Lecture
Это количественные показатели, которые можно измерить и которые могут дать представление о качестве кода
Что можно поменять:
» Lines of code
» Number of classes
» Inheritance depth
» Maintainability index
» Cyclomatic index
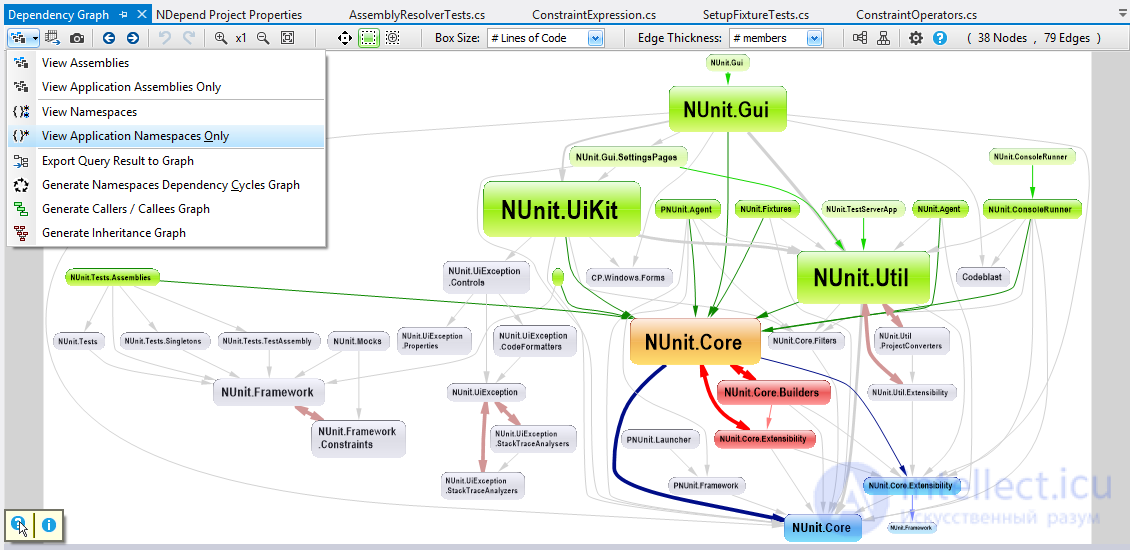
По умолчанию панель графиков зависимостей NDepend отображает график зависимостей между сборками .NET: NDepend предлагает изучить график зависимостей между пространствами имен проекта Visual Studio. В окне «Редактор решений» (или «Редактор кода») щелкните правой кнопкой мыши меню, NDepend предлагает изучить график зависимостей между типами пространства имен. Обратите внимание, что NDepend поставляется с эвристикой, чтобы попытаться вывести пространство имен из папки в обозревателе решений. В окне «Редактор решений» (или «Редактор кода») щелкните правой кнопкой мыши меню, NDepend предлагает изучить график зависимостей между членами (методы + поля) типа. Обратите внимание, что NDepend поставляется с эвристикой, чтобы попытаться вывести тип из исходного файла в обозревателе решений.
DSM (Matrix Dependency Structure Matrix) - это компактный способ представления и навигации по зависимостям между компонентами. Для большинства инженеров разговор о зависимостях означает разговор о чем-то, что выглядит так:
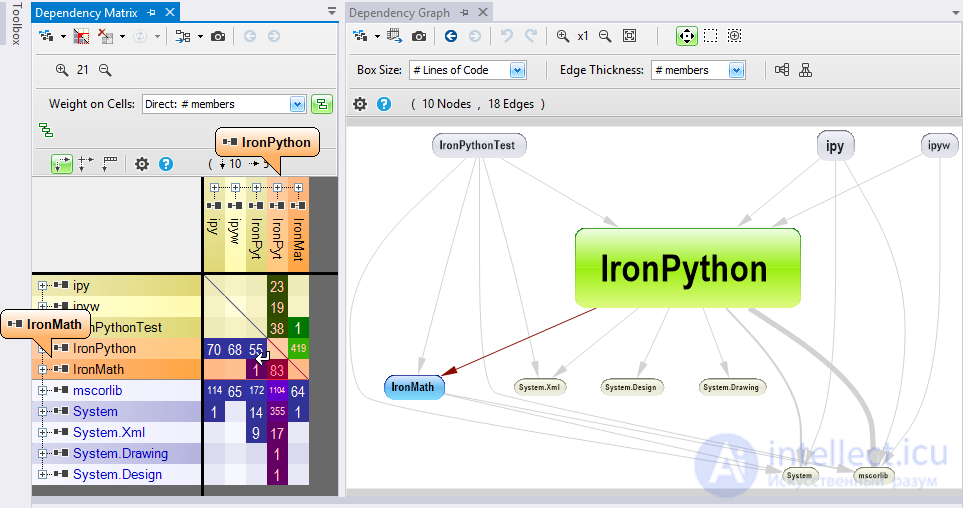
DSM используется для представления той же информации, что и граф.
Как следствие, в приведенном ниже снимке связь с IronPython с IronMath представлена непустой ячейкой в матрице и стрелкой на графике.
Зачем использовать два разных способа, график и DSM, чтобы представлять одну и ту же информацию? Потому что есть компромисс:
Как только один понимает принципы DSM, как правило, один предпочитает DSM над графом для представления зависимостей. Это связано главным образом с тем, что DSM предлагает возможность мгновенно выявлять структурные шаблоны . Это объясняется во второй половине текущего документа.
NDepend предлагает контекстно- зависимую справку для обучения пользователя тому, что он видит в DSM. DSM DDepend опирается на простую 3-красочную схему для ячейки DSM: синий, зеленый и черный. При наведении строки или столбца с помощью мыши в контекстно-зависимой справке объясняется значение этой схемы раскраски:

Непустая ячейка DSM содержит число. Это число представляет сильные стороны связи, представленной клеткой. Сила связи может быть выражена в терминах количества членов / методов / полей / типов или пространств имен, участвующих в связи, в зависимости от фактического значения параметра « Вес на ячейках» . В дополнение к Контекстно-чувствительной справке, DSM предлагает также Информационную панель, которая объясняет связь с простым английским описанием:
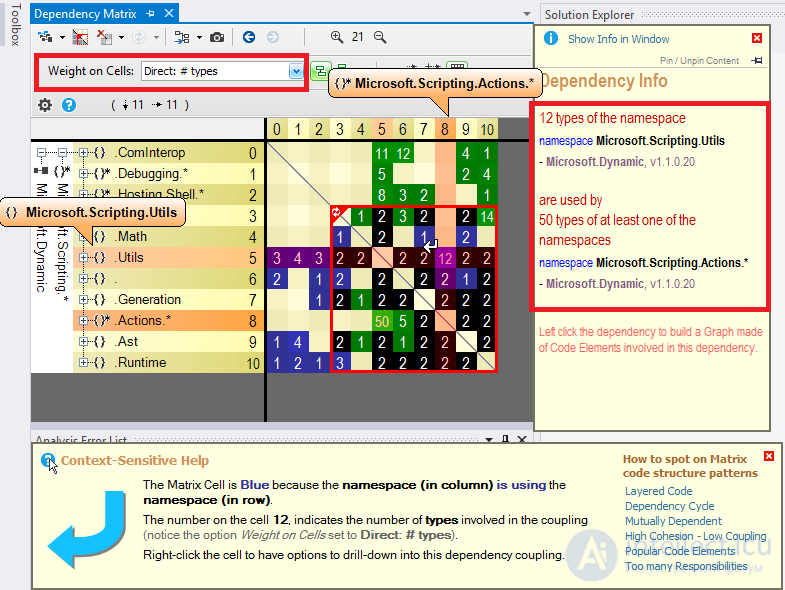
NDepend DSM поставляется с многочисленными опциями, чтобы попробовать:
Рекомендуется использовать все эти функции самостоятельно, анализируя зависимости в вашей базе кода.
NDepend Metric View предлагает множество возможностей для визуализации метрик кода приложения. Таким образом, недостатки кода и шаблоны кода становятся более очевидными. Такие перспективы направлены на то, чтобы улучшить ваше понимание базы кода, чтобы вы могли принять лучшее решение увеличить качество кода и удобство обслуживания кода.
Метричность и трекинг
в метрике В метрическом представлении база кода представлена через Treemap . Treemapping - это алгоритм визуализации для отображения древовидных данных с использованием иерархии вложенных прямоугольников.Древовидная структура, используемая в NDepend treemap, является обычной иерархией кода:
Треугольные прямоугольники представляют собой элементы кода. Параметр уровень определяет тип элемента кода ,представленный единичных прямоугольники. Параметр уровня может принимать значения 5: сборки, пространство имен, тип, метод и поле. Две картинки ниже показывают один и тот же базовый код , отображаемый Method уровня (слева) и пространство имен уровень (справа).
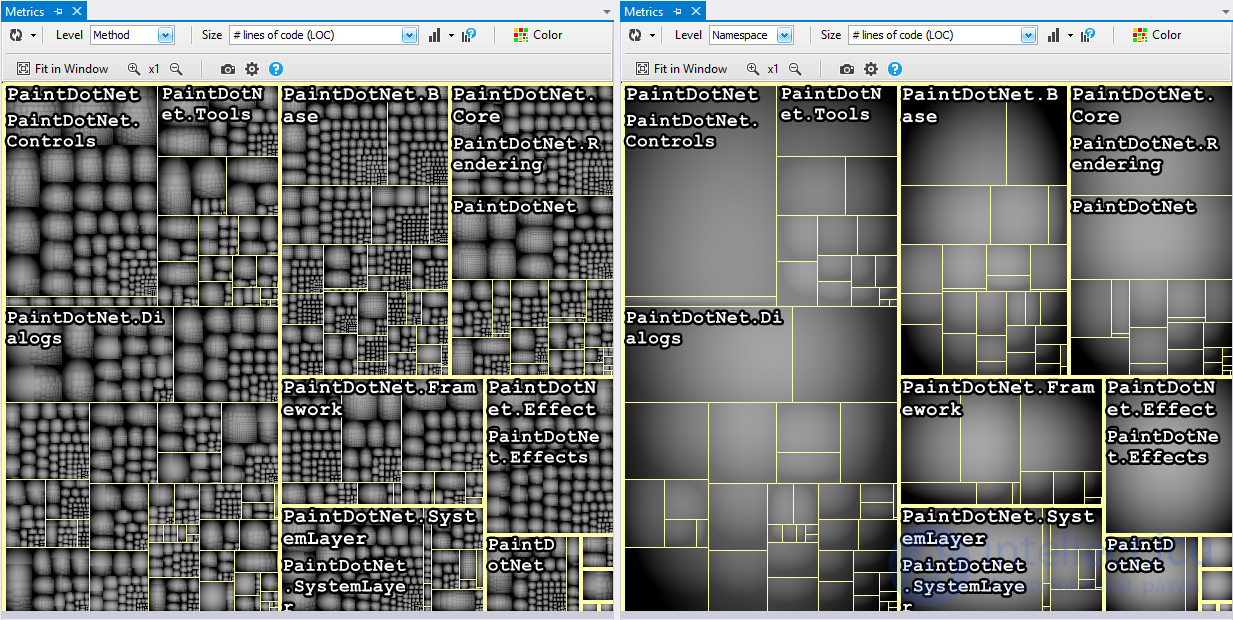
Обратите внимание, что элементы кода, принадлежащие к тем же элементам родительского кода (например, методы в классе или классы в пространствах имен), расположены рядом с treemap.
Параметр Размер treemap определяет размер прямоугольников. Например, если уровень установлен на тип, а метрика - на число строк кода , каждый прямоугольник единицы представляет собой тип, а размер прямоугольника единицы пропорционален количеству строк кода соответствующего типа.
Для каждого уровня элемента кода предлагается несколько кодовых показателей. Также, как объясняется далее в этом документе, можно определить собственные метрики кода и визуализировать их посредством treemaping.

Опция позволяет сгенерировать кодовый запрос CQLinq для Выберите элементы верхнего кода N в соответствии с выбранными метриками кода.

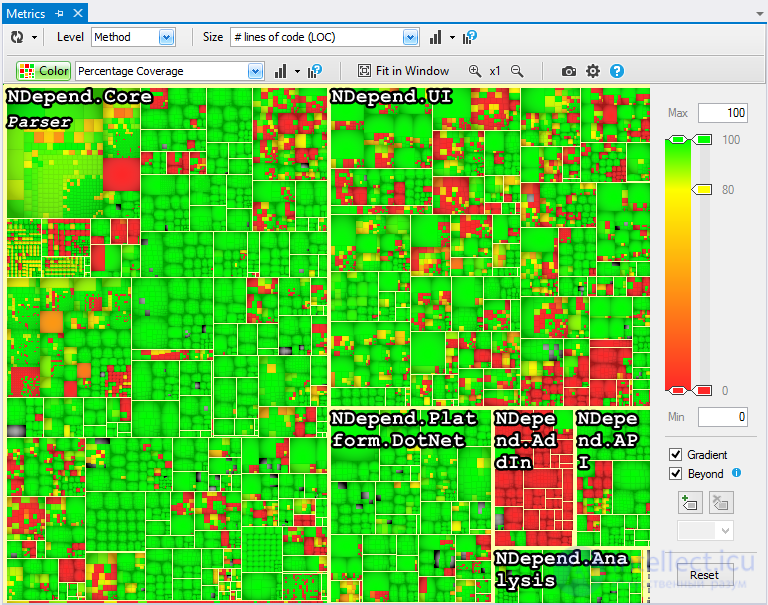
В приведенном выше разделе объясняется, как визуализировать кодовую метрику благодаря трекингованию. Вторая метрика кода может быть представлена красными элементами элементов прямоугольника. Следовательно, метрический вид NDepend удобен для корреляции двух кодовых метрик. Например, снимок экрана ниже показывает покрытие кода на основе тестов на базе кода NDepend. С помощью NDepend или некоторых других инструментов можно получить коэффициент покрытия кода для каждого метода / типа / пространства имен / сборки. Но, объединив # строк кода с коэффициентом покрытия цвета, цветной treemaping, мы получаем уникальное проницательное представление о том, что покрывается или нет с помощью тестов. Например, несмотря на то, что база кода NDepend более 80% покрыта тестами, что является хорошим показателем, цветной treemap показывает красные области, такие как NDepend.Addin.dll

SQL подобный синтакс
Запросы к базе кода (code base), чтобы получить метрики
SELECT TOP 10 METHODS ORDER BY NbLinesOfCode DESC
SELECT METHODS WHERE NbLinesOfCode > 10
SELECT FIELDS WHERE HasAttribute "System.ThreadStaticAttribute"


Efferent coupling (Ce): внутренняя связанность, число типов внутри сборки, которые зависят от типов из вне сборки
Afferent coupling (Ca): внешняя связанность, число типов вне сборки которые зависят от типов в внутри сборки
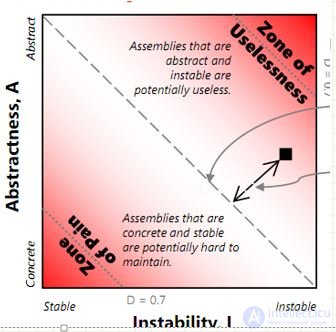
Instability (I): отношение внутренней связанности(Ce) к общей связанности, индикатор устойчивости к изменениям. I = Ce / (Ce + Ca) I=0 – полностью стабильная сборка, сложная для модификации. I=1 – нестабильная сборка, внутри слабая связанность
Abstractness (A): абстрактность, отношение числа внутренних абстрактных типов к числу внутренних типов
. A=0 – полностью «конкретная» сборка
A=1 – полностью абстрактная сборка
Relational Cohesion (H): относительная сцепленность, среднее число внутренних отношений на тип: H = (R + 1) / N, где R = число отношений внутри сборки,
N = число типов сборки
Классы внутри сборки должны сильно соотносится друг с другом, и сцепленность должна быть высокой.
С другой стороны, слишком большие значение могут означать излишнюю связанность. Хорошие значения сцепленности 1.5 <=H<= 4.0
Се = внутренняя связанность, Са – внешняя, I – стабильность, N – число типов сборки, А – абстрактность, Н – относительная сцепленность

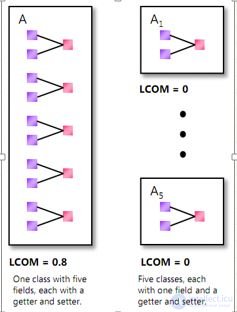
Принцип SRP утверждает, что класс должен иметь не более чем одну причину для изменения. Такой класс сцепленный (cohesive). Высокое значение означает плохо сцеплений класс. Типы, у которых LCOM > 0.8 могут быть проблемными. Тем не менее, очень сложно избежать таких не- сцепленных типов
Число следующих выражений в методе: if, while, for, foreach, case, default, continue, goto, &&, ||, catch, ? : (ternary operator), ?? (nonnull operator)
Эти выражения не учитываются: else, do, switch, try, using, throw, finally, return, object creation, method call, field access
CC > 15 сложно понимать, CC > 30 очень сложные и должны быть разбиты на более мелкие методы (кроме сгенерированного кода)
Main sequence в терминах NDepend, A + I = 1, Представляет оптимальный баланс между абстрактностью и стабильностью D – это нормализированное расстояние от main sequence, 0 <=D <=1 Сборки с D > проблематичны Но, в реальной жизни, сложно избежать таких сборок. Просто необходимо удерживать число таких сборок минимальным.
И это не только то, чему мы учим, это еще и то, что принято у нас в компании при работе над проектами заказчиков — мы стараемся делать их так, чтобы внутреннее качество продукта (как написан код) не уступало внешнему (как отрабатывает функционал).
Многие зачастую уделяют внимание только второму — главное функционал, чтобы заказчик принял и заплатил. А после нас — хоть трава не расти — какая разница, кто и как будет поддерживать, или пытаться изменить этот код — пусть мучаются, мы же в свое время мучились с чужими макаронами.
Внутреннее качество важно не только из-за того, что мы гуманисты и думаем о том, кто этот код будет поддерживать. Еще мы честолюбивы и эгоистичны.
Итак, внутреннее качество нам обеспечивает:
How does this inner quality control? There are several approaches. We apply everything.
And the review we spend is not those leads, and all team members. Here we kill two birds with one stone: the quality of the code is checked, and knowledge of the code is distributed among the team members.
What do we check the code during code review? Compliance with standards, lack of antipatterns (both in the code and in the construction of the database schema), following the OOP / OOD practices, quality of documentation.
We lay down time for carrying out code review, we have a special status for tasks (Open-> In Progress-> Ready for Code Review-> In Review-> Ready for Testing ...). So no doing will come of it.
We use Sonar for both Java and .NET projects. What are we inspecting the code with Sonar?
Code coverage by unit tests (Code coverage). Yes, yes, we write unit tests:
Comments :
Lack of connectivity within methods (LCOM4) - the more this metric is, the higher the risk of a system crash when the functionality changes. Especially because of those places that give an increase in this metric (Sonar gives an average).
Package tangle index - the number of cyclic dependencies between packages and the total number of dependencies should tend to 0.
The percentage of duplication of code (Duplications) - the lack of copy-paste code - should tend to 0%
The cyclomatic complexity (Complexity) of a code determines the complexity of the code structure: the less nested branching operators and cycles, the better:
We are also attentive to the comments (violations) issued by Sonar - we fix the blockers, the critics and the majors.
Sonar is a customizable tool, and there are many more metrics that can be collected and analyzed. Sometimes we resort to them, but often we stop at the standard listed above.
What affects the ability to track internal quality?
Summing up. Writing code is qualitatively absolutely not difficult. After a couple of iterations, those things that the developers had previously monitored become natural (an internal culture is produced). You just need to properly configure the process. I do not hide that at first it will take away too much time. But soon everything will pay off with a torus.

Comments
To leave a comment
Web site or software design
Terms: Web site or software design