Lecture
Domain Model (supertype layer). A type that serves as a superclass for all classes of its layer. Quite often, the same methods are duplicated in all objects of the layer. To avoid repetition, all common behavior can be put into the supertype layer.
Operating principle
The concept of a supertype layer, and therefore the typical solution itself, is extremely simple. All that is required of you is to create a superclass for all objects of the layer (for example, the class Domainobject, which is the superclass for all domain objects in the domain model). After that, all general behavior, like saving and processing identification fields, can be placed in the created superclass.
If there are objects of several different types in the application layer under consideration, it may be necessary to create several layer supertypes.
Purpose
The supertype of a layer is used when all objects of the corresponding layer have some common properties or behavior. Since objects in my applications have many similarities, the use of a supertype may well become a habit.
Separated Interface. It assumes the placement of the interface and its implementation in different packages.
As the system develops, there may be a desire to improve the structure of the latter, reducing the number of dependencies between its parts. Managing dependencies is much more convenient if the classes are grouped into several packages. By grouping, you can set rules that determine whether classes in one package can access classes in another package, such as the rule that domain layer classes should not call view layer class methods.
Despite this, the client may need to make method calls that contradict the general structure of dependencies. In this case, it makes sense to use a typical solution separated interface, defining an interface in one package, and implementing in another. Thus, the client who needs to establish communication with the interface will remain completely independent of its implementation.
Operating principle
The essence of this typical solution is very simple. It is based on the fact that the implementation depends on its interface, but not vice versa. This means that the interface and its implementation can be placed in different packages, and the package containing the implementation will depend on the package containing the interface. All other application packages may depend on the package containing the interface, and it does not depend on the package containing the implementation.
Of course, for such an application to work at runtime, the interface must have some implementation. To do this, you can use a separate package that will bind the interface and implementation at compile time, or you can link them during application setup.
The interface can be placed in a client package or in a separate package. If the implementation has only one client or all of the implementation clients are in one package, the interface can be placed directly in the client package. In this regard, it is useful to think about whether the developers of the client package are responsible for defining the interface? Placing the interface in the client package indicates that the package will receive calls from all packages containing an implementation of this interface. Thus, if you have several client packages, it is better to place the interface in a separate package (see Figure 3.1). It is recommended to do this also when the interface definition is not the responsibility of the client package developers (for example, when the interface interface developers are responsible for its implementation).
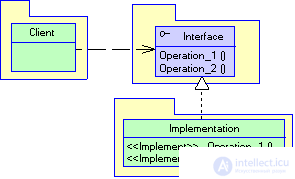
Figure 3.1 Placing the interface in a separate package.
In addition, the developer of the separated interface should choose which programming language tools should be used to describe the interface. It seems that when using languages like Java and C # containing special interface constructions, it is easiest to use the interface keyword. Oddly enough, this is not always a good choice. It is often better to use an abstract class as an interface to allow for common, but optional behavior.
The most annoying thing about using a split interface is creating an instance of the implementation. As a rule, to create an instance of an implementation, an object must "know" about the class of the latter. Often, a separate factory object (factory object) is used as such an object, the interface of which is also implemented as a separate interface. Of course, the factory object should depend on the implementation of the interface, so an additional module is used to ensure the most “painless” communication. The latter not only provides no dependencies, but
and allows you to postpone the decision on the choice of implementation class until the system is configured.
As a simpler alternative to an additional module, you can offer the use of another package that knows both the interface and the implementation that will create instances of the necessary objects during system startup. In this case, instances of all objects using the separated interface, or the corresponding factory objects, can be created at the time the application is started.
Purpose
The separated interface is used to avoid dependencies between the two parts of the system. Most often, this need arises in the situations described below.
Load on Demand (Lazy Load) An object that does not contain all the required data, but can load it if necessary.

Figure 3.2. Download data on demand (example)
Loading data into RAM should be organized in such a way that when loading an object of interest to you, other related objects are automatically extracted from the database. This greatly facilitates the life of a developer who would otherwise have to prescribe the loading of all related objects manually.
Unfortunately, such a process can take on formidable forms, if loading a single object entails loading a huge amount of objects associated with it — a highly undesirable situation, especially when you only needed a few specific records.
A typical load-on-demand solution interrupts the loading process, leaving the corresponding label in the object structure. This allows you to download the necessary data only when they are really needed.
Operating principle
There are several ways to implement a load on the easiest of them - on-demand initialization. The main idea of this approach is that every time you try to access a field, it checks whether it contains a NULL value. IF a field contains NULL, the access method loads the field value and then returns it. This can be implemented only if the field is self-encapsulated, i.e. if such a field is accessed only by means of a get-method (even within the class itself).
Using the NULL value is very convenient as a sign of an unloaded field. The only exceptions are situations where NULL is a valid value of a loaded field.
Purpose
When deciding whether to use load on demand, you need to consider the following: how much data you need to retrieve when loading a single object and how many database calls will be needed for this. It makes no sense to use load on demand to extract the value of the field stored in the same line as the rest of the object; in most cases, downloading data for one call will not lead to additional costs, even if we are talking about large fields.
Generally speaking, the application of load on demand should be considered only when access to the field value requires additional access to the database. In terms of performance, the use of load on demand affects the point at which the necessary data will be obtained. Often, all data is conveniently retrieved through a single call to the database, in particular, if this corresponds to a single interaction with the user interface. Thus, an on-demand download is best accessed when a separate database access is needed to retrieve additional data and when the extracted data is not used together with the main object.
The application of load on demand greatly complicates the application, so I try to resort to it only when it really can not do without it.
Record Set. Presentation of tabular data in memory.
Over the past 20 years, the main method of long-term data storage has been relational database tables. The presence of hot support from large and small producers of databases, as well as the standard (in principle) query language led to the fact that almost every new development relies on relational data.
On the crest of the success of relational databases, the software market has been replenished with a mass of infrastructures designed to quickly build user interfaces. All of these infrastructures are based on the use of relational data and provide a set of controls that make it much easier to view and manipulate data without requiring writing cumbersome code.
Unfortunately, these tools have one major drawback. Providing the ability to easily display and perform simple updates, they do not contain normal elements to which business logic could be placed. The presence of any verification rules, in addition to the simplest “is the data correct?”, As well as any business rules and calculations are simply not provided here. Developers have no choice but to put such logic into the database as stored procedures or inject it directly into the user interface code.
A typical solution of multiple records greatly simplifies the life of developers by providing a data structure that is stored in RAM and exactly resembles the result of an SQL query, but can be generated and used by other parts of the system.
Operating principle
Usually a lot of records do not have to construct yourself. As a rule, such classes are attached to the software platform used. An example of this is the ADSO.NET library's DataSet objects and the JDBC library's RowSet objects.
The first key feature of the set of records is that its structure exactly copies the result of the query to the database. This means that you can use the classic two-tier approach of querying and placing data directly into the corresponding user interface elements with the same advantages that similar two-tier tools provide. The second key feature is that you can create your own set of records or use a set of records resulting from a database query and easily manipulate them in the code of the domain logic.
Despite the availability of ready-made classes for implementing multiple records, you can create them yourself. However, it should be noted that this typical solution makes sense only if there are user interface tools for displaying and reading data, which also have to be created independently. In any case, building a list of collections, which is very common in dynamically typed scripting languages, can be mentioned as a good example of the implementation of multiple records.
When working with multiple records, it is very important that the latter be easily disconnected from the data source. This allows you to transfer multiple records over the network without worrying about having a connection to the database. The need to disconnect leads to the obvious problem: how to update multiple records? More and more platforms implement a number of records in the form of a unit of work (Unit of Work,), so that all changes to multiple records can be made in a detached mode and then recorded in the database.
Explicit interface
Most implementations of multiple records use an implicit interface. In this case, to extract the required information from a set of records, you need to call a generic method with an argument that indicates which logs are needed. For example, to get information about a passenger who has booked a ticket for a specified flight, you need to use an expression like aReserva-
tion [" passenger"] . The use of an explicit interface requires the implementation of a separate Reservation class with specific methods and attributes, and the extraction of passenger information is performed using aReservation expressions. passenger.
Implicit interfaces are extremely flexible. A universal set of records can be used for any kind of data, which eliminates the need to write a new class when defining each new type of record set. Despite these advantages, implicit interfaces are a highly controversial decision. How to find out which word to use in order to get to the information about the passenger who booked the ticket is “passenger”, “guest” (“client”) or, maybe, “flyer” (“flying” )? The only thing that can be done is to “comb” all the source code of the application in search of places where the booking objects are created and used. If I have an explicit interface, we can open the definition of the class Reservation and see what property is needed.
This problem is even more critical for statically typed programming languages. To find out the name of the passenger who booked the ticket, you will have to resort to the expression
(( Person) aReservation [" passenger"]). lastNamezh
Since the compiler loses all type information, you must manually specify the data type to extract the necessary information. In contrast, an explicit interface saves type information, so you can use a much simpler expression to extract the passenger's last name:
aReservation. passenger. lastName .
In the ADO.NET library, the ability to use an explicit interface is provided by strongly typed DataSet objects — generated classes that provide an explicit and fully typed interface to multiple records. Since a DataSet object can contain many tables and relationships in which they are located, strongly typed DataSet objects include properties that use information about the relationships between tables. The generation of DataSet classes is based on XML Schema Definition (XSD).
Unit of Work. Contains a list of objects covered by a business transaction, coordinates the recording of changes to the database and solves the problems of concurrency.
When extracting data from the database or writing updates to it, it is necessary to keep track of what has been changed; otherwise, the changes made will not be saved to the database. Similarly, created objects must be inserted, and deleted objects must be deleted. Of course, changes to the database can be made with each change in the content of the object model, but this will inevitably result in a huge number of small calls to the database, which will significantly reduce performance. Moreover, the transaction must remain open throughout the entire session of interaction with the database, which is in no way applicable to a real business transaction covering multiple requests. Finally, you have to keep track of the readable objects in order to prevent data inconsistencies.
A typical solution is a unit of work that allows you to control all actions carried out within a business transaction that are somehow connected to the database. Upon completion of all actions, it determines the final results of the work, which will be entered into the database.
Operating principle
Databases are needed to make changes to them: add new objects or delete or update existing ones. A unit of work is an object that tracks all such actions. As soon as you start doing something that can affect the contents of the database, you create a unit of work that should monitor all changes that are made. Each time you create, modify, or delete an object, you report this unit of work. In addition, it should be reported which objects were read from the database in order to prevent their inconsistency.
Когда вы решаете зафиксировать сделанные изменения, единица работы определяет, что ей нужно сделать. Она сама открывает транзакцию, выполняет всю необходимую проверку на наличие параллельных операций (с помощью пессимистической автономной блокировки (Pessimistic Offline Lock [4]) или оптимистической автономной блокировки (Optimistic Offline Lock [4])) и записывает изменения в базу данных. Разработчики приложений никогда явно не вызывают методы, выполняющие обновления базы данных. Таким образом, им не приходится отслеживать, что было изменено, или беспокоитьсяо том, в каком порядке необходимо выполнить нужные действия, чтобы не нарушить целостность на уровне ссылок, - единица работы сделает это за них.
Разумеется, чтобы единица работы действительно вела себя подобным образом, ей должно быть известно, за какими объектами необходимо следить. Об этом ей может сообщить оператор, выполняющий изменение объекта, или же сам объект.
Purpose
Основным назначением единицы работы является отслеживании действий, выполняемых над объектами домена, для дальнейшей синхронизации данных, хранящихся в оперативной памяти, с содержимым базы данных. Если вся работа выполняется в рамках системной транзакции, следует беспокоиться только о тех объектах, которые вы изменяете. Конечно же, для этого лучше воспользоваться единицей работы, однако существуют и другие решения.
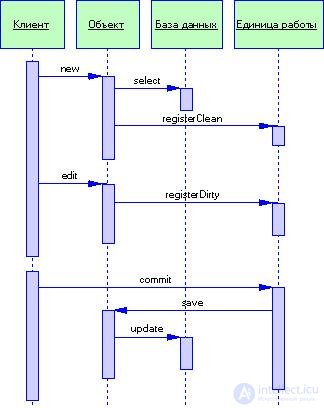
Рисунок 3.3 Регистрация изменяемого объекта
Пожалуй, наиболее простая альтернатива - явно сохранять объект после каждого изменения. Недостатком этого подхода является необходимость большого количества обращений к базе данных; например, если на протяжении выполнения одного метода объект был изменен трижды, вам придется выполнять три обращения к базе данных, вместо того чтобы ограничиться одним обращением по окончании всех изменений.
Во избежание многократных обращений к базе данных запись всех изменений можно отложить до окончания работы. В этом случае вам придется отслеживать все изменения, которые были внесены в содержимое объектов. Для реализации подобной стратегии в код можно ввести дополнительны переменные, однако учтите: если переменных слишком много, они становятся неуправляемыми. Переменные хорошо использовать со сценарием транзакции, но они совсем не подходят для модели предметной области.
Вместо того чтобы хранить измененные объекты в переменных, для каждого объекта можно создать флаг, который будет указывать на состояние объекта - изменен или не изменен. В этом случае по окончании транзакции необходимо отобрать все измененные объекты и записать их содержимое в базу данных. Удобство этого метода зависит от того, насколько просто находить измененные объекты. Если все объекты находятся в одной иерархии, вы можете последовательно просмотреть всю иерархию и записать в базу данных все обнаруженные изменения. В свою очередь, более общие структуры объектов, в частности модель предметной области, просматривать гораздо труднее.
The great advantage of a unit of work is that it stores all data about changes in one place. Therefore, you do not have to memorize a sea of information, so as not to lose sight of all changes to objects.
Feature of .NET implementation
В .NET для реализации единицы работы используется объект DataSet, лежащий в основе отсоединенной модели доступа к данным. Последнее обстоятельство немного отличает его от остальных разновидностей шаблона. В среде .NET данные загружаются из базы данных в объект DataSet, дальнейшие изменения которого происходят в автономном режиме. Объект DataSet состоит из таблиц (объекты DataTable), которые, в свою очередь, состоят из столбцов (объекты DataColumn) и строк (объекты DataRow). Таким образом, объект DataSet представляет собой "зеркальную" копию множества данных, полученного в результате выполнения одного или нескольких SQL-запросов. У каждой строки DataRow есть версии (Current, Original, Proposed) и состояния (Unchanged, Added, Deleted, Modified). Наличие последних, а также тот факт, что объектная модель DataSet в точности повторяет структуру базы данных, значительно упрощает запись изменений обратно в базу данных.

Comments
To leave a comment
Object oriented programming
Terms: Object oriented programming