Lecture
When building an ANN model, first of all, it is necessary to accurately determine the tasks that will be solved with its help. It is necessary to exclude from the initial information all information that is not related to the problem under study. At the same time, there should be a sufficient number of examples for teaching ANN. All examples should be divided into two sets: training - on which weights are selected, and validation - on which the predictive capabilities of the network are evaluated. There must also be a third one - a test set that does not affect learning at all and is used only to assess the predictive capabilities of an already trained network.
In practice, it turns out that for good generalization it is enough that the size of the training set N satisfies the following relation:
N = O (W / ε),
where W is the total number of free parameters (ie, synaptic weights and thresholds) of the network; ε is the permissible accuracy of classification errors; O () is the order of the value in brackets. For example, for a 10% error, the number of training examples should be 10 times greater than the number of free network parameters.
1. Encoding inputs and outputs.
ANN is a distributed numeric processor, so a numeric code is needed to represent non-numeric data. For example, letters in words can be encoded in accordance with one of the generally accepted encoding tables, or you can specify your own table.
Two main types of non-numeric variables can be distinguished: ordered (also called ordinal variables from order. Order) and categorical . In both cases, the variable refers to one of a discrete set of classes (c 1 , c 2 , ..., c n ). But in the first case, these classes are ordered - they can be ranked, whereas in the second case there is no such ordering. Comparative categories can be given as an example of ordered variables: bad - good - good, or slow - fast. Categorical variables simply designate one of the classes, they are the names of the categories. For example, it may be the names of people.
2. Data normalization.
The effectiveness of the neural network model increases if the ranges of input and output values are reduced to a certain standard, for example [0,1] or [-1,1]. In addition, the normalized values are dimensionless.
The reduction of data to a single scale is provided by the normalization of each variable over the range of variation of its values. In its simplest form, this is a linear transformation:
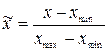
Such a normalization is optimal for a distribution of a quantity close to a uniform one. In the presence of rare emissions, normalization is necessary based on the statistical characteristics of the data:
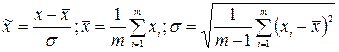
However, now the normalized values do not belong to the guaranteed unit interval, moreover, the maximum spread of values is not known in advance. It may not be important for the input data, but if the output neurons are sigmoid, they can take values only in a single range. The way out of this situation is to use the activation function of the same neurons for data preprocessing:
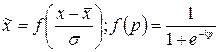
3. Removing redundancy.
For problems with many factors, data redundancy is often observed: data can be described with fewer signs, while retaining most of the information. Here, the most commonly used analysis of the main components and correlation analysis. The first way is to exclude signs with a small dispersion, the second is to identify pairs of strongly related signs and remove one of them.
4. Designing neural networks with various parameters.
The solution to this problem is largely determined by the experience of the researcher. The number of input and output network elements with a direct link and back-propagation of errors is usually dictated by the problem in question — the number of input features and the number of known classes. The dimensions of the hidden layer are usually found experimentally. Usually start with a single hidden layer, which contains 30-50% of the number of input elements. In the case of several hidden layers, it is recommended to use two times fewer neurons in each subsequent layer than in the previous one.
5. Selection of optimal networks.
The optimality criterion is also determined by the problem at hand. As such, a minimum of classification errors, a maximum reaction rate, etc. can be taken.
6. Estimation of the significance of predictions.
Testing of the obtained ANN model is carried out for test examples. If the network cannot generalize its capabilities to data unknown to it, then it is not of practical value. In statistics, the known relationship between the expected error in the training and test samples for linear models with the root-mean-square definition of the error:
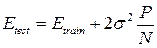
Here P is the number of free parameters of the model. In the case of neural networks, the number of free parameters is determined by the architecture: the number of layers, the number of neurons in the network, and the set of weights of connections between neurons of the network. It is assumed that these samples are noisy independent stationary noise with zero mean and variance σ 2 . This condition can be applied to non-linear models, if we consider them locally linear in a neighborhood of each point. Based on this assumption, a series of asymptotic estimates of the generalizing capacity of the network is constructed:
Akaika criterion: 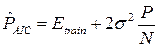 ;
;
- Bayesian criterion: 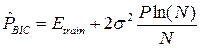 ;
;
- final prediction error  ;
;
- generalized cross-validation: 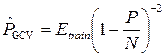 and etc.
and etc.
Ways to implement INS
Neural networks can be implemented in software or hardware.
Hardware implementation options are neurocomputers, neural boards, and neurobis (large integrated circuits). One of the simplest neurobis is MD 1220 from Micro Devices, which implements a network with 8 neurons and 120 synapses. NeuroBIS Adaptive Solutions is one of the fastest: the processing speed is 1.2 billion interneuron connections per second (mns / s).
Most modern neurocomputers are a personal computer or workstation, which include an additional neuropayment. The most interesting are specialized neurocomputers, which implement the principles of the architecture of neural networks. Representatives of such systems are computers of the Mark family of the TRW company (the first realization of the perceptron developed by F. Rosenblat, was called the Mark I). TRW's Mark III model is a workstation containing up to 15 processors of the Motorola 68000 family with mathematical coprocessors. All processors are connected by a VME bus. The system architecture, supporting up to 65,000 virtual processor elements with more than 1 million customizable connections, allows processing up to 450 thousand MS / s.
In those cases when the development or implementation of hardware implementations of neural networks is too expensive, use cheaper software implementations.

Comments
To leave a comment
Intelligent Information Systems
Terms: Intelligent Information Systems