Lecture
The human vocal apparatus is an acoustic system consisting of the oral and nasal canals, excited by quasiperiodic pulsations of the vocal cords and turbulent noise. Turbulent noise is generated by pushing air through constrictions in certain areas of the vocal tract. The voice apparatus , excited by these sources, acts as a linear filter with time-varying parameters, the output of which produces a speech signal. At short time intervals, the speech signal can be approximated by convolving the excitation signal with the impulse response of the vocal tract. Figure 1. shows a simplified model of the formation of a speech signal [15,17]. In accordance with this model, vocalized (voiced) sounds are generated using a pulse sequence generator, and fricative (noise) sounds are generated using a random number generator.

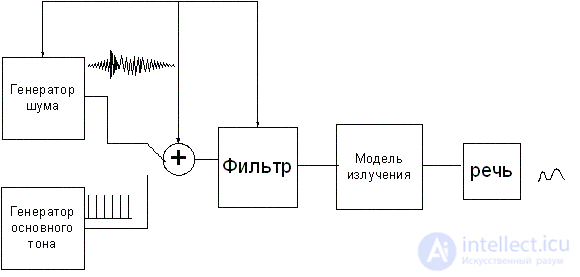
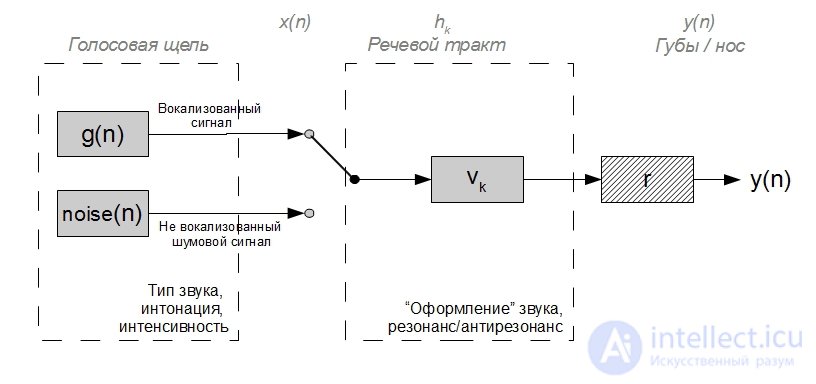
Fig 1. Digital model of speech signal generation.
The pulse repetition period at the output of the pulse sequence generator corresponds to the main period excitement of vocal cords. A random number generator generates a noise signal with a uniform spectral density. A digital filter with variable parameters approximates the transfer properties of the vocal tract. On the time interval of the order of ms, the shape of the vocal tract does not change, therefore, the characteristics of the CF in this interval remain constant. The amplitude of the input signal of the digital filter is determined by the gain.
Voiced sounds are quasi-periodic signals (Fig. 4.5, a), the harmonic structure of which is clearly visible on the graph of the short-term spectrum. Fricative sounds are random (Fig. 4.5, b) and occupy a wider frequency range. The energy of vocalized speech sounds is much greater than the energy of fricative sounds. The structure of the short-term spectrum of vocalized parts of speech (Fig. 4.5, a) is characterized by the presence of slowly varying and rapidly changing components. The rapidly changing or pulsating component is caused by quasiperiodic oscillations of the vocal cords. Slowly changing component is associated with the eigen (resonant) frequencies of the vocal tract - formants . On average there are formant. The first three formants have a significant impact on the synthesis and perception of vocalized parts of speech. Their frequencies are lower. Formants with higher frequencies affect the synthesis and presentation of fricative sounds.
The considered digital model of speech signal formation is characterized by the following parameters : the presence of a classifier of voiced and unvoiced sounds (tone / noise switch), the period of the fundamental tone, gain, parameters (coefficients) of the ZF.
Numerous ways of representing speech signals are based on the considered model: from the simplest periodic sampling of the speech signal to the estimates of the parameters of the model shown in Figure 1.
The choice of a particular way of representing a speech signal is determined by the problem to be solved, which are divided into three classes:
1. The first class includes tasks related to speech analysis. Speech analysis is an integral part of speech recognition systems, as well as voice recognition systems for speakers.
2. The second class includes tasks related to speech synthesis. according to the text. Tasks of this type arise in numerous information and reference systems.
3. In tasks related to the third class, an analysis of the voice signal compression system is performed in order to transmit speech over computer networks or traditional communication lines.
One of the promising areas of speech processing is speech recognition systems on the Internet. In this case, the network user, using the telephone, can connect to a speech recognition program that resides on the server and translates the dialogue into commands of the Web server. This allows access to the distributed information resources of the network by telephone. This technology, which uses methods of digital signal processing, is based on the use of a special programming language of Web-servers VoxML (Voice Markup Language).

Comments
To leave a comment
Methods and means of computer information technology
Terms: Methods and means of computer information technology