Lecture
•Quality
• What are ways to achieve quality?
• Code quality in terms of design
• OOP / OOD / OOA Principles
Iron triangle Scope of work (features, functionality, quality, etc.) Time (schedule, timeline) Money (budget, resources) Iron triangle, or management triangle. Its meaning is that the restrictions on the scope of work, deadlines and budget must be reasonable and need to be managed (balanced). Where is the quality?

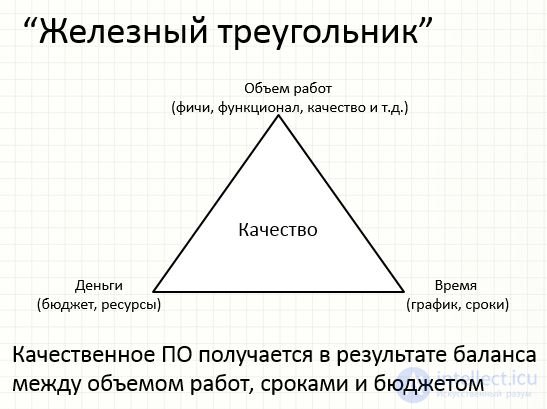
Iron triangle Scope of work (features, functionality, quality, etc.) Time (schedule, terms) Money (budget, resources) High-quality software is obtained as a result of a balance between the volume of work, terms and budget Quality
What are these triangles?
Quality Code Values
Extensibility, flexibility (extensibility, agility)
Maintainability
Simplicity
Readability, clarity (readability, clarity)
Testability

• Organizational
–XP (eXtreme Programming)
–Code review
–Project management, methodology,
–Utilities: StyleCop, FxCop, Code Analysis
–Requirements ...
• Technical
–Unit tests
–TDD, Defensive programming style
–OOP / OOD, principles
•Training
• External - programmer practices
–Pair programming
–Static code analysis
–Code review
–Unit-tests, TDD / BDD
• Internal - correct design and code refactoring as a way to turn bad code into a better one.
–OOP / OOD, principles,
–Programming style
Code review (eng. Code review) or code inspection (eng. Code inspection) - systematic verification of the source code of the program in order to detect and correct errors that went unnoticed in the initial phase of development. The purpose of viewing is to improve the quality of the software product and improve the skills of the developer.
In the code inspection process, problems such as errors in string formatting, race conditions, memory leaks and buffer overflows can be found and fixed, which improves the security of the software product. Version control systems make it possible to conduct joint code inspection. In addition, there are special tools for joint code inspection.
Software for automated code inspection simplifies the task of viewing large pieces of code by systematically scanning it to detect the most known vulnerabilities.
StyleCop, FxCop, Code Analysis, Ndepend The goal is to automate the review code and pay attention to common errors and slippery areas. Ideally, inject a stat. analysis in CI (build process)
Project management directly affects results and job satisfaction - Chaotic management = low quality (eg Cowboy coding)
Pair programming
Comprehensive code review
Unit Tests for All Code (TDD)
YAGNI, do not write what is not needed
Mutable requirements
Frequent communication with the customer and in the team
No stat utilities. analysis will not replace people
Allows you to write quality code
Enhances communication
Improves team
Pair programming promotes

Unit tests - allow you to control the compliance of the code with the intended behavior.
TDD - an approach to writing code starting with tests. "Tests ahead"
Refactoring is a controlled process of improving a code, without writing new functionality. Result refactoring is a clean code and simple design.
Defensive programming Using sturgeon (asserts)
Using Code Contracts
Asserts or contracts as mini unit tests if something goes wrong
Defensive coding is a style of writing computer programs designed to make them more fault tolerant in case of serious functional deviations. Usually, such unplanned behavior arises due to the presence of bugs in the program, but it can be caused by completely different reasons: corrupted data, hardware failures, bugs that arise in the program during its refinement. Caught in a critical situation, the code written in a protective style, trying to take the most reasonable measures with a slight decrease in performance. Also, such code should not allow the creation of conditions for the occurrence of new errors.
Story
I first encountered the term “defensive programming” in the book by Kernighan and Ritchie (The C Programming Language, 1st Edition). After a thorough search, I was unable to find earlier references to this term. It was probably coined by analogy with the “safe driving”, which was actively talked about in the early 1970s, several years before the appearance of the book by Kernigan and Ritchie.
The index to the K & R book indicates two pages on which this term is used. On page 53, it means writing code that prevents the occurrence of bugs, and on page 56 this term is understood a little differently: creating a code that reduces the likelihood of bugs on subsequent changes to the code during its revision. In any case, the term “defensive programming” has since been used in many books. Usually, it means ensuring that the code works even if there are bugs - for example, in the book The Pragmatic Programmer by Andrew Hunt and Dave Thomas (where “programming in a protective style” is described in the chapter “Pragmatic Paranoia”), as well as in other sources.
Differences in interpretation
Despite the fact that this term has been quite clearly understood over the past 20 years, its exact meaning has recently begun to blur as a result of the appearance of a number of articles (as a rule, which have not passed peer review) on various websites and blogs. For example, in the Wikipedia article of the same name and on several sites that link to it, “defensive programming” is interpreted as an approach to handling errors. Of course, error handling and defensive programming are related concepts, but they are definitely not synonymous, just as one is not a special case of the other (more on this - below).
Another classic and frequently cited article entitled simply “Defensive Programming” has a very high rating on Codeproject.com. This is in its own way a remarkable and informative article, but it does not tell strictly about defensive programming, but, according to the author himself, “about methods that are useful in catching program errors”. As will be shown below, defensive programming has the opposite effect - it does not catch errors, but rather hides them. The mentioned article from Codeproject.com covers many topics and should be renamed, for example, in “Good Coding Practices”.
Comparison of error handling and security programming
Many developers do not clearly understand the difference between error handling and defensive programming. I will try to explain it.
In error handling, situations are found and corrected in which something goes wrong, and you know that such a situation is possible, although unlikely. On the contrary, defensive programming is an attempt to take into account the consequences of such problems, which at first glance seem to be "impossible." Such “impossible” problems fall into two categories; it is quite possible that therefore some confusion arises.
The problems of the first category are impossible in some circumstances, but quite likely in others. For example, if we have a private function in a particular module or program, we can guarantee that valid arguments will always be passed to it. But if the same function is part of a public library, then you cannot be sure that it will ever receive bad data. If the function is private, then it is advisable to use defensive programming to ensure that the function “will act rationally” even in such a situation that seems impossible. If the function is publicly available, you can add error handling to it in case that invalid data will be passed to it.
So, our chosen strategy — defensive programming or explicitly adding error handling — depends on the scope of a particular program. We will talk more about this in the "Scope" section.
The second problem is that borderline cases are possible in which the possibility or impossibility of the occurrence of certain conditions is debatable. Consider the following set of scenarios that may occur in the program if it receives invalid data:
At what point can we be sure that the data may not be invalid? I believe that the case in which the file with invalid data continues to generate the correct checksum is absolutely impossible (see scenario 6). However, if the data is of increased safety criticality, it is necessary to take into account the probability that the file has been specially modified to obtain the “correct” checksum. In this case, you will have to use a cryptographic checksum, for example SHA1.
However, I know that in many programs it is assumed that all files with binary data are certainly valid (scenario 4 or 5). But at the same time, there are often programs that start to behave unpredictably if they receive damaged files with binary data.
I think anyone will agree that you can be quite sure that the local variable that you just wrote down (scenario 9) will not change. However, in the case of a hardware error, intentional counterfeit, or other reasons, such a variable may unexpectedly assume an incorrect value.
So, it is not always clear in which cases you need a special code for handling errors, and in which you will need sufficient protective programming.
Example
A classic example of defensive programming can be found in almost any program ever written in C. Speech on cases where the termination condition is written not as a test for inequality (<), but as a test for inequality (! =). For example, a typical loop is written like this:
size_t len = strlen (str);
for (i = 0; i result + = evaluate (str [i]);
not like this:
size_t len = strlen (str);
for (i = 0; i! = len; ++ i)
result + = evaluate (str [i]);
Obviously, both fragments should work in a similar way, since the variable 'i' can only increase and under no circumstances can become unequal 'len'. Why, then, are the cycle termination conditions always written only on the first sample, and not on the second one?
First, the consequences of the occurrence of the "impossible" conditions are very detrimental and, probably, can lead to all sorts of unpleasant consequences in the finished program - for example, an infinite loop or a violation of memory access. Such an “impossible” condition may well arise in some situations:
for (i = 0; i! = len; ++ i)
{
while (! isprint (str [i])) // pathological code change, under which 'i' may never be equal to 'len'
++ i;
result + = evaluate (str [i]);
}
Of course, the last few cases caused by software errors are most common. That is why defensive programming is often associated with protection against bugs.
Culture C
There are two more aspects of the C language that determine how and when security programming is used. I mean, firstly, the emphasis C on the efficiency of the code and, secondly, the approaches to error handling used here.
Let's start with efficiency. One of the basic prerequisites for working with C is that the programmer knows what he is doing. Language does not protect us from possible mistakes, while others at least try to do it. For example, on C, when writing data, it is easy to throw them outside the array — but if border checks are used when performing access to the array (performed by the compiler), the program will run slower even with completely safe code.
Since C focuses on efficiency, defensive programming is applied only in cases where it does not have a negative impact on performance or if such an impact is minimal. A typical example is given above, since the “less” operator is usually not inferior in speed to “not equal”.
The second aspect is the organization of error handling in C. Usually, errors in C are processed using returned error values. Error handling often plays a decisive role in C code, so potential error conditions are ignored if they appear unlikely. For example, no one will ever think of checking the return value of an error from printf (). In fact, error conditions are sometimes ignored even when this should not be done, but this is a topic for another discussion.
So, if the presence of "unlikely" errors is usually not checked, it is advisable to handle the "impossible" conditions, because if such unlikely errors occur, they will significantly complicate the whole processing process. Of course, in exception-handling languages, many such problems are easily resolved by issuing a program exception.
Application area
Many controversial opinions about defensive programming arise from the fact that its scope is not always clearly delineated. For example, if we have a function that accepts a string parameter (const char *), then we would like to assume that it will never be passed a NULL pointer, since this makes almost no sense. If this is a private function, then you can in all cases guarantee the absence of NULL transmission; but if the function can be applied not only by you, then NULL cannot be counted on such an absence, it is better to indicate in the documentation that the NULL pointer should not be used here.
In any case, even if you consider the condition impossible, it will be wise to insure against it with a protective course. Many functions simply return if they are unexpectedly passed NULL. Again, this case is different from error handling, since no error value is generated.
Therefore, when discussing defensive programming, you should always consider the scope of the code in question. Just this moment is not taken into account in the Wikipedia article on this topic.
Symptoms
When working with a program that contains errors, the symptoms of defensive programming are noticeable quite often (but can be mistaken for control errors). I think anyone has seen programs that behave strangely: throw windows on the screen, ignore commands, and even display messages about an “unknown error.” Usually these phenomena are triggered by bugs and how the program tries to cope with the problems that have arisen.
Sometimes she succeeds, but more often the program simply crashes and does not work. In the worst case, it can imperceptibly cause huge damage - in particular, provoke data loss or damage. When I start to notice such strange phenomena, I usually immediately save the work and restart the program.
Security programming issues
So, now we quite clearly understand the main problem of defensive programming. Security programming hides from us the presence of bugs
Some people think this is good. Yes, it’s good for a ready-made program that is already in use - of course, we don’t want to pose problems to the user that he doesn’t even understand. On the other hand, if you just continue to work when something is already broken, it can end badly. Therefore, you need to try to somehow report the problem that has arisen - at least make an appropriate entry in the log file.
Much worse is that defensive programming hides errors at the stages of development and testing.I think no one thinks it's good. An alternative is to use an approach sometimes referred to as “aggressive programming” or “fail fast”. Such approaches are aimed precisely at the rapid manifestation of errors, and not at silence.
Я применяю защитное программирование так, что в готовых сборках остается возможность для обработки неожиданных или условно невозможных ситуаций. Но я также добавляю контрольные операторы для проверки невозможных ситуаций — такие операторы нужны, чтобы в программу не проникли баги. Кроме того, во время тестирования я работаю преимущественно с отладочной сборкой (где уже используются такие утверждения), проверяя готовый продукт уже при окончательном приемочном тестировании. Для самых критических моментов я также явно добавляю код для обработки ошибок, поскольку в готовых сборках контрольные операторы удаляются.
Exercise
Наконец, предлагаю вам пищу для размышлений. В стандартной библиотеке C есть функция, принимающая строку цифр и возвращающая целое число. Эта функция называется atoi.
Если вы не знакомы с atoi(), уточню, что она не возвращает никаких кодов ошибок, но останавливается, как только ей встречается первый же неожиданный символ. Например, atoi("two") просто возвращает нуль.
Является ли поведение atoi() примером защитного программирования? Why?
К его появлению приводит быстрая и бездумная разработка Когда мы понимаем, что можем написать дизайн лучше, но в силу причин не делаем этого – мы откладываем долг. Выплачивать придется рефакторингом
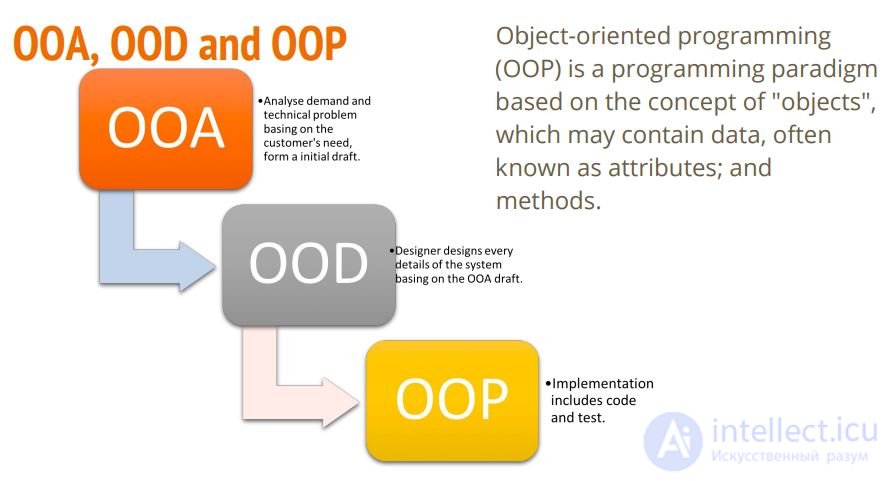
Теория. Гради Буч. Объектно-ориентированный анализ и проектирование.
В этой книге есть определения ООА, ООД, ООП. Краткое определение трудно воспринимается в отрыве от книги:
Quote:
Объектно-ориентированный анализ - это методология, при которой требования к системе воспринимаются с точки зрения классов и объектов, выявленных в предметной области.
Объектно-ориентированное проектирование - это методология проектирования, соединяющая в себе процесс объектной декомпозиции и приемы представления логической и физической, а также статической и динамической моделей проектируемой системы.
Объектно-ориентированное программирование - это методология программирования, основанная на представлении программы в виде совокупности объектов, каждый из которых является экземпляром определенного класса, а классы образуют иерархию наследования.
Practice. Крэг Ларман. Применение UML 2.0 и шаблонов проектирования
Фаза 1. OOA – Объектно-ориентированный анализ. (ОСМЫСЛЕНИЕ)
пример 1 Смотришь на постановку задачи, обдумывая, ну и как же сделать эту фиговину. Пытаешься понять, из чего оно в общем и целом состоит и могло бы быть, читая описание, рисуешь всякие там стрелочки, классики, объектики и прочие комментарии в вольном стиле и мысли, приходящие в голову. Когда процесс надоедает (кончается криатифф), переходишь к следующему этапу.
пример 2 Менеджер привел заказчика. Заказчик хочет сферического коня в вакууме. Руководитель берет тимлида, ведущего программиста и все трое со всех сил стараются понять, чего же он хочет. Далее уже без заказчика гл. программист сидит и доооолго думает, что это будет за зверь, как же этот конь будет выглядеть, какие части (не путать с калассами) будут в проекте.
После выделения частей коня решено, что он будет состоят из трех частей: сервер-служба, гуй-клиент-настройщик, веб-морда.
Пример 3 OOA – анализ основанный на юз-кейсах. Прикинуть как пользователи будут вести себя с софтом и описать эти случаи. Получится список сценариев, которые ясно раскроют картину происходящего.
Фаза 2. OOD – Объектно-ориентированное проектирование (UML ДИАГРАММА КЛАССОВ)
Пример 1 Читаешь все каля-маля, нарисованные во время этапа анализа и блуждания по сайтам с котиками, в надежде, что тебя посетит гениальная идея. Пытаешься весь поток сознания хоть как-то систематизировать, разложив его по классам и объектам, продумываешь связи между ними, как они типично будут взаимодействовать друг с другом. Что-то придет само, что-то придется высидеть, а то и захочется нарисовать что-то совершенно абстрактное и вроде как бесполезное, но исключительно стильно выглядящее. Понимаешь, что не клеится. Мнешь лист бумаги, кидаешь в угол комнаты или коллегу по работе. Берешь другой, рисуешь заново, классы, связи, диаграммы стандартные и в свободном стиле, напоминающие инструкции по перебору двигателей. Когда понимаешь, что лучше ты все равно уже не придумаешь, переходишь к фазе внедрения в жизнь.
Пример 2 Тимлиду поручено сделать сервер и он начинает думать в сторону того, как будет устроен сервер, рисует одному ему понятные стрелочки и продумывает очень иерархию частей этого сервера и их взаимодействие.
Пример 3 ООD – на основе полученных сценариев выявляются существительные (классы) и глаголы (операции/методы). Все это можно красиво оформить в UML. И переходить к ООП.
Прочитав один раз книгу Крэг Ларман – UML 2.0…до сих пор использую этот подход при написании софта.
Фаза 3. OOP – объектно-ориентированное программирование (КОД НА КОНКРЕТНЫХЯЗЫКАХ ПРОГРАММИРОВАНИЯ)
Пример 1 Берешь свой любимый язык программирования (Ассемблер и HTML не подойдут – нету размаха), и претворяешь наскальные письмена с предыдущей фазы в жизнь – раскладываешь классы на составляющие, разбрасываешь их по файлам исходников, закручиваешь взаимные связи, тихо офигевая от того кошмара, который выходит, понимаешь, что все не так плохо, как кажется, а намного хуже, и ты себе поставишь памятник, если оно хоть когда-нибудь заработает. Пишешь кучу строк текста, попутно матерясь на непроинициализированные указатели, утекшие мегабайты памяти, из-за которых ты хотел нарастить себе оперативку уже до 2 гигов, копаешься в документации, и вот однажды оно оживает и начинает напоминать желаемый результат. Еще труда – и ты у финишной черты.
Затягиваешься сигаретой, выпиваешь бутылку вина, с благоговейным ужасом смотря на то, что ты сделал, понимая, что второй раз ты это не повторишь. Смотришь на себя в зеркало, играя бицепсами/скулами (нужное подчеркнуть) и говоришь себе “Ну какой же я молодец!”.
пример 2
Сижу я. Решаю, что "ConectionPool <>------ ClientProcessor" (агрегирование), при этом ClientProcessor будет наследником того-то и того-то... Рисую UML, показываю тимлиду. Кивает - делаю.
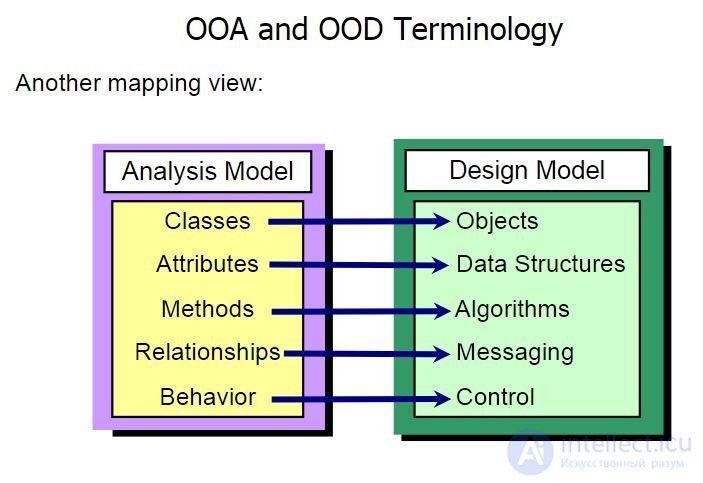
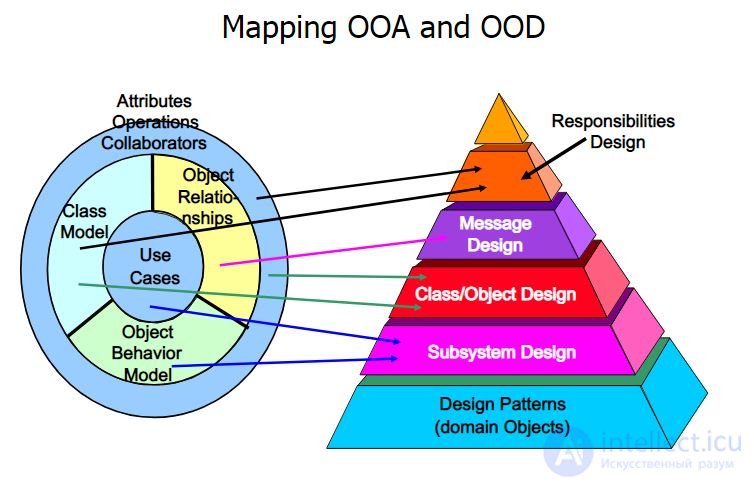
Принципы SOLID
Принципы GRASP
KISS = Keep it simple
DRY = Dont repeat yourself
YAGNI = You aint gonna need it
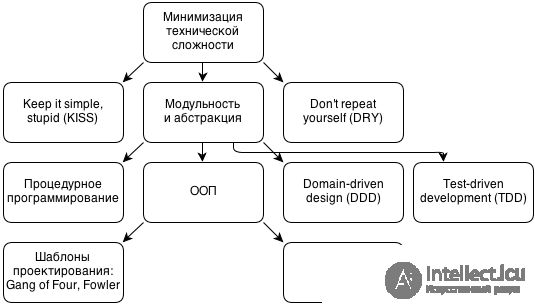
Почитайте статью и про ООП вообще. Это действительно довольно большая тема для одного ответа на данном ресурсе. Думаю, поняв концепцию ООП, что такое объект, в чем разница между объектом и классом, Вы придете к выводу, зачем и когда это нужно.
Но если вкратце: классы нужны для создания своих структур данных, которые будут содержать какую-то логику обработки. Вся логика хранится в описании класса, при этом оставляя в вызывающей программе лаконичные вызовы, без лишнего кода.
SOLID это свод пяти основных принципов ООП, введённый Майклом Фэзерсом в начале нулевых. Эти принципы — часть общей стратегии гибкой и адаптивной разработки, их соблюдение облегчает расширение и поддержку проекта.
Invented the principles of SOLID Robert Martin (Uncle Bob). Naturally, in his works he covers this topic.
The book “Principles, Patterns and Methods of Agile Development in the C # Language” 2011. Most of the articles that I have seen are based on this book. Unfortunately, it gives a vague description of the principles, which greatly affected their popularity.
Video site cleancoders.com. Uncle Bob in a joking way on the fingers tells what exactly the principles mean and how to apply them.
The book “Clean Architecture” 2017. Describes architecture built from bricks that satisfy SOLID principles. Gives a definition of structural, object-oriented, functional programming. Contains the best description of the SOLID principles I have ever seen.
SOLID is always mentioned in the context of OOP. It so happened that it was in OOP languages that convenient and safe support for dynamic polymorphism appeared. In fact, in the context of SOLID, OOP is precisely dynamic polymorphism.
Polymorphism makes it possible for different types to use the same code.
Polymorphism can be roughly divided into dynamic and static.
In addition to familiar languages like Java, C #, Ruby, JavaScript, dynamic polymorphism is implemented, for example,
SOLID principles advise how to design modules, i.e. building blocks of which the application is built. The purpose of the principles is to design modules that:
A module should be responsible for one, and only one, actor.
The old wording is:
Often it was interpreted as follows: A module should have only one duty . And this is the main misconception when meeting with the principles. Everything is a little trickier.
On each project, people play different roles (actor): Analyst, Interface Designer, Database Administrator. Naturally, one person can play several roles at once. This principle means that one and only one role can request changes in a module. For example, there is a module that implements some business logic; only the Analyst can request changes in this module, but not the DBA or UX.
For software modification.
The old wording is: without modifying it .
It can definitely enter into a stupor. How can you extend the behavior of a class without modifying it? In the current formulation, Robert Martin uses the concept of an artifact, i.e. jar, dll, gem, npm package. To extend the behavior, you need to use dynamic polymorphism.
For example, our application should send notifications. Using dependency inversion, our module declares only the interface for sending notifications, but not the implementation. Thus, the logic of our application is contained in one dll file, and the class of sending notifications that implements the interface is in another. Thus, we can, without modifying (recompiling) a module with logic, use various ways of sending notifications.
This principle is closely related to LSP and DIP, which we will look at next.
It has a complex mathematical definition that can be replaced by: Functions that use the base type should be able to use subtypes of the base type without knowing it .
A classic example of a violation. There is a base class Stack that implements the following interface: length, push, pop. And there is a descendant of DoubleStack, which duplicates the added items. Naturally, the DoubleStack class cannot be used instead of Stack.
This principle has a funny consequence: Objects that model entities are not required to implement the relationships of these entities . For example, we have integers and real numbers, and the integers are a subset of the real ones. However, double consists of two int: mantis and exponent. If int inherits from double, then a funny picture would turn out: the parent has 2 children.
The second example is Generics. Suppose there is a base class Shape and its descendants Circle and Rectangle. And there is a certain function Foo (List list). We believe that the List can be brought to the List. However, it is not. Suppose this cast is possible, but then you can add any shape to the list, for example, a rectangle. Initially, the list should contain only objects of the class Circle.
Make fine grained interfaces that are client specific.
The interface here is understood to be Java, C # interface. Interface separation facilitates the use and testing of modules.
Depend on abstractions, not on concretions.
What are top-level modules? How to determine this level? As it turned out, everything is very simple. The closer the module is to the I / O, the lower the module level. Those. modules working with BD, user interface, low level. And the modules that implement business logic are high-level.
What is module dependency? This is a link to the module in the source code, i.e. import, require, etc. Using dynamic polymorphism at runtime, you can reverse this relationship.
There is a Logic module that implements logic that should send notifications. The same package declares an ISender interface that is used by Logic. A lower level, another package is declared ConcreteSender, which implements the ISender. It turns out that at the time of compilation Logic does not depend on ConcreteSender. At runtime, for example, an instance of ConcreteSender is installed through Logic's constructor.
Separately, it is worth noting the frequent question “Why produce abstractions if we are not going to replace the database?” .
The logic is as follows. At the start of the project, we know that we will use a relational database, and this will definitely be Postgresql, and for searching - ElasticSearch. We do not even plan to change them in the future. But we want to postpone making decisions about what the table schema will be, what will be the indices, etc. until the moment it becomes a problem. And at this moment we will have enough information to make the right decision. We can also debug the logic of our application before, implement the interface, collect feedback from the customer, and minimize subsequent changes, because a lot of things are implemented only as stubs.
The principles of SOLID are suitable for projects developed on flexible methodologies, because Robert Martin is one of the authors of Agile Manifesto.
The principles of SOLID aim to reduce the change of modules to their addition and removal.
The principles of SOLID contribute to the postponement of technical decisions and the division of labor of programmers.
Like any tool, design principles need to be applied wisely.
There are two cases in which the application of design principles will lead to an increase in problems, and will not lead to anything good.
Yagni
Details - in response to the question "Does OCP and DIP (from SOLID) violate the principle of YAGNI?".
Design principles are designed to mitigate a specific development problem (yes, it is “mitigation”, but not a solution to the problem), while adding its own problems.
Since programmers sometimes invent problems for themselves, following (especially literally) the principles of design will lead to a misalignment of design without solving a real problem.
In other words, overreliance on design principles can lead to an over-complicated solution where this complexity is not needed.
"Over" -SOLID
Read more in the article "On the principles of design."
There are a number of typical pathological cases of using the SOLID principles:
Anti-SRP - The principle of vague responsibility. Classes are divided into many small classes, as a result of which the logic is spread over several classes / modules.
Anti-OCP - The principle of the factory of factories. The design is too general and extensible, there are too many levels of abstraction.
Anti-LCP - The principle of incomprehensible inheritance. The principle is manifested either in an excessive amount of inheritance, or in its complete absence, depending on the experience and views of the local chief architect.
Anti-ISP - The principle of thousands of interfaces. Interfaces of classes are broken into too many components, which makes them inconvenient for all customers to use.
Anti-DIP - The principle of inversion of consciousness or DI-brain. Interfaces are allocated for each class and are transmitted in batches through constructors. Understanding where the logic is located is almost impossible.
About the principles of SOLID in the network there is a lot of information. In some places - it is abstruse to the horror, in some - described in understandable human language. For some reason, recently I can not tolerate too abstruse explanations. In actual fact, I am convinced that a person who really knows what he is talking about can always explain things in “human” or in a more understandable language than is accepted in his Ph.D.
But not much has been written about the principles of GRASP, and much of what is written is an understanding poison with its cleverness. Of course the question is not simple. But the complexity is also not cosmic.
So, the first point - why these principles?
Object-oriented programming (OOP) - I would say that it is a set of basic concepts (abstraction, encapsulation, inheritance, polymorphism), constructs (classes, methods) and principles. OOP is a model, a generalized model of a part of a subject or object domain for programming the environment. This programming is a generalized model, an expression of the object model in terms of a programming language. And this model, like any other model, is consciously limited.
So, a huge part of the PLO is a set of principles. And here everything seems to be clear. But there are many principles. And different authors single out as basic sometimes similar, and sometimes different, principles, and surprisingly, all are correct.
Modeling is not difficult. The only problem is that we are still dealing with a model. And when objects (entities) are already created, then programming and design come into play. Objects must interact and the model must be flexible and simple. Here principles help us.
GRASP is a set of principles according to an expert such as Craig Larman, who wrote about them in her book - Applying UML and Patterns. place in history and, accordingly, the principles of GRASP, which is devoted to a small part of the book, too.
Perhaps they are not as popular as, say, the principles of SOLID, most likely, it seems to me, because they are more generalized. These principles are more abstract than GoF or SOLID templates.
So the principles of GRASP, or rather, not the principles, but the templates in the original. General Responsibility Assignment Software Patterns - this can be translated as - responsibility sharing patterns. The bottom line is that these are not strict patterns like those of GoF, it’s rather the meaning with which we endow objects. So the principles of distribution of shared responsibility fits more than patterns. Therefore, the title of the article is not GRASP templates, as it would be ideologically correct, but still the principles of GRASP.
GRASP identifies the following template principles:
Now let's look at each of them in order.
An information expert or just an expert is rather a responsibility. An expert can be any class. It's not even about design, but about awareness. Why do we need an information expert? Then, if an object owns all the necessary information for some operation or functionality, then it means that this object will either perform or delegate the execution of this operation.
So consider an example. There is a certain sales system. And there is a class Sale (sale). We need to calculate the total amount of sales. Then who will count the total amount of sales? Of course, the class is Sales, because it is he who has all the information necessary for this.
Creator or Creator - the essence of the responsibility of such an object is that it creates other objects. Immediately suggests an analogy with the factories. The way it is. Factories also have the responsibility - the Creator.
But there are a number of moments that should be fulfilled when we endow the object with the responsibility of the creator:
1. The creator contains or aggregates the created objects.
2. Creator uses created objects
3. The creator knows how to initialize the object being created.
4. The creator writes the created objects (I didn’t really understand this thing until the end)
Already heard somewhere, is not it? A controller or controller is an interlayer object between the UI logic and the object (business) logic of the application. We create a controller so that all calls from the UI are redirected to him and, accordingly, all UI data also receives through him.
Reminds MVC, MVP? And there is. This is essentially a MVP Presenter and a MVC controller. There is a difference between MVC and MVP, but this concerns only the directions of calls, well, this topic is of course a different conversation.
So, the controller answers the following question: “How should the UI interact with the domain logic of the application?” Or simply “How to interact with the system?”. This is what looks like a facade. The facade also provides easy access to the whole subsystem of objects. So here, the controller for UI is a kind of facade that provides access to the whole business logic subsystem.
Also known thing. Low Coupling or Low Connectivity. If the objects in the application are strongly related, then any change leads to changes in all related objects. And this is inconvenient and generates bugs. That's why they write everywhere that it is necessary that the code be loosely coupled and dependent on abstractions.
For example, if our class Sale implements the ISale interface and other objects depend on ISale, i.e. from abstraction, when we want to make changes regarding the Sale - we will only need to replace the implementation.
Low Coupling is found in SOLID principles in the form of - Dependency Injection. Now you can often hear such a principle. But the essence remains the same: “ Program on the basis of abstractions (interface, abstract class, etc.), and not implementations ”.
High cohesion or high cohesion - this relates to weak connectivity, they go together and one always leads to the other. It's like yin and yang, always together. The fact is that our classes when we conceive them have a single responsibility (Single resposibility principle), for example Sale (sale) has all the responsibilities that relate to sales, for example, as we already said, the calculation of the total amount - Total. But let's imagine that we made an oversight and brought to the Sale such responsibility as Payment. What happens? It turns out that some members of the class that deal with Sale will be closely enough connected with each other, and also members of the class who operate with Payment among themselves will be closely linked, but on the whole, the coherence of the SaleAndPayment class will be low, since in fact we are dealing with two separate parts in one whole. And it would be reasonable to refactor and divide the SaleAndPayment class into Sale and Payment, which will be closely related inside or otherwise linked.
So high coupling is a measure of the fact that we do not violate the single resposibility principle. Rather, high coupling is obtained by adhering to such a SOLID principle as single resposibility principle (SRP).
The main question that gives the answer is high cohesion - “How to keep objects focused on one responsibility, understandable, manageable, and as a side effect of having loosely coupled code?”. To separate them. This is described in more detail in chapter 17 of the book of Larman.
Pure Fabrication or pure fiction or pure synthesis. The essence of the fictional object. Such a principle is a hack. But without it in any way. An analogue can be the Service pattern in the DDD paradigm.
Sometimes, we are confronted with such a question: “Which object is to be given responsibility, but the principles of the information expert, high cohesion are not fulfilled or do not fit?”. Use a synthetic class that provides high adhesion. There is no way to figure it out without an example.
So - the situation. What class should save our Sale object to the database? Если подчиняется принципу “информационный эксперт”, то Sale, но наделив его такой ответственностью мы получаем слабую сцепленность внутри него. Тогда можно найти выход, создав синтетическую сущность – SaleDao или SaleRepository, которая будет сильно сцеплена внутри и будет иметь единую ответственность – сохранять Sale в базу.
Так как мы выдумали этот объект а не спроектировали с предметной области, то и он подчиняется принципу “чистая выдумка”.
Indirection или посредник. Можно столкнутся с таким вопросом: “Как определить ответственность объекта и избежать сильной связанности между объектами, даже если один класс нуждается в функционале (сервисах), который предоставляет другой класс?” Необходимо наделить ответственностью объект посредник.
Например возвратимся опять же MVC. UI логике на самом деле нужен не контроллер, а модель, доменная логика. Но мы не хотим? чтобы UI логика была сильно связанна с моделью, и возможно в UI мы хотим получать данные и работать с разной предметной логикой. А связывать UI слой с бизнес логикой было бы глупо, потому что получим код который будет сложный для изменений и поддержки. Выход – вводим контроллер как посредника между View и Model.
Так что распределяйте ответственности своим объектам ответственно (с умом).
Protected Variations или сокрытие реализации или защищенные изменения. Как спроектировать объекты, чтобы изменения в объекте или объекта не затрагивали других? Как избежать ситуации когда меняя код объекта придется вносить изменения в множество других объектов системы?
Кажется мы такое обсуждали уже. И пришли к выводу что нужно использовать low coupling или dependency injection. Именно! Но суть в принципа немного в другом. Суть в том чтобы определить “точки изменений” и зафиксировать их в абстракции (интерфейсе). “Точки изменений” – не что иное как наши объекты, которые могут меняться.
То есть суть в принципа, чтобы определить места в системе, где поведение может изменится и выделить абстракцию, на основе которой и будет происходить дальнейшее программирование с использованием этого объекта.
Все это делается для того чтобы обеспечить устойчивость интерфейса. Если будет много изменений связанных с объектов, он, в таком ключе, считается не устойчивым и тогда нужно выносить его в абстракцию от которой будем зависеть, либо распределять обязанности и ответственность в код иным образом
Polymorphism или полиморфизм. Тоже знакомо, не так ли? Так вот это об том же полиморфизме, который мы знаем из ООП. Если заметить то достаточно много паттернов GoF, да и вообще паттернов, построено на полиморфизме. Что он дает?Он дает возможность трактовать однообразно разные объекты с одинаковым интерфейсом (спецификацией). Давайте вспомним такие паттерны как Strategy, Chain of Resposibility, Command… – их много. И все по своей суть основываются на полиморфизме.
Полиморфизм решает проблему обработки альтернативных вариантов поведения на основе типа. Тут яркий пример это шаблон GoF – Strategy (Стратегия).
Например, для реализации гибкого функционала для шифрования можно определить интерфейс IEncryptionAlgorithm с методом Encrypt, и объект создатель, который вернет IEncryptionAlgorithm, создав внутри себя актуальную реализацию этого интерфейса.

Comments
To leave a comment
Web site or software design
Terms: Web site or software design