Lecture
The role of the data source layer is to enable the application to interact with the various components of the infrastructure to perform the necessary functions. The main component of this problem is related to the support of the dialogue with the database - in most cases, relational. Until now, hefty arrays of data are still stored in obsolete formats, but almost all developers of modern applications involving communication with database systems are oriented towards relational DBMS.
One of the most serious reasons for the success of relational systems is their support for SQL, the most standardized language of communication with the database. Although today SQL is becoming increasingly cluttered with annoyingly incompatible and complex "improvements" supported by various database vendors, the syntax of the core language, fortunately, remains unchanged and accessible to all.
The first frame of architectural solutions includes, in particular, those that stipulate how business logic interacts with the database. The choice made at this stage has far-reaching consequences and it can be difficult or even impossible to cancel it. Therefore, he deserves the most thorough reflection. Often, such decisions are just due to options for the layout of business logic.
Despite the widespread support of enterprise applications, the use of SQL presents some difficulties. Many developers simply do not own SQL, and therefore, trying to formulate effective queries and commands, they encounter problems. In addition, without exception, the technology of introducing SQL statements into a code in a general-purpose programming language suffers from some flaws. (Of course, it would be better to access the contents of the database using some mechanisms of the language level of the application development.) And database administrators would like to understand the nuances of processing SQL expressions in order to be able to optimize them.
For these reasons, it makes more sense to isolate the SQL code from the business logic by placing it in special classes. A good way to organize such classes is to "copy" the structure of each database table in a separate class, which forms a gateway (Gateway), supporting the ability to access the table. Now, the main application code does not need to “know” anything about SQL, and all SQL operations are concentrated in a compact class group.
There are two main options for the practical use of a typical gateway solution. The most obvious is to create an instance of the gateway for each record returned as a result of processing a database request (Fig. 3.7). Such a data entry gateway (Row Data Gateway,) is a model that naturally reflects the object-oriented perception style of relational data.
In many environments, the Record Set model is supported — one of the underlying data structures that mimics the tabular form of a database's contents. Tooling systems even offer graphical interface elements that implement a set of records. Each database table should be associated with the corresponding object of the type Table Data Gateway (Figure 3.8), which contains methods for activating queries that return multiple records.
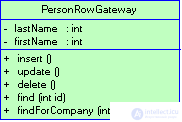
Figure 3.7 For each record returned by the request, an instance of the data recording gateway is created.
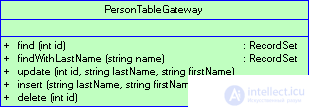
Figure 3.8 An instance of a data table gateway is created for each database table.
The fact that the gateway of the data table is successfully combined with a multitude of entries provides such an option for the gateway with obvious advantages when using a table module. This typical solution should be borne in mind when working with stored procedures. Often, it is preferable to access the database only through the mediation of stored procedures, rather than through direct access.
In a similar situation, determining the gateway of the data table for each table should
provide for a collection of relevant stored procedures. It is also possible to create in memory an additional data table gateway that performs the function of a wrapper that could hide the mechanism for calling stored procedures.
When using the Domain Model, other alternatives arise. In this context, it is appropriate to apply both a data recording gateway and a data table gateway. However, sometimes in this situation, these decisions may not be fully targeted or simply untenable.
In simple applications, the domain model is by no means a complicated structure, which can contain one domain class per each database table. Objects of such classes are often equipped with moderately complex business logic. In this case, it makes sense to assign each of them the responsibility for data input-output, which, in essence, is equivalent to applying the active record (Active Record) solution (Fig. 3.9). This solution can also be perceived as if, starting from the data entry gateway, we added a portion of business logic to the class (maybe when we found repeated code fragments in several transaction scenarios (Transaction Script)).
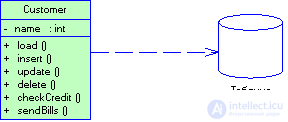
Figure 3.9 When using the Active Record pattern, a domain class object is aware of how to interact with the database.
In such situations, an additional level of mediation, formed through the use of a gateway, is not of great value. As business logic becomes more complex and the rich domain model grows in importance, simple solutions like active writing begin to lose ground. With the separation of business logic across smaller classes, the one-to-one correspondence between domain classes and database tables is gradually lost. Relational databases do not support the inheritance mechanism, which makes it difficult to apply strategies (strategies) and other developed object-oriented model solutions. And when business logic becomes increasingly erratic, it is desirable to be able to test it without having to constantly access the database. With the complication of the domain model, all these circumstances force the creation of intermediate functional levels. So, a solution like a gateway can fix some problems, but it still leaves us with a domain model that is closely tied to the database schema. As a result, when moving from the gateway fields to the fields of domain objects, you have to perform certain transformations, which lead to the complication of domain objects.
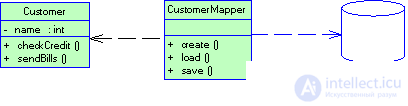
Figure 3.10 The data converter isolates domain objects from the database
A better option is to isolate the domain model from the database, placing the entire layer of responsibility for the mapping of domain objects into database tables. Such a data mapper (Data Mapper) (Fig. 3.10) serves all the loading and saving operations initiated by business logic and allows independent variation of both the domain model and the database schema. This is the most complex of architectural solutions that ensure consistency between application objects and relational structures, but its indisputable advantage lies in the complete separation of the two layers.
I would not recommend that the gateway be considered as the primary mechanism for storing data in the context of a domain model. If business logic is really simple and the degree of correspondence between classes and database tables is high, a typical solution would be a good alternative to the active record. If you have to deal with something more complex, the best choice is most likely to be a data converter.
The considered typical decisions cannot be considered mutually exclusive. In most cases, we will talk about the mechanism for storing information from certain memory structures in the database. To do this, you will have to choose one of the listed solutions - confusion of approaches is fraught with confusion. But even if, for example, a data converter is used as a tool for accessing the database, you can use, for example, a gateway to create wrappers for tables or services interpreted as external interfaces. Here and below, using the word table (table), it is understood that the discussed techniques and solutions apply equally to all data that has a different tabular nature: stored procedures, views, and also intermediate results of executing "traditional" queries and stored procedures. Unfortunately, there is no general term that covers all these concepts.
Updating operations of the contents of sources that are not stored tables is obviously more complicated, since the view is not always possible to modify directly - instead, it is necessary to manipulate the tables on which it was created. In this case, encapsulating a view / request using a suitable generic solution is a good way to concentrate the logic of update operations in one place, which makes using virtual structures easier and safer.
However, problems still remain. Misunderstanding of the nature of the formation of virtual tables leads to inconsistency of operations: if you consistently perform the update operation of two different structures based on the same stored tables, the second operation can affect the results of the first. Of course, in the logic of the update, it is possible to provide for appropriate checks aimed at avoiding the occurrence of such effects, but what price it will have to pay for all this.
I must also mention the simplest way to save data, which can be used even in the most complex domain models. At the dawn of the epoch of objects, many realized that there is a fundamental discrepancy between the relational and object models; This stimulated the creation of object-oriented DBMS, expanding the paradigm to the aspects of preserving information about objects on disks. When working with an object-oriented database, you do not need to worry about mapping objects into relational structures. You have a set of interrelated objects at your disposal, and the DBMS “worries” about how and when to read or save them. In addition, using the transaction mechanism, you have the right to group operations and manage the sharing of objects. For a programmer, it all looks as if he is interacting with an unlimited space of objects placed in RAM.
The main advantage of object-oriented databases is the increased productivity of application development: although any reproducible test indicators have not been officially published, in informal conversations it is constantly stated that the costs of ensuring consistency between application objects and relational structures of a traditional database are about a third of the total cost of the project and does not decrease during the whole cycle of the system maintenance.
In most cases, however, object-oriented databases are not used, and the main reason for this state of affairs is risk. Behind relational DBMSs are carefully developed, well-known and life-tested technologies, supported by all major suppliers of database systems for a long time. SQL is a fairly unified interface for a variety of tools.
If you do not have the ability or desire to use an object-oriented database, then, relying on the domain model, you should seriously consider the options for acquiring tools to display objects in relational structures. Although the ones considered in the standard solutions will tell you a lot of what you need to know to design an efficient data converter, in this field you will still need considerable effort. Suppliers of commercial tools designed to “bind” object-oriented applications to relational databases have spent many years solving such problems, and their software products are in many ways more creative, flexible and powerful than those that can be “hand-crafted”. I’ll make a reservation right away that they are not cheap, but the costs of their possible purchase should be compared with the significant costs that you will have to pay, choosing the path of self-creation and maintenance of this layer of program code.
One can not forget about the attempts to develop samples of the layer of code in the style of object-oriented database management systems capable of interacting with relational systems. In the Java world, such a "beast", for example, is JDO, but nothing definite can be said about the advantages or disadvantages of this technology. I have too little experience in using it to give any definitive conclusions on the pages of this book.
Even if you decide to purchase ready-made tools, familiarity with the typical solutions presented here does not hurt. Good tooling systems offer an extensive arsenal of alternatives to “connect” objects to relational databases, and competence in standard solutions will help you come to a meaningful choice. Do not think that the system will save you from all problems overnight; to make it work efficiently, you have to make a fair effort.
Title
Table Data Gateway (data table gateway)
Purpose
Using SQL in application logic may be associated with some problems. Not all developers know the language of SQL or are well versed in it. In his queue, DBMS administrators should have convenient access to SQL commands to configure and expand their databases.
A typical solution for a data table gateway contains all the SQL commands needed to extract, insert, update, and delete data from a table or view. The methods of this typical solution are used by other objects to interact with the database.
Operating principle
The data table gateway interface is extremely simple. It usually includes several search methods for extracting data, as well as methods for updating, inserting and deleting. Each method passes input parameters to the corresponding SQL command and executes it in the context of an established connection to the database. As a rule, this typical solution has no states, since it only transfers data to and from the table.
Perhaps the most interesting feature of the data table gateway is how it returns the result of the query. Even a simple query like "find data with the specified identifier" can return several records. This is not a problem for development environments that allow multiple results, but most classical programming languages allow you to return only one value.
Alternatively, you can map a database table to some simple structure like a collection. This will allow you to work with multiple results, but will require copying data from the resulting set of database records into the collection mentioned. In my opinion, this method is not very good, because it does not imply checking the compile time and does not provide an explicit interface, which leads to numerous programmer typos referring to the contents of the collection. A better solution is to use a universal Data Transfer Object.
Instead of all the above, the result of the SQL query can be returned as a set of records (Record Set). Generally speaking, this is not entirely correct, since an object located in RAM should not “know” about the SQL interface. In addition, if you cannot create multiple entries in your own code, this will cause certain difficulties when replacing a database with a file. Nevertheless, this method is very effective in many development environments that widely use multiple records, for example, such as .NET. In this case, the data table gateway is well combined with the table module (Table Module). If all table updates are performed through the data table gateway, the resulting data may be based on virtual rather than real tables, which reduces the dependence of the code on the database.
If you are using the Domain Model, the data table gateway methods can return the corresponding domain object.It should, however, be borne in mind that this implies bidirectional dependencies between domain objects and the gateway. Both are closely related, so the need to create such dependencies does not complicate things too much, but I still don’t like it.
As a rule, a separate data table gateway is created for each database table. However, in the simplest cases, it is possible to limit the development of a single data table gateway, which will include all methods for all tables. In addition, individual data table gateways can be created for views (virtual tables) and even for some queries that are not stored in the database in the form of views. Of course, the data table gateway for the view will not be able to update the data and therefore will not have the appropriate methods. However, if you can update the tables yourself, encapsulating the update procedures in the typical solution methods of the data table gateway is an excellent choice.
Applicability
When deciding whether to use a data table gateway, as well as a Row Data Gateway, you need to think about whether you should contact the gateway at all and if so, which one.
The data table gateway is the simplest typical database interface solution, since it perfectly displays tables or database records on objects. In addition, the data table gateway naturally encapsulates the exact logic of access to the data source. This solution is rarely used with a domain model, because a much greater isolation of the domain model from the data source can be achieved using a Data Mapper. A typical solution for a data table gateway is especially well combined with a table module. Data table gateway methods return data structures in the form of record sets that the table module then works with. In fact, it is simply impossible to come up with a different database mapping approach for a table module (at least, I think so).
Like a data entry gateway, a data table gateway is great for use in transaction scenarios (Transaction Script). In fact, the choice of one of several typical solutions depends only on how they handle multiple results. Some people prefer to transfer data through the data transfer object, but this solution seems to me more laborious (unless this object has already been implemented somewhere else in your project). I recommend using the data table gateway if its presentation of the resulting data set is suitable for working with a transaction script.
Что интересно, шлюзы таблицы данных могут выступать в качестве посредника при обращении к базе данных преобразователей данных. Правда, когда весь код пишется вручную, это не всегда нужно, однако данный прием может быть весьма эффективен, если для реализации шлюза таблицы данных используются метаданные, а реальное отображение содержимого базы данных на объекты домена выполняется вручную.
Одно из преимуществ использования шлюза таблицы данных для инкапсуляци доступа к базе данных состоит в том, что этот интерфейс может применяться и для обращения к базе данных с помощью средств языка SQL, и для работы с хранимыми процедурами. Более того, хранимые процедуры зачастую сами организованы в виде шлюзов таблицы данных. В этом случае хранимые процедуры, предназначенные для вставки и обновления данных, инкапсулируют реальную структуру таблицы. В свою очередь, процедуры поиска могут возвращать представления, что позволяет скрыть фактическую структуру используемой таблицы.
Title
Row Data Gateway (шлюз записи данных)
Purpose
Реализация доступа к базам данных в объектах, расположенных в оперативной памяти, имеет ряд недостатков. Прежде всего, если этим объектам присуща собственная бизнес-логика, добавление кода доступа к базе данных значительно повышает их сложность. Кроме того, это серьезно усложняет тестирование. Если объекты, расположенные в оперативной памяти, связаны с базой данных, тестирование выполняется крайне медленно из-за проблем, вызванных необходимостью доступа к базе данных. Особенно раздражает, когда приходится осуществлять доступ к нескольким базам данных, имеющим небольшие (но крайне досадные!) расхождения в реализации SQL
Типовое решение шлюз записи данных предоставляет в ваше распоряжение объекты, которые полностью аналогичны записям базы данных, однако могут быть доступны с помощью обычных механизмов используемого языка программирования. Все деталидоступа к источнику данных скрыты за интерфейсом.
Принцип действия
The data recording gateway acts as an object that completely repeats one record, for example, one row of a database table. Each column of the table corresponds to a record field. Typically, a data entry gateway should perform all possible data source type conversions to the types used by the application, however these conversions are quite simple. The considered typical solution contains all the data on the string, so the client has the ability to directly access the data recording gateway. The gateway acts as an interface to the data string and is perfect for use in transaction scripts (Transaction Script).
При реализации шлюза записи данных возникает вопрос: куда "пристроить" методы поиска, генерирующие экземпляр данного типового решения? Разумеется, можно воспользоваться статическими методами поиска, однако они исключают возможность полиморфизма (что могло бы пригодиться, если понадобится определить разные методы поиска для различных источников данных). В подобной ситуации часто имеет смысл создать отдельные объекты поиска, чтобы у каждой таблицы реляционной базы данных был один класс для проведения поиска и один класс шлюза для сохранения результатов этого поиска (рис. 3.11).
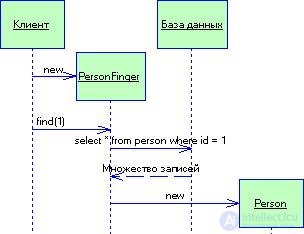
Рисунок 3.11 Взаимодействие со шлюзом записи данных для поиска нужной строки
Sometimes the data recording gateway is difficult to distinguish from the active record (Active Record). In this case, you should pay attention to the presence of any domain logic; if it is, then it is an active recording. The implementation of a data recording gateway should include only database access logic and no domain logic.
Like other forms of tabular encapsulation, the data entry gateway can be applied not only to a table, but also to a view or query. Of course, in the latter cases, the implementation of updates is significantly complicated, since it is necessary to update the tables on the basis of which the corresponding views or queries were created. In addition, if two data recording gateways work with the same tables, updating the second gateway can cancel the update of the first one. There is no universal way to prevent this problem; developers just need to keep track of how virtual data entry gateways are built. In the end, the same can happen with updated views. Of course, you may not implement the update methods at all.
Шлюзы записи данных довольно трудоемки в написании. Тем не менее генерацию их кода можно значительно облегчить посредством типового решения отображение метаданных (Metadata Mapping). В этом случае весь код, описывающий доступ к базе данных, может быть автоматически сгенерирован в процессе сборки проекта.
Applicability
Принимая решение об использовании шлюза записи данных, необходимо подумать о двух вещах: следует ли вообще использовать шлюз, и если да, то какой именно — шлюз записи данных или шлюз таблицы данных (Table Data Gateway).
Как правило, шлюз записи данных используют вместе со сценарием транзакции. В этом случае доступ к базе данных легко реализовать таким образом, чтобы соответствующий код мог повторно использоваться другими сценариями транзакции.
Шлюз записи данных не используют с моделью предметной области (Domain Model). Если отображение на объекты домена достаточно простое, его можно реализовать и с помощью активной записи, не добавляя дополнительный слой кода. Если же отображение сложное, для его реализации рекомендуется применить преобразователь данных (Data Mapper). Последний лучше справляется с отделением структуры данных от объектов домена, потому что объектам домена не нужно знать о структуре базы данных. Конечно же, шлюз записи данных можно использовать, чтобы скрыть структуру базы данных от объектовдомена. Это очень удобно, если вы собираетесь изменить структуру базы данных и не хотите менять логику домена. Тем не менее в этом случае у вас появится три различных представления данных: одно в бизнес-логике, одно в шлюзе записи данных и еще одно в базе данных. Для крупномасштабных систем это слишком много. Поэтому обычно используют шлюзы записи данных, отражающие структуру базы данных.
Интересно, что шлюз записи данных и преобразователь данных вполне могут сосуществовать. Несмотря на то что с первого взгляда это кажется излишней тратой сил, сочетание шлюза записи данных и преобразователя данных может оказаться весьма эффективным в том случае, если первый автоматически генерируется на основе метаданных, а второй создается вручную.
Если шлюз записи данных используется со сценарием транзакции, вы можете заметить, что в различных сценариях повторяется одна и та же бизнес-логика, которую можно было бы реализовать в шлюзе записи данных. Перенос этой логики в шлюз записи данных превратит его в активную запись. Это весьма удачное решение, поскольку позволяет избежать дублирования элементов бизнес-логики.
Title
Active Record (активная запись)
Purpose
Объект, выполняющий роль оболочки для строки таблицы или представления базы данных. Он инкапсулирует доступ к базе данных и добавляет к данным логику домена
This object covers both data and behavior. Most of its data is permanent and should be stored in a database. In a typical solution, the active record uses the most obvious approach, in which the data access logic is included in the domain object. In this case, everyone knows how to read data from the database and how to write it to it.
Operating principle
The typical solution is based on the active record of the Domain Model (Domain Model), whose classes follow the record structure of the database used. Each active record is responsible for storing and loading information into the database, as well as for the domain logic applied to the data. This may be all the business logic of the application. However, sometimes some fragments of domain logic are contained in transaction scenarios (Transaction Script), and common code elements oriented to work with data are in the active record.
The data structure of the active record must exactly match that in the database table: each field of the object must correspond to one column of the table. The field values should be left the same as they were obtained as a result of executing SQL commands; no conversion is necessary at this stage. If necessary, you can apply foreign key mapping, but this is not necessary. The active record can be applied to tables or views (although in the latter case it will be much more difficult to implement updates). The use of views is especially convenient when reporting.
As a rule, the typical solution of the active record includes methods designed to perform the following operations:
Методы извлечения и установки значений полей могут выполнять и другие действия, например преобразование типов SQL в типы, используемые приложением. Кроме того, get-метод может возвращать соответствующую активную запись таблицы, с которой связана текущая таблица (путем просмотра первой), даже если для структуры данных не было определено поле идентификации (Identity Field).
Классы активной записи довольно удобны с точки зрения разработчиков, однако непозволяют им полностью абстрагироваться от реляционной базы данных. Впрочем, это не так уж плохо, поскольку дает возможность использовать меньше типовых решений, предназначенных для отображения объектной модели на базу данных.
Активная запись очень похожа на шлюз записи данных (Row Data Gateway). Принципиальное отличие между ними состоит в том, что шлюз записи данных содержит только логику доступа к базе данных, в то время как активная запись содержит и логику доступа к данным, и логику домена. Как это часто бывает в мире программного обеспечения, граница между упомянутыми типовыми решениями весьма приблизительна, однако игнорировать ее все-таки не следует.
Since the active record is closely tied to the database, I recommend using static search methods in this typical solution. However, it makes no sense to allocate search methods to a separate class, as was done in the data entry gateway (here it is not necessary, and it will be easier to test).
Like other typical solutions designed to work with tables, the active record can be applied not only to tables, but also to views or queries.
Applicability
Active writing is well suited for implementing not-too-complex domain logic, in particular, create, read, update, and delete operations. In addition, it copes with the extraction and validation of a separate record. As already noted, the main problem in developing a domain model is
is to choose between the active recording and data mapper. The advantage of active recording is its ease of implementation. The disadvantage is that active records are good only when they are accurately mapped to database tables (isomorphic scheme). If the business logic of the application is quite complex, you will certainly want to use the existing relationships, collections, inheritance, etc. All this is not very well displayed on the active record, and the addition of these elements "in parts" will lead to a terrible confusion. In such situations it is better to use a data converter.
Another disadvantage of using active recording is the close dependence of the structure of its objects on the structure of the database. In this case, it is quite difficult to change the structure of the database or the active record, but as the project progresses, such a need arises very, very often.
It is good to combine the active record with the transaction script, especially if you are confused by the constant repetition of the same code and the complexity of updating the tables and scripts; such situations often accompany the use of transaction scripts. In this case, you can start creating active records, gradually transferring repetitive logic to them. As another useful trick, I can recommend creating a wrapper for the table in the form of a gateway (Gateway) and then gradually transfer logic to it, turning the gateway into an active entry.
Title
Data Mapper (data converter)
Purpose
A layer of converters (Mapper) that transfers data between objects and the database, keeping the latter independent of each other and of the converter itself.
Objects and relational databases use different data structuring mechanisms. Relational databases do not display many characteristics of objects, in particular collections and inheritance. When constructing an object model with a large amount of business logic, these mechanisms make it possible to better organize the data and the corresponding behavior. On the other hand, the use of such mechanisms leads to a mismatch between the object and relational schemes.
The object model and the relational DBMS must exchange data. The mismatch of schemes makes this task extremely difficult. If an object "knows" about the structure of a relational database, changing one of them makes it necessary to change the other.
A typical solution data converter is a layer of software that separates objects located in RAM from the database. The functions of the data converter include transferring data between objects and the database and isolating them from each other. Due to the use of this typical solution, objects located in RAM may not even “suspect” the very fact of the presence of the database. They do not need a SQL interface, much less a database schema. (In turn, the database schema never "knows" about the objects that use it.) Moreover, since the data converter is a kind of converter, it is completely hidden from the domain level.
Operating principle
The main function of the data converter is to separate the domain from the source. data, however, this function can only be implemented in the light of many details. In addition, the design of the layers of the display can also be implemented in different ways.
First, consider an example of an elementary data converter. Structure This layer is too simple and perhaps not worth the effort that can be spent on its implementation. In addition, the simple structure of the converter entails is the use of simpler (and therefore better) typical solutions, which is hardly suitable for real systems. Nevertheless, it is better to begin the explanation of new ideas with simple examples.
In this example, we have the classes Person and PersonMapper. To load data into the Person object, the client calls the search method of the PersonMapper class (Fig. 3.12). The converter uses a collection of objects to check whether the data about the requested person is loaded; if not, it loads them. Updates are shown in Fig. 3.13. The client instructs the converter to save the domain object. The converter extracts data from the domain object and sends it to the database.
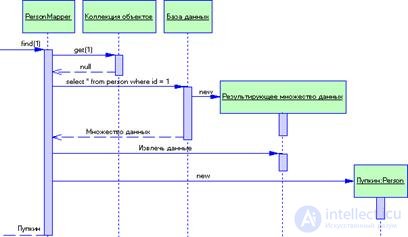
Figure 3.12 Extracting data from their database
If necessary, the entire data converter layer can be replaced, for example, in order to test or use the same domain level to work with several databases.
The elementary data converter considered by us only maps a database table to an equivalent object on a column-on-field basis. Of course, in real life is not so simple. Converters must be able to handle classes whose fields are joined by a single table, classes that correspond to several tables, classes with inheritance, and also deal with the binding of loaded objects. All typical solutions of object-relational mapping, discussed in this book, one way or another are aimed at solving such problems. As a rule, these solutions are easier to create on the basis of a data converter than with the help of any other means.
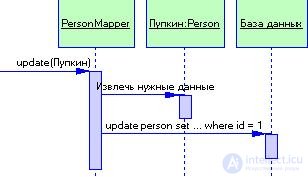
Figure 3.13 Data Saving
To perform data insertion and update, the display layer must know which objects have been changed, which have been created, and which have been destroyed. In addition, all these actions need to somehow "fit" into the scope of the transaction. A good way to organize an update mechanism is to use a typical solution Unit of Work.
In the scheme shown in fig. 3.12, it was assumed that one call to the search method results in the execution of a single SQL query. It is not always so. For example, downloading order data consisting of several items may include loading each item of the order. Typically, a client request results in the loading of a whole graph of related objects. In this case, the converter developer must decide how many objects can be loaded at a time. Since the number of calls to the database should be as small as possible, search methods should be aware of how clients use objects to determine the optimal amount of data loaded.
The described example brings us to the situation where, as a result of executing one request, the converter loads several classes of domain objects. If you want to load orders and items of orders, this can be done with a single request, by applying the join operation to the tables of orders and ordered goods. The resulting result set is used to load instances of the order class and the order item class.
As a rule, objects are closely interconnected, so at some stage data loading should be interrupted. Otherwise, the execution of a single query can lead to the loading of the entire database! To solve this problem and simultaneously minimize the impact on objects located in memory, the display layer uses Lazy Load. For this reason, application objects cannot "know" anything at all about the display layer. Most likely, they should be “aware” of search methods and some other mechanisms.
An application can have one or more data transformers. If the code for converters is written manually, I recommend creating one converter for each domain class or for the root class in the domain hierarchy. If you use the metadata mapping (Metadata Mapping), you can limit yourself to one class of converter. In the latter case, it all depends on the number of search methods. If the application is large enough, the search methods may be too much for one converter, so it would be wiser to break them up into several classes, creating a separate class for each domain class or root class in the domain hierarchy. You will have a lot of small classes with search methods, but now the developer will be much easier to find what he needs.
Like all other database search engines, the mentioned search methods must use a collection of objects to keep track of which records have already been read from the database. To do this, you can create a registry (Registry) of collections of objects or assign each search method its own collection of objects (provided that during one session each class uses only one search method).
Appeal to search methods
To be able to work with an object, it must be downloaded from the database. Typically, this process is started by the presentation layer, which loads some initial objects, and then transfers control to the domain layer. The domain layer loads the object behind the object sequentially using the set between associations. This technique is very effective, provided that the domain layer has there are all objects that need to be loaded into RAM, or what The domain layer loads additional objects only as needed by applying load on demand.
Sometimes domain objects may need to refer to the search methods defined in the data converter. As practice shows, successful implementation of load on demand allows you to completely avoid such situations. Of course, with the development of simple applications, the use of associations and load on demand may not justify the effort, however, add an extra dependency of objects domain from the data converter also does not follow.
As a solution to this dilemma, the use of the Separated Interface can be suggested. In this case, all the search methods used by the domain code can be put into the interface class and placed in the domain package.
Data mapping to domain object fields
Converters must have access to the fields of domain objects. Often this causes difficulties, since it implies the existence of methods open to converters, which should not be the case in business logic. (I assume that you don’t made a terrible mistake by leaving the fields of domain objects open (public).) There is no universal solution to this problem. You can apply a lower visibility level by placing converters “closer” to domain objects (for example, in one package, as it is done in Java), but such a decision will extremely confuse the global dependency picture, because other parts of the system that “know” about domain objects should not be "aware" of converters. You can use the reflection mechanism, which often allows you to bypass the rules of visibility of a specific programming language. This is a rather slow method, however it can be much faster execution of a SQL query. Finally, you can use open methods, pre-supplying them with state fields that generate an exception when trying to use these methods not to load data from the converter. In that case name the methods so that they are not mistaken for ordinary get and set methods.
The described problem is closely related to the issue of creating an object. Last possible exercise in two ways. The first is to create an object using constructor with initialization, which immediately fills the new object with all the necessary data. The second is to create an empty object and subsequent filling it with data.
When using a constructor with initialization, there is a problem with the presence of circular references. If you have two objects referencing each other, an attempt to load the first object will load the second object, which, in turn, will again load the first object and so on until a stack overflow occurs. A possible way out is to describe a special case (Special Case). This is usually done using a typical load-on-demand solution. Writing code for a particular case is not an easy task, so I recommend trying something else, such as using a constructor without arguments. to create an empty object. Create an empty object and immediately place its to the collection of objects. Now, if the loaded objects will be linked by a circular reference, the collection of objects will return the desired value to terminate "recursive" boot.
As a rule, filling an empty object is carried out by means of set-methods. Some of them can set field values, which after loading data must remain unchanged. To prevent these fields from being accidentally changed after loading an object, assign special names to the set methods and possibly equip them with status check fields. In addition, you can perform data loading using the reflection mechanism.
Mapping based on metadata
When developing a corporate application for interacting with the database, it is necessary to decide how the fields of the domain objects will be displayed on the columns of the database tables. The easiest (and often the best) way to accomplish this is to explicitly describe the mapping in the code, which requires creating a converter class for each domain object. The converter performs the mapping by assigning values and contains SQL commands for accessing the database (usually they are stored as text constants). As an alternative to this method, it is possible to suggest the use of metadata mapping, which saves table metadata in the form of ordinary data, in a class or in a separate file. The great advantage of metadata is that they allow you to make changes to the converter by generating code or applying reflective programming without writing additional code manually.
Applicability
In most cases, the data converter is used so that the database schema and object model can be changed independently of each other. As a rule, such a need arises when using a domain model. The main advantage of the data converter is the ability to work with the domain model without taking into account the database structure both during the design process and during the assembly and testing of the project. In this case, the domain objects do not know anything about the structure of the database, since all mappings are performed by converters.
The use of data converters helps in writing code, because it allows you to work with domain objects without having to understand the principle of storing relevant information in a database. Changing the domain model does not require changing the database structure and vice versa, which is extremely important in the presence of complex mappings, especially when using existing databases.
Of course, for all the amenities you need to pay. The “cost” of using a data converter is the need to implement an additional layer of code, which can be avoided by applying, say, Active Record. Therefore, the main criterion for the selection of a typical solution is the complexity of business logic. If the business logic is fairly simple, it can most likely be implemented without applying the domain model or data transformer. In turn, the implementation of more complex logic is impossible without using a domain model and, as a consequence, a data converter.
I would not use a data converter without a domain model. But is it possible to use a domain model without a data converter? If the model is quite simple, and its developers themselves control changes in the structure of the database, domain objects can be accessed directly by using active recording. In this case, the role of the converter is successfully performed by the domain objects themselves. Nevertheless, as the logic of the domain becomes more complex, the functions of access to the database are better placed in a separate layer.
I would also like to draw your attention to the fact that you do not need to develop a fully functional database mapping layer on domain objects from scratch. It is very difficult, and there are a lot of similar products on the software market. In most cases, I recommend to purchase a ready-made converter instead of developing it yourself.
When it comes to the mapping of objects and tables of a relational database, attention usually focuses on structural aspects, that is, how to relate tables and objects. However, the most difficult part of the problem is the choice and justification of the architectural and functional components.
Having discussed the main options for architectural solutions, we will consider the functional (behavioral) side, in particular the question of how to ensure the loading of various objects and their storage in the database. На первый взгляд это не кажется слишком сложной задачей: объект можно снабдить соответствующими методами загрузки ("load") и сохранения ("save"). Именно такой путь целесообразно избрать, например, при использовании решения активная запись (Active Record). Загружая в память большое количество объектов и модифицируя их, система должна следить за тем, какие объекты подверглись изменению, и гарантировать сохранение их содержимого в базе данных. Если речь идет всего о нескольких записях, это просто. Но по мере увеличения числа объектов растут и проблемы: как быть, скажем, в такой далеко не самой сложной ситуации, когда необходимо создать записи, которые должны ссылаться на ключевые значения друг друга.
При выполнении операций считывания или изменения объектов система должна гарантировать, что состояние базы данных, с которым вы имеете дело, остается согласованным. Так, например, на результат загрузки данных не должны влиять изменения, вносимые другими процессами. В противном случае итог операции окажется непредсказуемым. Подобные вопросы, относящиеся к дисциплине управления параллельными заданиями, весьма серьезны. Они обсуждаются разделе "Управление параллельными заданиями".
Типовым решением, имеющим существенное значение для преодоления такого рода проблем, является единица работы (Unit of Work), использование которой позволяет отследить, какие объекты считываются и какие модифицируются, и обслужить операции обновления содержимого базы данных. Автору прикладной программы нет нужды явно вызывать методы сохранения — достаточно сообщить объекту единица работы о необходимости фиксации (commit) результатов в базе данных. Типовое решение единица работы упорядочивает все функции по взаимодействию с базой данных и сосредоточивает в одном месте сложную логику фиксации. Его лучшие качества проявляются именно тогда, когда интерфейс между приложением и базой данных становится особенно запутанным.
Решение единица работы удобно воспринимать в виде объекта, действующего как контроллер процессов отображения объектов в реляционные структуры. В отсутствие такового роль контроллера, принимающего решения о том, когда и как загружать и сохранять объекты приложения, обычно выполняет слой бизнес-логики. В процессе загрузки данных необходимо тщательно следить за тем, чтобы ни один из объектов не был считан дважды, иначе в памяти будут созданы два объекта, соответствующих одной и той же записи таблицы базы данных. Попробуйте обновить каждую из них, и неприятности не заставят себя ждать. Чтобы уйти от проблем, необходимо вести учет каждой считанной записи, а поможет в этом типовое решение коллекция объектов (Identity Map). Каждый раз при необходимости считывания порции данных вначале следует проверить, не содержится ли она в коллекции объектов. Если информация уже загружалась, можно предусмотреть возврат ссылки на нее. В этом случае любые попытки изменения данных будут скоординированы. Еще одно преимущество - возможность избежать дополнительного обращения к базе данных, поскольку коллекция объектов действует как кэш-память. Не забывайте, однако, что главное назначение коллекции объектов - учет идентификационных номеров объектов, а не повышение производительности приложения.
При использовании модели предметной области (Domain Model) связанные объекты загружаются совместно таким образом, что операция считывания одного объекта инициирует загрузку другого. Если связями охвачено много объектов, считывание любого из них приводит к необходимости загружать из базы данных целый граф объектов. Чтобы исключить подобное неэффективное поведение системы, необходимо умерить аппетит, сократив количество загружаемых объектов, но оставить за собой право завершения операции, если потребность в дополнительной информации действительно возникнет. Типовое решение загрузка по требованию (Lazy Load,) предполагает использование специальных меток вместо ссылок на реальные объекты. Существует несколько вариаций схемы, но во всех случаях реальный объект загружается только тогда, когда предпринимается попытка проследовать по ссылке, которая его адресует. Решение загрузка по требованию позволяет оптимизировать число обращений к базе данных.
Рассматривая проблему считывания информации из базы данных, рекомегдуется трактовать предназначенные для этого методы в виде функций поиска (finders), скрывающих посредством соответствующих входных интерфейсов SQL-выражения формата "select". Примерами подобных методов могут служить find (id) или findForCustomer (customer). Разумеется, если ваше приложение оперирует тремя десятками выражений "select" с различными критериями выбора, указанная схема становится чересчур громоздкой, но такие ситуации, к счастью, редки. Принадлежность методов зависит от вида используемого интерфейсного типового решения. Если каждый класс, обеспечивающий взаимодействие с базой данных, привязан к определенной таблице, в его состав наряду с методами вставки и замены уместно включить и методы поиска. Если же объект класса соответствует отдельной записи данных, требуется иной подход. В этом случае можно попробовать сделать методы поиска статическими, но за это придется заплатить некоторой долей гибкости, в частности вам более не удастся в целях тестирования заменить базу данных фиктивной службой (Service Stub). Чтобы избежать подобных проблем, лучше предусмотреть специальные классы поиска, включив в состав каждого из них методы, обеспечивающие инкапсуляцию тех или иных SQL-запросов. В результате выполнения запроса метод возвращает коллекцию объектов, соответствующих определенным записям данных.
Применяя методы поиска, следует помнить, что они выполняются в контексте состояния базы данных, а не состояния объекта. Если после создания в памяти объектов-записей данных, отвечающих некоторому критерию, вы активизируете запрос, который предполагает поиск записей, удовлетворяющих тому же критерию, то очевидно, что объекты, созданные, но не зафиксированные в базе данных, в результат обработки запроса не попадут.
При считывании данных проблемы производительности могут приобретать первостепенное значение. Необходимо помнить несколько эмпирических правил. Старайтесь при каждом обращении к базе данных извлекать немного больше записей, чем нужно. В частности, не выполняйте один и тот же запрос повторно для приобретения дополнительной информации. Почти всегда предпочтительнее получить как можно больше данных, но нужно отдавать себе отчет в том, что при использовании пессимистической стратегии управления параллельными заданиями это может привести к ненужному блокированию большого количества записей. Например, если необходимо найти 50 записей, удовлетворяющих определенному условию, лучше выполнить запрос, возвращающий 200 записей, и применить для отбора искомых дополнительную логику, чем инициировать 50 отдельных запросов.
Другой способ исключить необходимость неоднократного обращения к базе данных связан с применением операторов соединения (join), позволяющих с помощью одного запроса извлечь информацию из нескольких таблиц. Итоговый набор записей может содержать больше информации, чем требуется, но скорость его получения, вероятно, выше, чем в случае выполнения нескольких запросов, возвращающих в результате те же данные. Для этого следует воспользоваться шлюзом (Gateway), охватывающим информацию из нескольких таблиц, которые подлежат соединению, или преобразователем данных (Data Mapper), позволяющим загрузить несколько объектов домена с помощью единственного вызова.
Применяя механизм соединения таблиц, имейте в виду, что СУБД способны эффективно обслуживать запросы, в которых соединению подвергнуто не более трех-четырех таблиц. В противном случае производительность системы существенно падает, хотя воспрепятствовать этому, по меньшей мере частично, удается, например, с помощью разумной стратегии кэширования представлений. Работу СУБД можно оптимизировать самыми разными способами, включая компактное группирование взаимосвязанных данных, тщательное проектирование индексов и кэширование порций информации в оперативной памяти. Все эти технологии, однако, выбиваются из контекста книги (хотя должны быть присущи сфере профессиональных интересов хорошего администратора баз данных).
Во всех случаях, тем не менее, следует учитывать особенности конкретных приложений и базы данных. Наставления общего характера хороши до определенного момента, когда необходимо как-то организовать способ мышления, но реальные обстоятельства всегда вносят свои коррективы. Достаточно часто СУБД и серверы приложений обладают сложными механизмами кэширования, затрудняющими дать хоть сколько-нибудь точную оценку производительности приложения. Никакое правило не обходится без исключений, так что тонкой настройки и доводки системы избежать не удастся.
Во всех разговорах об объектно-реляционном отображении обычно и прежде всего имеется в виду обеспечение взаимно однозначного соответствия между объектами в памяти и табличными структурами базы данных на диске. Подобные решения, как правило, не имеют ничего общего с вариантами шлюза таблицы данных (Table Data Gateway) и находят ограниченное применение совместно с решениями типа шлюза записи данных (Row Data Gateway) и активной записи (Active Record), хотя все они, вероятно, окажутся востребованными в контексте преобразователя данных (Data Mapper).
Главная проблема, которая обсуждается в этом разделе, обусловлена тем, что связи объектов и связи таблиц реализуются по-разному. Проблема имеет две стороны. Во-первых, существуют различия в способах представления связей. Объекты манипулируют связями, сохраняя ссылки в виде адресов памяти. В реляционных базах данных связь одной таблицы с другой задается путем формирования соответствующего внешнего ключа (foreign key). Во-вторых, с помощью структуры коллекции объект способен сохранить множество ссылок из одного поля на другие, тогда как правила нормализации таблиц базы данных допускают применение только однозначных ссылок. Все это приводит к расхождениям в структурах объектов и таблиц. Так, например, в объекте, представляющем сущность "заказ", совершенно естественно предусмотреть коллекцию ссылок на объекты, описывающие заказываемые товары, причем последним нет необходимости ссылаться на "родительский" объект заказа. Но в схеме базы данных все обстоит иначе: запись в таблице товаров должна содержать внешний ключ, указывающий на запись в таблице заказов, поскольку заказ не может иметь многозначного поля.
Рисунок 3.14 Пример использования паттерна Отображение внешних ключей для реализации однозначной ссылки
Чтобы решить проблему различий в способах представления связей, достаточно сохранять в составе объекта идентификаторы связанных с ним объектов-записей, используя типовое решение поле идентификации (Identity Field [4]), а также обращаться к этим значениям, если требуется прямое и обратное отображение объектов и ключей таблиц базы данных. Это довольно скучно, но вовсе не так трудно, если усвоить основные приемы. При считывании информации из базы данных для перехода от идентификаторов записей к объектам используется коллекция объектов (Identity Map [4]). Связи, задаваемой внешним ключом, отвечает типовое решение отображение внешних ключей (Foreign Key Mapping [4]), устанавливающее подходящую связь одного объекта с другим (рис. 3.14). Если в коллекции объектов ключа нет, необходимо либо считать его из базы данных, либо применить вариант загрузки по требованию (Lazy Load). При сохранении информации объект фиксируется в таблице базы данных в виде записи с соответствующим ключом, а все ссылки на другие объекты, если таковые существуют, заменяются значениями полей идентификации этих объектов.
Если объект способен содержать коллекцию ссылок, требуется более сложная версия отображения внешних ключей, пример которой представлен на рис. 3.15. В этом случае, чтобы отыскать все записи, содержащие идентификатор объекта-источника, необходимо выполнить дополнительный запрос (или воспользоваться решением загрузка по требованию). Для каждой считанной записи, удовлетворяющей критерию поиска, создается соответствующий объект, и ссылка на него добавляется в коллекцию. Для сохранения коллекции следует обеспечить сохранение каждого объекта в ней, гарантируя корректность значений внешних ключей. Операция может быть довольно сложной, особенно в том случае, когда приходится отслеживать динамику добавления объектов в коллекцию и их удаления. В крупных системах с подобной целью применяются подходы, основанные на метаданных (об этом речь идет несколько позже). Если объекты коллекции не используются вне контекста ее владельца, для упрощения задачи можно обратиться к типовому решению отображение зависимых объектов (Dependent Mapping).

Рисунок 3.15. Пример использования паттерна Отображение внешних ключей для реализации коллекции ссылок
Совсем иная ситуация возникает, когда связь относится к категории "многие ко многим", то есть. коллекции ссылок присутствуют "с обеих сторон" связи. Примером может служить множество служащих и общий набор профессиональных качеств, отдельными из которых обладает каждый служащий. В реляционных базах данных проблема описания такой структуры преодолевается за счет создания дополнительной таблицы, содержащей пары ключей связанных сущностей (именно это предусмотрено в типовом решении отображение с помощью таблицы ассоциаций (Association Table Mapping), пример которого показан на рис. 3.16.

Рисунок 3.16 Пример использования паттерна Отображение с помощью таблицы ассоциаций для реализации связи «многие ко многим»
При работе с коллекциями принято полагаться на критерий упорядочения, с учетом которого она создана. В объектно-ориентированных языках программирования обшей практикой является использование типов упорядоченных коллекций, подобных спискам и массивам. Однако задача сохранения в реляционной базе данных содержимого коллекции с произвольным критерием упорядочения остается сложной. В качестве способов ее решения можно порекомендовать использование неупорядоченных множеств или определение критерия упорядочения на этапе выполнения запроса к коллекции (последний подход связан с большими затратами).
В некоторых случаях проблема обновления данных усугубляется из-за необходимости выполнять условия целостности на уровне ссылок (referential integrity). Современные СУБД позволяют откладывать (defer) проверку таких условий до завершения транзакции. Если "ваша" система такую возможность предоставляет, грех ею не воспользоваться. Если нет, система инициирует проверку после каждой операции записи. В такой ситуации вы обязаны соблюдать верный порядок прохождения операций. Не вдаваясь в детали, напомню, что один из подходов связан с построением и анализом графа, описывающего такой порядок, а другой состоит в задании жесткой схемы выполнения операций непосредственно в коде приложения. Иногда это позволяет снизить вероятность возникновения ситуаций взаимоблокировки (deadlock), для разрешения которых приходится осуществлять откат (rollback) тех или иных транзакций.
Для описания связей между объектами, преобразуемых во внешние ключи, используется типовое решение поле идентификации, но далеко не все связи объектов следует фиксировать в базе данных именно таким образом. Разумеется, небольшие объекты-значения (Value Object), описывающие, скажем, диапазоны дат или денежные величины, нецелесообразно представлять в отдельных таблицах базы данных. Объект-значение уместнее отображать в виде внедренного значения (Embedded Value), то есть набора полей объекта, "владеющего" объектом-значением. При необходимости загрузки данных в память объекты-значения можно легко создавать заново, не утруждая себя использованием коллекции объектов. Сохранить объект-значение также несложно - достаточно зафиксировать значения его полей в таблице объекта-владельца.
Можно пойти дальше и предложить модель группирования объектов-значений с сохранением их в таблице базы данных в виде единого поля типа крупный сериализованный
объект (Serialized LOB). Аббревиатура LOB происходит от словосочетания Large OBject и означает "крупный объект"; различают крупные двоичные объекты (Binary LOBs — BLOBs) и крупные символьные объекты (Character LOBs — CLOBs). Сериализация множества объектов в виде XML-документа — очевидный способ сохранения иерархических объектных структур. В этом случае для считывания исходных объектов будет достаточно одной операции. При выполнении большого количества запросов, предполагающих поиск мелких взаимосвязанных объектов (например, для построения диаграмм или обработки счетов), производительность СУБД часто резко падает, и крупные сериализованные объекты позволяют существенно снизить загрузку системы.
Недостаток такого подхода состоит в том, что в рамках "чистого" SQL сконструировать запросы к отдельным элементам сохраненной структуры не удастся. На помощь может прийти XML, позволяющий внедрить выражения формата XPath в вызовы SQL, хотя такой подход на данный момент пока не стандартизован. Крупные сериализованные объекты лучше всего применять для хранения относительно небольших групп объектов. Злоупотребление этим подходом приведет к тому, что база данных со временем будет напоминать файловую систему.
Выше уже упоминались составные иерархические структуры, которые традиционно плохо отображаются средствами реляционных систем баз данных. Существует и другая разновидность иерархий, еще более усугубляющих страдания приверженцев реляционной модели: речь идет об иерархиях классов, создаваемых на основе механизма наследования (inheritance). Поскольку SQL не предоставляет стандартизованных инструментов поддержки наследования, придется вновь прибегнуть к аппарату отображения.
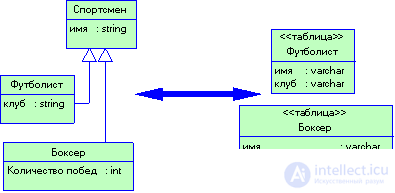
Рисунок 3.17 Паттерн Наследование с одной таблицей предусматривает сохранение значений атрибутов всех классов иерархии в одной таблице
Рисунок 3.18 Паттерн Наследование таблиц для каждого конкретного класса предусматривает использование отдельных таблиц для каждого конкретного класса иерархии
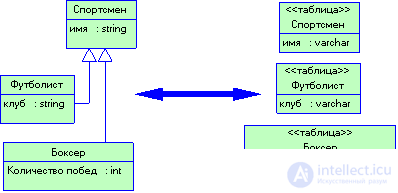
Рисунок 3.19 Паттерн Наследование таблиц для каждого класса предусматривает использование отдельных таблиц для каждого класса иерархии
Существует три основных варианта представления структуры наследования: "одна таблица для всех классов иерархии" (наследование с одной таблицей (Single Table Inheritance) - рис. 3.18; "таблица для каждого конкретного класса" (наследование с таблицами для каждого конкретного класса (Concrete Table Inheritance) - рис. 3.19; "таблица для каждого класса" (наследование с таблицами для каждого класса (Class Table Inheritance) - рис. 3.20.
Возможен компромисс между необходимостью дублирования элементов данных и потребностью в ускорении доступа к ним. Решение наследование с таблицами для каждого класса - самый простой и прямолинейный вариант соответствия между классами и таблицами базы данных, но для загрузки информации об отдельном объекте в этом случае приходится осуществлять несколько операций соединения (join), что обычно сопряжено со снижением производительности системы. Решение наследование с таблицами для каждого конкретного класса позволяет обойти соединения, предоставляя возможность считывания всех данных об объекте из единственной таблицы, но существенно препятствует внесению изменений. При любой модификации базового класса нельзя забывать о необходимости соответствующего преобразования всех таблиц дочерних классов (и кода, обеспечивающего корректное отображение). Изменение самой иерархической структуры способно вызвать еще более серьезные проблемы. Помимо того, отсутствие таблицы для базового класса может усложнить управление ключами. Что касается наследования с одной таблицей, то самым большим недостатком этого решения является нерациональное расходование дискового пространства, поскольку каждая запись таблицы содержит поля для атрибутов всех созданных дочерних классов и многие из этих полей остаются пустыми. (Впрочем, некоторые СУБД "умеют" осуществлять сжатие неиспользуемых областей.) Большой размер записи приводит и к замедлению ее загрузки. Преимущество же наследования с одной таблицей заключается в том, что все данные, относящиеся к любому классу, сосредоточены в одном месте, а это значительно упрощает возможность внесения изменений и позволяет избежать операций соединения. Три упомянутых решения не являются взаимоисключающими - их вполне можно сочетать в рамках одной и той же иерархии классов: например, информацию о наиболее важных классах уместно объединить посредством наследования с одной таблицей, а для других классов воспользоваться решением наследование с таблицами для каждого класса. Разумеется, совмещение решений повышает сложность их применения.
Среди названных способов отображения иерархии наследования трудно выделить какой-либо один. Как и при использовании всех других типовых решений, необходимо принять во внимание конкретные обстоятельства и требования.
Отображение объектов в реляционные структуры, по существу, сводится к одной из трех общих ситуаций:
В простейшем случае, когда схема создается самостоятельно, а бизнес-логика отличается умеренной сложностью, оправдан подход, основанный на сценарии транзакции (Transaction Script) или модуле таблицы (Table Module); таблицы могут создаваться с помощью традиционных инструментов проектирования баз данных. Для исключения кода SQL из бизнес-логики применяется шлюз записи данных (Row Data Gateway,) или шлюз таблицы данных (Table Data Gateway). Используя модель предметной области (Domain Model), остерегайтесь структурировать приложение с оглядкой на схему базы данных и больше заботьтесь об упрощении бизнес-логики. Воспринимайте базу данных только как инструмент сохранения содержимого объектов. Наибольший уровень гибкости взаимного отображения объектов и реляционных структур обеспечивает преобразователь данных (Data Mapper), но это типовое решение отличается повышенной сложностью. Если структура базы данных изоморфна модели предметной области, можно воспользоваться активной записью (Active Record).
Although the primary model building is a convenient way of perceiving the subject area, this option is valid only when it is implemented during a short iterative cycle. Spending six months for building a domain model that does not involve applying a database, and then at one point comes to the conclusion that storing some information would still be nice, not only frivolous, but also very risky. The danger is that if the project demonstrates flaws at the level of performance, it will not be easy to correct the situation. Each one-and-a-half-month or even shorter iteration of the development of a model and application should be accompanied by making decisions concerning the specification and expansion of the database schema. In this case, you will always have the latest information on how the interface of the application interacts with the database behaves in practice. So, solving any particular problem, first of all it is necessary to think about the domain model, not forgetting to immediately integrate each part of it into the database.
If the database schema is created ahead of time, you have about the same alternatives at your disposal, but the process is somewhat different. If the business logic is simple, its layer is located "on top" of the created data recording gateway or data table gateway simulating database functions. As the level of complexity of business logic increases, one has to resort to using a domain model, supplemented by a data converter, which must ensure that the contents of application objects are stored in an existing database.
The presence of repeated code fragments in the application text is a sign of its poorly thought-out structure. Generic functions can be put out of the brackets, for example, by means of inheritance and delegation — some of the main mechanisms of object-oriented programming, but there is a more sophisticated approach associated with displaying metadata (Metadata Mapping).
A typical solution is the mapping of metadata based on the removal of the functions of mapping to the metadata file, which defines the correspondence between the columns of the database tables and fields of the objects. The presence of metadata allows not to repeat the mapping code and re-generate it as necessary. Even a trivial piece of metadata, like the one below, can very expressively convey a large amount of information.
<class name = 'Person' tableName = 'Person'>
<attr name = 'id' field = 'person_id'>
<attr name = 'lastName' field = 'last_name>
</ class>
With the help of this information you will be able to determine the operations of reading and writing data, automatically generating any SQL expressions, supporting multiple links, etc. That is why the metadata model is widely used in commercial tools for displaying objects and relational structures.
Mapping metadata offers everything needed for constructing queries in terms of application objects. A typical solution of a query object (Query Object) allows you to create queries based on objects and data in memory, without requiring knowledge of SQL and the details of the relational schema, and use metadata mapping tools to translate such expressions into appropriate SQL constructs.
Use these solutions at the earliest stages of the project, and you will be able to apply one of the forms of storage (Repository,), which completely hides the database from the outside. Any queries to the database can be treated as query objects in the context of the repository: in this situation, the application developer does not know whether the objects are being retrieved from the memory or from the database. The storage solution is very well combined with rich domain model (Domain Model).
In most cases, the application interacts with the database through the mediation of some connection object (connection). Before executing commands and database queries, the connection usually needs to be opened. The connection object must remain in an open state throughout the entire session of working with the database. Upon completion of the request service, a Record Set object is returned. Some interfaces allow you to manipulate the set of records obtained even after the connection is closed, and some require the presence of an active connection. If actions are performed as part of a transaction, the latter is usually limited to the context of the specific connection, which must remain open until at least the completion of the transaction.
In many environments, the opening of a dedicated connection is associated with the expenditure of strictly limited resources, so the so-called connection pools are used. In this case, the application does not open and close the connection, but requests it from the pool and releases it when it is no longer required. Today, support for a pool of connections is provided by most computing platforms, so the need for an independent implementation of such a structure rarely arises. If you still have to do this, first of all find out whether the use of a pool really improves system performance. Often, the environment is able to provide faster creation of a new connection than reusing a connection from the pool.
Platforms that support the connection pooling mechanism often hide the latter through additional interfaces, so the operations of creating a new connection object and selecting an object from the pool for an application developer look completely identical. Similarly, closing a connection in reality can mean returning the connection to a shared pool that is available for other processes. This kind of encapsulation is certainly a positive decision. The terms “opening” and “closing” will be used below, but keep in mind that in a particular situation they can mean, respectively, “seizing” the connection from the pool and its “release” with returning to the pool.
It doesn't matter how the connections are made, but they need to be properly managed. Since, as already noted, in this case we are talking about expensive computational resources, the connections should be closed immediately upon completion of their use. In addition, if a transaction apparatus is used, it is necessary to ensure that each command within a particular transaction is activated through the mediation of the same connection object. The most general recommendation is this: you should explicitly request the connection object using a call to the pool or connection manager, and then refer to this object in each command addressed to the database; after use the object must be closed. But how to guarantee that the links to the connection object are present where necessary, and do not forget to close the connection at the end of the work.
The solution to the first part of the problem is to transfer the connection object to any command in the form of an explicitly specified parameter. Unfortunately, it may turn out that the connection object will not be passed to a single method located in the call stack a few levels lower, but present in all sorts of method calls. In this situation, it is advisable to recall the registry. Since you probably do not want the connection to use several computational streams, it is necessary to use the variant of the registry of the level of one stream.
Even if you are not as forgetful as I am, then in this case you will agree that the requirement
the explicit closure of the connections is rather cumbersome, since it is too easy to disregard, which, of course, is unacceptable. The connection cannot be closed even after the execution of each command, since the very first attempt to do this within a transaction will lead to its rollback.
Memory, as well as connections, is one of the resources that should be returned to the system immediately upon completion of their use. In modern development environments, memory management and garbage collection functions are automatic. Therefore, one way to close a connection is to trust the garbage collector. With this approach, the connection is closed if during the garbage collection, the connection object itself and all the objects that refer to it are disposed of. Conveniently, the same familiar memory management scheme is used here. However, there is a problem: the connection is closed only when the garbage collector actually utilizes memory, and this can happen much later than the last link that addresses the connection object, i.e. in anticipation of closing, he will spend a lot of time. There will be a similar problem or not, is largely determined by the features of the development environment that you use.
If we talk more broadly, I would not rely too much on the garbage collection mechanism. Other schemes - even with forced closure of connections - seem more reliable. However, garbage collection can be considered a kind of insurance option: as they say, better later than never.
Since connections logically translate into transactions, a convenient strategy for managing them is to treat the connection as an integral attribute of the transaction: it opens at the beginning of the transaction and closes upon completion of commit or rollback operations. The transaction knows which connection it interacts with, and therefore you can focus on the transaction without worrying about the connection as such. Since the completion of a transaction usually has a more “visible” effect than the completion of the connection, you will hardly forget to fix it (and if you forget, then believe me, quickly think about it). One of the options for joint management of transactions and connections is demonstrated in a typical solution unit of work (Unit Of Work).
If we are talking about performing transactions outside of transactions (for example, reading obviously unchangeable data), for each operation you can use a "fresh" connection object. To cope with any problems related to the use of connection objects with short periods of existence, will help the scheme of the pool of connections.
If it is necessary to process data offline in the context of multiple records, you can open a connection to load information into the data structure, close it, and start processing. Upon completion, open a new connection, activate the transaction and save the results to the database. If you act according to such a scheme, you will have to take care of synchronizing the data with the information that was changed by other transactions during the processing of the contents of multiple records.
The features of connection management procedures are largely due to the parameters of specific development environments and applications

Comments
To leave a comment
Object oriented programming
Terms: Object oriented programming