Lecture
The film "Social Network" well illustrates the phenomenon of the development of Facebook,
who managed in a record time to gather fabulous, previously unthinkable audience.
However, another component of the project remained behind the scenes - how it works.
from the inside. His technical device.
What is Facebook now? This is best demonstrated by dry numbers:
How does all this work?
You can relate differently to social networks in general and to Facebook in
particular, but in terms of manufacturability this is one of the most interesting
projects. Particularly pleased that the developers never refused to share
experience in creating a resource that can withstand such loads. There is a big
practical use. After all, the system is based on publicly available components,
which you can use, I can use - they are available to everyone.
Moreover, many of the technologies that were developed inside Facebook,
now published with open source. And using them, again, can
anyone who wants. Social network developers, if possible, used only
open technologies and Unix philosophy: every component of the system should be
as simple and productive as possible, while solving problems is achieved by
combining them. All efforts of engineers are aimed at scalability,
minimizing the number of points of failure and, most importantly, simplicity. Not to be
unfounded, I will point out the main technologies that are now used inside
Facebook:
The load balancer selects a php server to process each request, where
HTML is generated from various sources (such as MySQL, memcached) and
specialized services. So the Facebook architecture has
traditional three-level view:
I believe that it will be most interesting to hear how the project succeeded
use the most familiar technology. And there really is a lot
nuances.
What usually happens in 20 minutes on Facebook?
- People publish 1,000,000 links;
- Friends are tagged with 1,323,000 photos;
- 1,484,000 friends are invited to events;
- Send 1,587,000 messages to the wall;
- Write 1,851,000 new statuses;
- 2,000,000 pairs of people become friends;
- 2,700,000 photos uploaded;
- 10 200 000 comments appear;
- 4,632,000 private messages are sent.
This begs the question: why PHP? In many ways, simply "historically
it worked out ". It is well suited for web development, easy to learn and work,
A huge range of libraries is available for programmers. Besides, there is
huge international community. Of the negative sides can be called high
RAM consumption and computing resources. When the amount of code became
too large, weak typing added to this list, linear growth
costs for connecting additional files, limited opportunities for
static analysis and optimization. All this began to create great difficulties. By
For this reason, a lot of improvements to PHP were implemented on Facebook, including
bytecode optimization, improvements in APC (lazy loading, optimization
locks, heated cache, and a number of native extensions (memcache client,
serialization format, logs, statistics, monitoring, asynchronous mechanism
event handling).
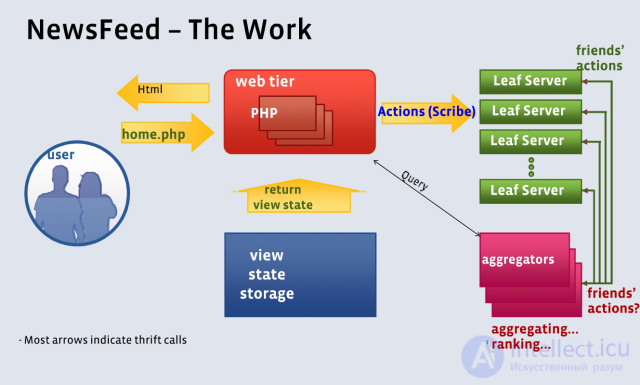
The formation of the news feed
The HipHop project deserves special attention - it is a source code transformer
from PHP to optimized C ++. The principle is simple: developers write in PHP,
which is converted to optimized C ++. In the add-in implemented
static code analysis, data type definition, code generation and much
another. Also HipHop facilitates the development of extensions, significantly reduces
the cost of RAM and computing resources. Team of three
programmers took a year and a half to develop this technology, in particular, was
rewritten most of the interpreter and many extensions of the PHP language. Now
HipHop codes published under the opensource license, use on health.
Facebook development culture
- Move fast and not be afraid to break some things;
- great influence of small teams;
- be frank and innovative;
- return innovation to the opensource community.
Now about the database. Unlike the vast majority of sites, MySQL in
Facebook is used as a simple repository for key-value pairs. Large
the number of logical databases is distributed across physical servers, but
Replication is used only between data centers. Load balancing
carried out by the redistribution of databases on machines. Since the data
distributed almost randomly, no JOIN operations,
merging data from several tables is not used in the code. In this there is
meaning. After all, increasing computing power is much easier on web servers,
than on database servers.
Facebook uses almost unmodified MySQL source code,
but with our own partitioning schemes for globally unique
identifiers and archiving based on the frequency of access to data.
The principle is very effective, since most requests concern the most recent
information. Access to new data is maximally optimized, and old records
automatically archived. In addition, their own libraries are used for
data access based on a graph, where objects (graph vertices) can only have
limited set of data types (integer, string of limited length, text),
and connections (graph edges) are automatically replicated, forming an analogue of distributed
foreign keys.
As you know, memcached is a high-performance distributed hash table.
Facebook stores “hot” data from MySQL in it, which significantly reduces
load at the database level. More than 25 TB are used (just think about
figure) of RAM on several thousand servers with an average time
response less than 250 µs. Cached serialized PHP data structures, with
due to the lack of an automatic mechanism for checking data consistency between
memcached and MySQL have to do it at the level of program code. The main
The way to use memcache is a lot of multi-get requests,
used to get data at the other end of the graph edges.
Facebook is very actively engaged in finalizing the project on
performance. Most of the improvements described below were included in
opensource memcached version: port for 64-bit architecture, serialization,
multithreading, compression, access to memcache via UDP (reduces consumption
memory due to the absence of thousands of TCP connection buffers). In addition, there were
Some changes have been made to the Linux kernel to optimize memcache performance.
How effective is it? After the above modifications, memcached is capable of
perform up to 250,000 operations per second compared to the standard 30,000 - 40
000 in the original version.
Another innovative development of Facebook is the Thrift project. In fact,
This is a multi-language application building mechanism.
programming. The main goal is to provide transparent technology.
interactions between different programming technologies. Thrift offers
developers special interface language, static code generator,
and also supports many languages, including C ++, PHP, Python, Java, Ruby,
Erlang, Perl, Haskell. You can choose the transport (sockets, files, buffers in
memory) and serialization standard (binary, JSON). Various types supported
servers: non-blocking, asynchronous, both single-threaded and multi-threaded.
Alternative technologies are SOAP, CORBA, COM, Pillar, Protocol Buffers,
but everyone has their own significant flaws, and this has forced Facebook to develop
my own. Thrift's important advantage is performance.
He is very, very fast, but even this is not his main plus. With the advent of Thrift
the development of network interfaces and protocols takes much less time. AT
Facebook technology is included in a common toolkit that is familiar to anyone.
to the programmer. In particular, thanks to this, managed to introduce a clear separation
labor: work on high-performance servers is now separate from
work on applications. Thrift, like many other Facebook designs, is now
is in the public domain.
The return of innovation
Returning innovation to the public is an important aspect of developing
Facebook The company has published its projects:
Thrift
Scribe,
Tornado
Cassandra,
Varnish
Heve
xhprof.
In addition, improvements were made for PHP, MySQL, memcached.Information about the interaction of Facebook with the opensource community of these and
other projects located on
opensource page.
Having finished on this talk about the technologies used, I want to bring
details of solving an interesting problem within a social network, namely -
photo storage organization. Many photos. A huge amount
photos. This is quite an interesting story. User photo albums first
were organized according to the most trivial scenario:
Such a simple approach was needed to first verify that the product
claimed by users, and they really will actively download
Photo. New feature, as you know, "flooded." But in practice it turned out that
File systems are not suitable for working with a large number of small files.
Metadata does not fit into RAM, which leads to additional
calls to the disk subsystem. The limiting factor is input-output, and
not storage density. The first step in optimization was caching. Most
frequently used image thumbnails were cached in memory on the original
servers for scalability and performance, and distributed across
CDN (geographically distributed network infrastructure) to reduce network
delays. This gave the result. Later it turned out that you can do even better.
Images are stored in large binary files (blob), providing
application information about which file and with which indentation (in fact,
ID) from the beginning is each photo. Such a service in
Facebook got the name Haystack and turned out to be ten times more efficient
"simple" approach and three times more effective than "optimized". As the saying goes,
all ingenious is simple!
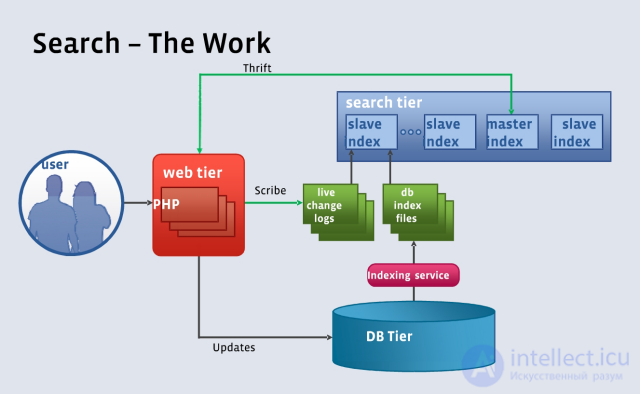
Facebook search principle
It’s no secret that the LAMP stack is efficient and suitable for creating the most complex
systems, but far from perfect. Of course, PHP + MySQL + Memcache solve
most of the tasks, but not all. Every major project is faced with the fact
what:
Facebook (and any other large projects) has to develop
own internal services to compensate for the shortcomings of the main
technologies, move the executable code closer to the data, make the resource-intensive parts
code more efficient, realize benefits that are only available in
certain programming languages. Lightning-fast processing requests from
the monstrous number of users is achieved through an integrated approach to
distributing requests across thousands of servers and continuously working to eliminate
bottlenecks in the system. The company has many small teams with authority.
make important decisions that combined with short development cycles
allows you to quickly move forward and solve all problems promptly.
The result is easy to check. Open facebook.com.
Additional tools
Facebook has been created to manage such a huge system.
various additional services. In total there are more than fifty, I will give
a few examples:
- SMC (service management console) - centralized configuration,
determining which physical machine runs the logical service;- ODS is a tool for visualizing changes in any statistical
data available in the system - convenient for monitoring and alerts;- Gatekeeper - separation of deployment and launch processes, A / B testing
(a method to determine which version of a page is better to persuade
visitors to do this or that action).
Everyone has ever heard of Google due to their comprehensive, “smart” and fast search service, but it's no secret that they are not limited to them. Their platform for building scalable applications allows you to produce many surprisingly competitive Internet applications that work at the level of the entire Internet as a whole. They set a goal to constantly build an increasingly productive and scalable architecture to support their products. How do they do it?
Information sources
Just want to say that this entry is a translation from English, the original version is Todd Hoff. The original was written around mid-2007, but in my opinion it is still very relevant.
The following is a list of sources of information from the original:
- Video: Build large systems in Google
- Google Lab: Google File System (GFS)
- Google Lab: MapReduce: Simplified Data Processing on Large Clusters
- Google Lab: BigTable.
- Video: BigTable: distributed storage system.
- How Google's David Carr Works in Baseline Magazine.
- Google Lab: data interpretation. Parallel analysis with Sawzall.
- Records from the conference on scaling from Dare Obasonjo.
Platform
- Linux
- A wide variety of programming languages: Python, Java, C ++
What's inside?
Statistics
- For 2006, the system included 450000 low-cost servers
- In 2005, 8 billion pages were indexed. At the moment ... who knows?
- At the time of writing of the original, Google includes more than 200 GFS clusters. One cluster can consist of 1000 or even 5000 computers
- Tens and hundreds of thousands of computers receive data from GFS clusters, which account for more than 5 petabytes of disk space. The total bandwidth of write and read operations between data centers can reach 40 gigabytes per second.
- BigTable allows you to store billions of links (URLs), hundreds of terabytes of satellite images, as well as the settings of millions of users.
// Figures are not the first freshness of course, but not bad either.
Stack
Google visualizes its infrastructure in the form of a three-layer stack:
- Products: search, advertising, email, maps, video, chat, blogs
- Distributed system infrastructure: GFS, MapReduce and BigTable
- Computing Platforms: Multiple Computers in Multiple Data Centers
- Easy deployment for a company at low cost
- More money is invested in equipment to eliminate the possibility of data loss.
Secure data storage with GFS
- Reliable scalable data storage is essential for any application. GFS is the foundation of their information storage platform.
- GFS is a large distributed file system capable of storing and processing huge amounts of information.
- Why build something yourself instead of just taking it off the shelf? They control absolutely the entire system and it is this platform that distinguishes them from all the others. She provides:
- high reliability of data centers
- scalability up to thousands of network nodes
- high throughput read and write operations
- support for large data blocks, the size of which can be measured in gigabytes
- effective distribution of operations between data centers to avoid the occurrence of bottlenecks in the system
- There are master servers and servers in the system that actually store the information:
- Master servers store metadata for all files. The data itself is stored in blocks of 64 megabytes on the other servers. Clients can perform operations with metadata on the master servers to find out on which server the necessary data is located.
- To ensure reliability, the same data block is stored in triplicate on different servers, which provides redundancy in case of failure of any server.
- New applications can use both existing clusters and new ones created specifically for them.
– Ключ успеха заключается в том, чтобы быть уверенными в том, что у людей есть достаточно вариантов выбора для реализации их приложений. GFS может быть настроена для удовлетворения нужд любого конкретного приложения.
Работаем с данными при помощи MapReduce
- Теперь, когда у нас есть отличная система хранения, что же делать с такими объемами данных? Допустим, у нас есть много терабайт данных, равномерно распределенных между 1000 компьютерами. Коммерческие базы данных не могут эффективно масштабироваться до такого уровня, именно в такой ситуации в дело вступает технология MapReduce .
- MapReduce является программной моделью и соответствующей реализацией обработки и генерации больших наборов данных. Пользователи могут задавать функцию, обрабатывающую пары ключ/значение для генерации промежуточных аналогичных пар, и сокращающую функцию, которая объединяет все промежуточные значения, соответствующие одному и тому же ключу. Многие реальные задачи могут быть выражены с помощью этой модели. Программы, написанные в таком функциональном стиле автоматически распараллеливаются и адаптируются для выполнения на обширных кластерах. Система берет на себя детали разбиения входных данных на части, составления расписания выполнения программ на различных компьютерах, управления ошибками, и организации необходимой коммуникации между компьютерами. Это позволяет программистам, не обладающим опытом работы с параллельными и распределенными системами, легко использовать все ресурсы больших распределенных систем.
- Зачем использовать MapReduce ?
– Отличный способ распределения задач между множеством компьютеров
– Обработка сбоев в работе
– Работа с различными типами смежных приложений, таких как поиск или реклама. Возможно предварительное вычисление и обработка данных, подсчет количества слов, сортировка терабайт данных и так далее
– Вычисления автоматически приближаются к источнику ввода-вывода
- MapReduce использует три типа серверов:
– Master: назначают задания остальным типам серверов, а также следят за процессом их выполнения
– Map: принимают входные данные от пользователей и обрабатывают их, результаты записываются в промежуточные файлы
– Reduce: принимают промежуточные файлы от Map-серверов и сокращают их указанным выше способом
- Например, мы хотим посчитать количество слов на всех страницах. Для этого нам необходимо передать все страницы, хранимые в GFS , на обработку в MapReduce . Этот процесс будет происходить на тысячах машин одновременно с полной координацией действий, в соответствии с автоматически составленным расписанием выполняемых работ, обработкой потенциальных ошибок, и передачей данных выполняемыми автоматически.
– Последовательность выполняемых действий выглядела бы следующим образом: GFS → Map → перемешивание → Reduce → запись результатов обратно в GFS
– Технология MapReduce состоит из двух компонентов: соответственно map и reduce . Map отображает один набор данных в другой, создавая тем самым пары ключ/значение, которпыми в нашем случае являются слова и их количества.
– В процессе перемешивания происходит аггрегирование типов ключей.
– Reduction в нашем случае просто суммирует все результаты и возвращает финальный результат.
- В процессе индексирования Google подвергает поток данных обработке около 20 разных механизмов сокращения. Сначала идет работа над всеми записями и аггрегированными ключами, после чего результат передается следующему механизму и второй механизм уже работает с результатами работы первого, и так далее.
- Программы могут быть очень маленькими, всего лишь от 20 до 50 строк кода.
- Единственной проблемой могут быть «отстающие компьютеры». Если один компьютер работает существенно медленнее, чем все остальные, это будет задерживать работу всей системы в целом.
- Транспортировка данных между серверами происходит в сжатом виде. Идея заключается в том, что ограничивающим фактором является пропускная способность канала и ввода-вывода, что делает резонным потратить часть процессорного времени на компрессию и декомпрессию данных.
Хранение структурированных данных в BigTable
- BigTable является крупномасштабной, устойчивой к потенциальным ошибкам, самоуправляемой системой, которая может включать в себя терабайты памяти и петабайты данных, а также управлять миллионами операций чтения и записи в секунду.
- BigTable представляет собой распределенный механизм хэширования, построенный поверх GFS , а вовсе не реляционную базу данных и, как следствие, не поддерживаетSQL-запросы и операции типа Join.
- Она предоставляет механизм просмотра данных для получения доступа к структурированным данным по имеющемуся ключу. GFS хранит данные не поддающиеся пониманию, хотя многим приложениям необходимы структурированные данные.
- Коммерческие базы данных попросту не могут масштабироваться до такого уровня и, соответственно, не могут работать с тысячами машин одновременно.
- С помощью контролирования своих низкоуровневых систем хранения данных, Googleполучает больше возможностей по управлению и модификации их системой. Например, если им понадобится функция, упрощающая координацию работы между датацентрами, они просто могут написать ее и внедрить в систему.
- Подключение и отключение компьютеров к функционирующей системе никак не мешает ей просто работать.
- Каждый блок данных хранится в ячейке, доступ к которой может быть предоставлен как по ключу строки или столбца, так и по временной метке.
- Каждая строка может храниться в одной или нескольких таблицах. Таблицы реализуются в виде последовательности блоков по 64 килобайта, организованных в формате данных под названием SSTable .
- В BigTable тоже используется три типа серверов:
– Master: распределяют таблицы по Tablet-серверам, а также следят за расположением таблиц и перераспределяют задания в случае необходимости.
– Tablet: обрабатывают запросы чтения/записи для таблиц. Они раделяют таблицы, когда те превышают лимит размера (обычно 100-200 мегабайт). Когда такой сервер прекращает функционирование по каким-либо причинам, 100 других серверов берут на себя по одной таблице и система продолжает работать как-будто ничего не произошло.
– Lock: формируют распределенный сервис ограничения одновременного доступа. Операции открытия таблицы для записи, анализа Master-сервером или проверки доступа должны быть взаимноисключающими.
- Локальная группировка может быть использована для физического хранения связанных данных вместе, чтобы обеспечить лучшую локализацию ссылок на данные.
- Таблицы по возможности кэшируются в оперативной памяти серверов.
Equipment
- Как эффективно организовать большую группу компьютеров с точки зрения издержек и производительности?
- Используется самое обыкновенное ультра-дешевое оборудование и поверх него строится программное обеспечение, способное спокойно пережить смерть любой части оборудования.
- A thousand-fold increase in computing power can be achieved with costs 33 times less if we take advantage of a tolerant infrastructure for failure, compared to an infrastructure built on highly reliable components. Reliability is built on top of unreliable components.
- Linux, home hosting servers, motherboards designed for personal computers, cheap data storage facilities.
- The price per watt of energy in terms of performance is not getting lower, which leads to big problems related to power supply and cooling.
- Using co-location in their own and leased data centers.
miscellanea
- A quick release of changes is preferred over waiting.
- Libraries - the prevailing method of building programs.
- Some applications are provided as services.
- The infrastructure manages the definition of application versions in such a way that they can release new products without fear of disrupting the operation of any component of the system.
Ways of development
- Support for geographically distributed clusters.
- Create a single global namespace for all data. Currently, the data is distributed across clusters.
- More automated data transfer and processing
- Resolving issues related to maintaining serviceability of services, even in cases where a whole cluster is disconnected from the system due to technical work or some kind of malfunction.
Summing up
- Infrastructure can be a competitive advantage. This is definitely for Google. They can release new Internet services faster, at lower cost, at such a level that few can compete with them. The approach of many companies is very different from the approach of Google, these companies view infrastructure as an item of expenditure, they usually use very different technologies and do not think at all about planning and organizing their system. Google is positioning itself as a system building company, which is a very modern approach to software development.
- Covering multiple data centers is still an unsolved problem. Most sites are based in one or two data centers. The complete distribution of the site between multiple data centers is a tricky task.
- Take a look at Hadoop if you don’t have time to build your own architecture from scratch. Hadoop is a opensource implementation of many of the ideas presented here.
- An often underestimated advantage of the platform approach is the fact that even inexperienced developers can quickly and efficiently implement labor-intensive platform-based applications. But if each project required an equally distributed architecture, this would create many problems, as people who understand how this is done are quite rare.
- Working together is not always such a bad thing. If all parts of the system work interconnectedly, the improvement in one of them will immediately and absolutely transparently reflect in a positive way on the other components of the system. Otherwise, this effect will not be observed.
- Building self-managed systems allows you to more easily redistribute resources between servers, expand the system, turn off some computers, and elegantly perform updates.
- It is worth making parallel operations in parallel.
- Everything that Google did was preceded by art, and not just large-scale deployment of the system.
- Consider the possibility of data compression , it is a very good solution if there is too much CPU time left, but there is a lack of bandwidth.
The architecture of Google was one of the first articles on Insight IT . It was she who gave impetus to the development of the project: after its publication, blog traffic increased tenfold and the first hundreds of subscribers appeared. Years passed, the information becomes outdated rapidly, so it's time to look at Google again, now from the standpoint of the end of 2011. What we will see new in the architecture of the Internet giant?
Statistics
- General
- Google has a daily audience of around 1 billion people.
- According to Alexa, more than half of the Internet audience use Google every day.
- According to IWS, the Internet audience is 2.1 billion
- More than 900 thousand servers are used.
- Up to 10 million servers are planned for the foreseeable future.
- 12 main data centers in the US, the presence in a large number of points around the world (more than 38)
- About 32 thousand employees in 76 offices around the world
- Search
- Over the past 14 years, the average processing time per search query has decreased from 3 seconds to less than 100 milliseconds, i.e., 30 times
- More than 40 billion pages in the index, if we equate each to A4 sheet they would cover the territory of the United States in 5 layers
- More than 1 quintillion unique URLs (10 to 18 degrees); if you print them in one line, its length will be 51 million kilometers, one third of the distance from Earth to the Sun
- Approximately 100 quintillion words are found on the Internet; one person would need about 5 million years to type them on the keyboard.
- More than 1.5 billion images have been indexed to save them, it would take 112 million diskettes that can be stacked in a stack with a height of 391 kilometers.
- Gmail
- More than 170 million active users
- The second most popular mail service in the United States, the third in the world (according to comScore)
- With the current growth rate of GMail's audience and competitors, it will become the market leader in 2-3 years
- Google+
- Over 40 million users as of October 2011, when launched in June 2011
- 25 million users in the first month
- 70:30 approximate ratio of men and women
- Development cost more than half a billion dollars
- YouTube
- Loads over 13 million hours of video per year
- 48 hours of video is downloaded every minute, which corresponds to almost 8 years of content or 52 thousand full-length films
- More than 700 billion video views per year
- The monthly audience is 800 million unique visitors.
- Several thousand feature films in YouTube Movies
- Over 10% of all HD videos
- 13% of views (400 million per day) occur from mobile devices
- It still works at a loss, only 14% of video views generate revenue from advertising
- Finance
- Revenue of about 36 billion dollars a year
- Profit after taxes of about 10 billion dollars a year
- Capitalization of the order of 200 billion dollars
Architecture
Google is a huge Internet company, the undisputed leader in the Internet search market and the owner of a large number of products, many of which have also achieved some success in their niche.
Unlike most Internet companies that deal with only one product (project), Google’s architecture cannot be presented as a single specific technical solution. Today, we are more likely to consider the overall strategy for the technical implementation of Internet projects at Google, perhaps slightly affecting other aspects of doing business on the Internet.
All Google products are based on a constantly evolving software platform that is designed to work on millions of servers located in different data centers around the world.
Equipment
Ensuring the work of a million servers and the expansion of their fleet is one of the key expenses of Google. To minimize these costs, much attention is paid to the efficiency of the server, network and infrastructure equipment used.
In traditional data centers, the electricity consumption of servers is approximately equal to its consumption by the rest of the infrastructure, while Google managed to reduce the percentage of use of additional electricity to 14%. Thus, the total power consumption by Google's datacenter is comparable to the consumption of only servers in a typical datacenter and half the total energy consumption. The main concepts that are used to achieve this result:
- Accurate measurement of electricity consumption by all components allows you to determine the possibilities for its reduction;
- In the data centers, Google is warm, which saves on cooling;
- When designing a datacenter, attention is paid to even minor details, saving even a little - on such a scale it pays off;
- Google can cool datacenters with virtually no air conditioning, using water and its evaporation (see how it is implemented in Finland) .
Google is actively promoting the maximum use of renewable energy. For this, long-term agreements are made with its suppliers (for 20 years or more), which allows the industry to actively develop and increase capacity. Renewable energy generation projects sponsored by Google have a total capacity of more than 1.7 gigawatts, which is significantly more than is used for Google. This power would be enough to provide electricity to 350 thousand homes.
If we talk about the life cycle of the equipment, the following principles are used:
- Reduced transportation: wherever possible, heavy components (such as server racks) are purchased from local suppliers, even if similar products could be purchased cheaper in other places.
- Reuse: before buying new equipment and materials, the possibilities of using existing ones are considered. This principle helped to avoid buying more than 90 thousand new servers.
- Disposal : when reuse is not possible, equipment is completely cleared of data and sold in the secondary market. What cannot be sold is dismantled for materials (copper, steel, aluminum, plastic, etc.) for subsequent proper disposal by specialized companies.
Google is known for its experiments and unusual solutions in the field of server hardware and infrastructure. Some are patented; some took root, some did not. I will not dwell on them in detail, only briefly about some:
- Backup power integrated into the server power supply, provided with standard 12V batteries;
- “Server sandwich”, where motherboards from two sides surround the water system of the heat sink in the center of the rack;
- Datacenter of containers.
In conclusion of this section, I would like to face the truth: there is no perfect equipment . Any modern device, be it a server, switch or router, has a chance to become unusable due to manufacturing defects, accidental coincidence of circumstances or other external factors. If you multiply this seemingly small chance by the amount of equipment used by Google, then it turns out that almost every minute one or more devices in the system fail. It is impossible to rely on equipment, therefore the issue of fault tolerance is transferred onto the shoulders of the software platform, which we will now consider.
Platform
In Google, very early on we encountered problems with the unreliability of equipment and work with huge amounts of data. The software platform, designed to work on many low-cost servers, allowed them to abstract from the failures and limitations of a single server.
The main tasks in the early years were to minimize the points of failure and process large volumes of semi-structured data. The solution to these problems are the three main layers of the Google platform, working one on top of another:
- Google File System: a distributed file system consisting of a server with metadata and a theoretically unlimited number of servers storing arbitrary data in blocks of a fixed size.
- BigTable: a distributed database that uses two arbitrary byte keystrings (denoting row and column) and date / time (ensuring versioning) for data access.
- MapReduce: a mechanism for distributed processing of large amounts of data, operating with key-value pairs to obtain the required information.
This combination, supplemented by other technologies, for quite a long time allowed to cope with the indexing of the Internet, until ... the speed of information on the Internet began to grow at a tremendous pace due to the "social networking boom." Information added to the index even after half an hour, has often become outdated. In addition to this, within the framework of Google itself, more and more products designed to work in real time began to appear.
Designed with completely different requirements of the Internet five years ago, the components that make up the core of the Google platform required a fundamental change in the indexing and search architecture, which was introduced to the public about a year ago, codenamed Google Caffeine . New, revised, versions of the old “layers” were also dubbed bright names, but they caused much less response from the technical public than the new search algorithm in the SEO industry.
Google Colossus
The new GFS architecture was designed to minimize delays in accessing data (which is critical for applications like GMail and YouTube), not to the detriment of the main features of the old version: resiliency and transparent scalability.
In the original implementation, the emphasis was placed on increasing the overall throughput: the operations were combined in a queue and performed at once; with this approach, it was possible to wait a couple of seconds before the first operation in the queue began to be performed. In addition, in the old version there was a large weak spot in the form of the only master server with metadata, the failure in which threatened the inaccessibility of the entire file system for a short period of time (until the other server picked up its function, initially it took about 5 minutes, in recent versions about 10 seconds) - this was also quite acceptable in the absence of a real-time job requirement, but for applications that directly interact with users, this was unacceptable from the point of view of possible delays.
The main innovation in Colossus became distributed master servers, which made it possible to get rid of not only a single point of failure, but also significantly reduce the size of a single block with data (from 64 to 1 megabyte), which in general had a very positive effect on working with small amounts of data. As a bonus, the theoretical limit on the number of files in one system has disappeared.
Details of the distribution of responsibility between the master servers, scenarios of reaction to failures, as well as a comparison of the delays and bandwidths of both versions, unfortunately, are still confidential. I can assume that a variation on the hash-ring with the replication of metadata on ~ 3 master servers is used, with the creation of an additional copy on the next in a circle server in case of failures, but this is only a guess. If someone has relatively official information on this subject - I will be glad to see in the comments.
According to Google forecasts, the current implementation of the distributed file system “will retire” in 2014 due to the popularization of solid-state drives and a significant jump in the field of computing technologies (processors).
Google Percolator
MapReduce did an excellent job with the task of completely rebuilding the search index, but did not include small changes affecting only a fraction of the pages. Due to the streaming, consistent nature of MapReduce, in order to make changes to a small part of the documents, you would still have to update the entire index, since the new pages will certainly be somehow connected to the old ones. Thus, the delay between the appearance of a page on the Internet and in the search index using MapReduce was proportional to the total size of the index (and therefore the Internet, which is constantly growing), and not the size of the set of modified documents.
Key architectural solutions underlying MapReduce did not allow this feature to be affected, and as a result, the indexing system was rebuilt from scratch, and MapReduce continues to be used in other Google projects for analytics and other tasks that are not yet related to real time.
The new system has received a rather peculiar name Percolator , trying to find out what it means leads to various smoke filtering devices, coffee makers and something else that they don’t understand. But the most adequate explanation occurred to me when I read it in syllables: per col - in columns .
Percolator is an add-on to BigTable that allows you to perform complex calculations based on available data, affecting many rows and even tables at the same time (this is not provided in the standard BigTable API).
Web documents or any other data are modified / added to the system through the modified BigTable API, and further changes in the rest of the database are implemented via the “browser” mechanism. If we speak in terms of relational DBMS, then reviewers are a cross between triggers and stored procedures. Observers are a code connected to the database (on C ++), which is executed in case of changes in certain BigTable columns (from which, apparently, the name went). All metadata used by the system is also stored in special BigTable columns. При использовании Percolator все изменения происходят в транзакциях, удовлетворяющих принципу ACID, каждая из которых затрагивает именно те сервера в кластере, на которых необходимо внести изменения. Механизм транзакций на основе BigTable разрабатывался в рамках отдельного проекта под названием Google Megastore.
Таким образом, при добавлении нового документа (или его версии) в поисковый индекс, вызывается цепная реакция изменений в старых документах, скорее всего ограниченная по своей рекурсивности. Эта система при осуществлении случайного доступа поддерживает индекс в актуальном состоянии.
В качестве бонуса в этой схеме удалось избежать еще двух недостатков MapReduce:
- Проблемы «отстающих»: когда один из серверов (или одна из конкретных подзадач) оказывался существенно медленнее остальных, что также значительно задерживало общее время завершения работы кластера.
- Пиковая нагрузка: MapReduce не является непрерывным процессом, а разделяется на работы с ограниченной целью и временем исполнения. Таким образом помимо необходимости ручной настройки работ и их типов, кластер имеет очевидные периоды простоя и пиковой нагрузки, что ведет к неэффективному использованию вычислительных ресурсов.
Но все это оказалось не бесплатно: при переходе на новую систему удалось достичь той же скорости индексации, но при этом использовалось вдвое больше вычислительных ресурсов. Производительность Percolator находится где-то между производительностью MapReduce и производительностью традиционных СУБД. Так как Percolator является распределенной системой, для обработки фиксированного небольшого количества данных ей приходится использовать существенно больше ресурсов, чем традиционной СУБД; такова цена масштабируемости. По сравнению с MapReduce также пришлось платить дополнительными потребляемыми вычислительными ресурсами за возможность случайного доступа с низкой задержкой.
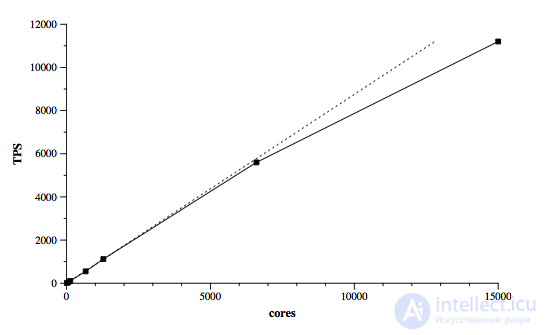
Тем не менее, при выбранной архитектуре Google удалось достичь практически линейного масштабирования при увеличении вычислительных мощностей на много порядков (см. график, основан на тесте TPC-E) . Дополнительные накладные расходы, связанные с распределенной природой решения, в некоторых случаях до 30 раз превосходят аналогичный показатель традиционных СУБД, но у данной системы есть солидный простор для оптимизации в этом направлении, чем Google активно и занимается.
Google Spanner
Spanner представляет собой единую систему автоматического управления ресурсами всего парка серверов Google.
Key Features:
- Единое пространство имен:
- Иерархия каталогов
- Независимость от физического расположения данных
- Поддержка слабой и сильной целостности данных между датацентрами
- Автоматизация:
- Перемещение и добавление реплик данных
- Выполнение вычислений с учетом ограничений и способов использования
- Выделение ресурсов на всех доступных серверах
- Зоны полу-автономного управления
- Восстановление целостности после потерь соединения между датацентрами
- Возможность указания пользователями высокоуровневых требований, например:
- 99% задержек при доступе к этим данным должны быть до 50 мс
- Расположи эти данные на как минимум 2 жестких дисках в Европе, 2 в США и 1 в Азии
- Интеграция не только с серверами, но и с сетевым оборудованием, а также системами охлаждения в датацентрах
Проектировалась из расчета на:
- 1-10 миллионов серверов
- ~10 триллионов директорий
- ~1000 петабайт данных
- 100-1000 датацентров по всему миру
- ~1 миллиард клиентских машин
Об этом проекте Google известно очень мало, официально он был представлен публике лишь однажды в 2009 году, с тех пор лишь местами упоминался сотрудниками без особой конкретики. Точно не известно развернута ли эта система на сегодняшний день и если да, то в какой части датацентров, а также каков статус реализации заявленного функционала.
Прочие компоненты платформы
Платформа Google в конечном итоге сводится к набору сетевых сервисов и библиотек для доступа к ним из различных языков программирования (в основном используются C/C++, Java, Python и Perl). Каждый продукт, разрабатываемый Google, в большинстве случаев использует эти библиотеки для осуществления доступа к данным, выполнения комплексных вычислений и других задач, вместо стандартных механизмов, предоставляемых операционной системой, языком программирования или opensource библиотеками.
Вышеизложенные проекты составляют лишь основу платформы Google, хотя она включает в себя куда больше готовых решений и библиотек, несколько примеров из публично доступных проектов:
- GWT для реализации пользовательских интерфейсов на Java;
- Closure — набор инструментов для работы с JavaScript;
- Protocol Buffers — не зависящий от языка программирования и платформы формат бинарной сериализации структурированных данных, используется при взаимодействии большинства компонентов системы внутри Google;
- LevelDB — высокопроизводительная встраиваемая СУБД;
- Snappy — быстрая компрессия данных, используется при хранении данных в GFS.
Подводим итоги
- Стабильные, проработанные и повторно используемые базовые компоненты проекта — залог её стремительного развития, а также создания новых проектов на той же кодовой базе .
- Если задачи и обстоятельства, с учетом которых проектировалась система, существенно изменились — не бойтесь вернуться на стадию проектирования и реализовать новое решение .
- Используйте инструменты, подходящие для решения каждой конкретной задачи , а не те, которые навязывает мода или привычки участников команды.
- Даже, казалось бы, незначительные недоработки и допущения на большом масштабе могут вылиться в огромные потери — уделяйте максимум внимания деталям при реализации проекта.
- Нельзя полагаться даже на очень дорогое оборудование — все ключевые сервисы должны работать минимум на двух серверах, в том числе и базы данных.
- Распределенная платформа, общая для всех проектов, позволит новым разработчикам легко вливаться в работу над конкретными продуктами, с минимумом представления о внутренней архитектуре компонентов платформы.
- Прозрачная работа приложений в нескольких датацентрах — одна из самых тяжелых задач, с которыми сталкиваются интернет-компании. Сегодня каждая из них решает её по-своему и держит подробности в секрете, что сильно замедляет развитие opensource решений.
Information sources
Не гарантирую достоверность всех нижеизложенных источников информации, ставших основой для данной статьи, но ввиду конфиденциальности подобной информации на большее рассчитывать не приходится.
Поправки и уточнения приветствуются
- Official Google Data Centers Site
- Challenges in Building Large-Scale Information Retrieval Systems (Jeff Dean, WCDMA '09)
- Designs, Lessons and Advice from Building Large Distributed Systems (Jeff Dean, Ladis '09)
- Google Percolator official paper
- Google Megastore official paper
- Google Percolator
- Google Caffeine Explained
- Google Spanner
- Google Software Infrastructure Dubbed Obsolete by ex-Employee
- Google Moves Off the Google File System
- Google Internet Stats
- Google Statistics
- Google Plus — Killer Facts and Statistics
- YouTube statistics
- Alexa on Google
- Internet World Stats
- Google Inc. financials
- Hotmail still on top worldwide; Gmail gets bigger
- Google Server Count
- Google Envisions 10 Million Servers
- Google Data Center FAQ
Бонус: типичный первый год кластера в Google
- ~½ перегрева (большинство серверов выключаются в течении 5 минут, 1-2 дня на восстановление)
- ~1 отказ распределителя питания (~500-1000 резко пропадают, ~6 часов на восстановление)
- ~1 передвижение стойки (много передвижений, 500-100 машин, 6 часов)
- ~1 перепрокладка сети (последовательной отключение ~5% серверов на протяжении 2 дней)
- ~20 отказов стоек (40-80 машин мгновенно исчезают, 1-6 часов на восстановление)
- ~5 стоек становится нестабильными (40-80 машин сталкиваются с 50% потерей пакетов)
- ~8 запланированных технических работ с сетью (при четырех могут случаться случайные получасовые потери соединения)
- ~12 перезагрузок маршрутизаторов (потеря DNS и внешних виртуальных IP на несколько минут)
- ~3 сбоя маршрутизаторов (восстановление в течении часа)
- Десятки небольших 30-секундных пропаданий DNS
- ~1000 сбоев конкретных серверов (~3 в день)
- Много тысяч сбоев жестких дисков, проблем с памятью, ошибок конфигурации и т.п.


Comments
To leave a comment
Highly loaded projects. Theory of parallel computing. Supercomputers. Distributed systems
Terms: Highly loaded projects. Theory of parallel computing. Supercomputers. Distributed systems