For a start, about the title of a series of posts: posts will be about caching on the Web (in high-load Web projects), and about using memcached for caching, and about other uses of memcached in Web projects. That is, all three components of the name in various combinations will be covered in this series of posts.
Caching today is an integral part of any Web project, not necessarily heavily loaded. For each resource, the response time of the server is critical for the user. An increase in server response time leads to an outflow of visitors. Consequently, it is necessary to minimize the response time: for this it is necessary to reduce the time required to form a response to the user, and the response to the user requires receiving data from some external resources (backend). These resources can be either databases or any other relatively slow data sources (for example, a remote file server on which we specify the amount of free space). To generate a single page of a fairly complex resource, we may need to make dozens of such hits. Many of them will be fast: 20 ms and less, but there is always some small number of queries, the calculation time of which can be in seconds or minutes (even in the most optimized system there can be one, although their number should be minimal). If we add up all the time we spend waiting for the results of the queries (if we execute the queries in parallel, then we take the computation time for the longest query), we get an unsatisfactory response time.
The solution to this problem is caching: we put the result of the calculations in some storage (for example, memcached), which has excellent characteristics in terms of access time to information. Now, instead of accessing slow, complex and heavy backends, we only need to execute the query to the fast cache.
Memcached and caching
Principle of locality
We find the cache or caching approach everywhere in electronic devices, software architecture: CPU cache (first and second level), hard disk buffers, operating system cache, buffer in the car radio. What determines such caching success? The answer lies in the principle of locality: for a program, for a device, it is common for a certain period of time to work with a certain subset of data from the common set. In the case of RAM, this means that if the program works with data located at address 100, then with a greater degree of probability the next appeal will be at 101, 102, etc., rather than at address 10,000, for example. The same with the hard disk: its buffer is filled with data from areas adjacent to the last read sectors, if our programs worked at one time not with some relatively small set of files, but with all the contents of the hard disk, the buffers would be meaningless . The buffer of the car radio makes a preemptive reading from the disc of the next minutes of music, because we, most likely, will listen to the music file sequentially, rather than jumping over a set of music, etc.
In the case of web projects, the success of caching is determined by the fact that there are always the most popular pages on the site, some data is used on all or almost all pages, that is, there are some samples that are required much more often than others. We replace several calls to backend with one call for building a cache, and then all subsequent calls will be made through a fast working cache.
The cache is always better than the original data source: the CPU cache is orders of magnitude faster than the RAM, but we cannot make the RAM as fast as the cache — this is economically inefficient and technically difficult. The hard disk buffer satisfies requests for data by orders of magnitude faster than the hard disk itself, but the buffer does not have the property of storing data when the power is turned off - in this sense it is worse than the device itself. The situation is similar with caching on the Web: the cache is faster and more efficient than the backend, but it usually cannot save data when the server is restarted or crashed, and it doesn’t have any logic to calculate any results: it can return only what we previously put into it.
Memcached
Memcached is a huge in-memory hash table accessible via a network protocol. It provides a service for storing values associated with keys. Access to the hash we get through a simple network protocol, the client can be a program written in an arbitrary programming language (there are clients for C / C ++, PHP, Perl, Java, etc.)
The simplest operations are to get the value of the specified key (get), set the key value (set) and delete the key (del). To implement a chain of atomic operations (subject to concurrent access to memcached from parallel processes), additional operations are used: increment / decrement of the key value (incr / decr), append data to the key value at the beginning or end (append / prepend), atomic ligament get / set values (gets / cas) and others.
Memcached was implemented by Brad Fitzpatrick as part of the LiveJournal project. It was used to unload the database from requests for page content. Today memcached has found its use in the core of many large projects, for example, Wikipedia, YouTube, Facebook and others.
General caching scheme
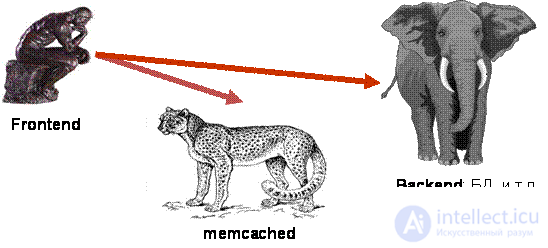
In the general case, the caching scheme is as follows: the frontend (that part of the project that forms the answer to the user) is required to obtain data of some kind of sample. Frontend accesses a cheetah-like memcached server for a sample cache (get request). If the corresponding key is found, the work ends there. Otherwise, it is necessary to appeal to a heavy, unwieldy, but powerful (like an elephant) backend, the role of which is most often a database. The result is immediately recorded in memcached as a cache (set-request). In this case, usually the key is given the maximum lifetime (expiration date), which corresponds to the time the cache is flushed.
This standard caching scheme is always implemented. Some projects may use local files instead of memcached, other storage methods (another database, PHP accelerator cache, etc.) However, as will be shown later, in a highly loaded project, this scheme may not work in the most efficient way. Nevertheless, in our further story we will rely on this very scheme.
Memcached architecture
How does memcached work? How he manages to work so quickly that even dozens of requests to memcached, which are necessary for processing one page of the site, do not lead to a significant delay. At the same time, memcached is extremely undemanding to computing resources: on a loaded installation, the processor time used by them rarely exceeds 10%.
First, memcached is designed so that all its operations have the algorithmic complexity O (1), i.e. the execution time of any operation does not depend on the number of keys that memcached stores. This means that some operations (or capabilities) will be absent in it, if their implementation requires only linear (O (n)) time. So, memcached lacks the ability to combine keys “into folders”, i.e. any grouping of keys, also we will not find group operations on keys or their values.
The main optimized operations are allocating / freeing blocks of memory for storing keys, defining the policy of the most unused keys (LRU) for clearing the cache when there is a shortage of memory. The search for keys occurs through hashing, so it has O (1) complexity.
Asynchronous I / O is used, threads are not used, which provides additional performance gains and lower resource requirements. In fact, memcached can use threads, but this is only necessary to use all the cores or processors available on the server if the load is too high - there is no thread for each connection in any case.
In fact, it can be said that the response time of the memcached server is determined only by the network costs and is almost equal to the packet transmission time from the frontend to the memcached server (RTT). Such characteristics allow using memcached in high-load web-projects for solving various tasks, including for data caching.
Key loss
Memcached is not a reliable repository - it is possible that the key will be removed from the cache before its expiration date. The project architecture must be prepared for this situation and must respond flexibly to the loss of keys. There are three main reasons for losing keys:
- The key was deleted before its expiration date due to lack of memory for storing values of other keys. Memcached uses the LRU policy, so this loss means that the key is rarely used and the cache memory is freed to store more popular keys.
- The key has been removed since its lifetime has expired. This situation is strictly speaking not a loss, since we ourselves have limited the key lifetime, but for the client code with respect to memcached such a loss is indistinguishable from other cases - when accessing memcached, we get the answer “there is no such key”.
- The most unpleasant situation is the collapse of the memcached process or the server on which it is located. In this situation, we lose all the keys that were stored in the cache. Cluster organization allows a few to smooth out the consequences: a lot of memcached servers, according to which project keys are “smeared”: the consequences of the collapse of one cache will be less noticeable.
All the situations described should be kept in mind when developing software that works with memcached. You can divide the data that we store in memcached, according to the degree of criticality of their loss.
"You can lose." This category includes database sample caches. The loss of such keys is not so terrible, because we can easily restore their values, turning again to the backend. However, frequent loss of caches lead to unnecessary accesses to the database.
"I would not want to lose." Here you can mention the counters of site visitors, resource views, etc. Although it is sometimes impossible to directly restore these values, the values of these keys have a time-limited meaning: after a few minutes, their value is no longer relevant, and a new value will be calculated.
"They should not lose at all." Memcached is convenient for storing user sessions - all sessions are equally accessible from all servers in the frontend cluster. So, I would never want to lose the contents of the sessions - otherwise the users on the site will be “logged out”. How to try to escape? You can duplicate session keys on multiple memcached servers from a cluster, so the probability of loss is reduced.

Comments
To leave a comment
Highly loaded projects. Theory of parallel computing. Supercomputers. Distributed systems
Terms: Highly loaded projects. Theory of parallel computing. Supercomputers. Distributed systems