ needs. |
| Cost to build | Low start-up cost | High start-up costs |
In this article, we’ve discussed the Kimball vs Inmon in data warehouse architecture and design approach. In addition, we’ve provided the information that you can choose between Kimball vs Inmon to build your data warehouse.
The basis of analytical data processing based on data warehouses is OLAP technology (online analytical processing, real-time analytical processing) - information processing technology, including the compilation and dynamic publication of reports and documents. This technology is used by analysts to quickly process complex database queries. The reason for using OLAP to process requests is speed. Relational databases store entities in separate tables, which are usually well normalized. This structure is convenient for operational (operational) databases (OLTP systems), but complex multi-table queries in it are performed relatively slowly. A better model for queries, rather than for modification, is a spatial database
Together with the basic concept, there are three types of OLAP:
MOLAP is a classic form of OLAP, so it is often called simply OLAP. It uses a summing database, a special version of the processor of spatial databases and creates the required spatial data scheme with the preservation of both basic data and aggregates. ROLAP works directly with relational storage, facts and dimension tables are stored in relational tables, and additional relational tables are created to store aggregates. HOLAP uses relational tables to store base data and multidimensional tables for aggregates. A special case of ROLAP is Real-time ROLAP (R-ROLAP). Unlike ROLAP, R-ROLAP does not create additional relational tables for storing aggregates, but aggregates are calculated at the time of the request. At the same time, a multidimensional query to the OLAP system is automatically converted to an SQL query to relational data.
At the moment, there are many products that provide the ability to organize data warehousing about OLAP analysis.
One of the problems of processing large amounts of information is data compression technology.
Fractals, these beautiful images of dynamic systems, were previously used in computer graphics mainly for constructing images of the sky, leaves, mountains, grass. A beautiful and, more importantly, reliably imitating a natural object image could be specified with just a few factors. It is not surprising that the idea of using fractals in compression arose earlier, but it was considered almost impossible to construct an appropriate algorithm that would select the coefficients in an acceptable time. So, in 1991, such an algorithm was found. A fractal archiver allows, for example, when unpacking, arbitrarily change the resolution (size) of the image without the appearance of grain effect. Moreover, it decompresses much faster than the closest competitor JPEG, and not only static graphics, but also video.
In fact, fractal compression is a search for self-similar areas in the image and determination of the parameters of affine transformations for them.
For a fractal compression algorithm, as well as for other lossy compression algorithms, the mechanisms by which it is possible to control the compression ratio and the degree of loss are very important. To date, a sufficiently large set of such methods has been developed. Firstly, it is possible to limit the number of transformations by knowingly providing a compression ratio not lower than a fixed value. Secondly, it can be required that in a situation where the difference between the processed fragment and its best approximation is above a certain threshold value, this fragment is necessarily split, and the conversion technology is required for it to start. Thirdly, it is possible to prohibit fragmentation of fragments smaller than, say, four points. By changing the threshold values and the priority of these conditions, you can very flexibly control the compression ratio of the image: from bitwise matching to any compression ratio.

Comments
To leave a comment
Databases, knowledge and data warehousing. Big data, DBMS and SQL and noSQL
Terms: Databases, knowledge and data warehousing. Big data, DBMS and SQL and noSQL