Lecture
It is difficult to agree with the seemingly heretical statement that two whales of modern computer technologies — the statistical information theory and computational architecture with programs stored in memory — have exhausted their potential and need a radical renewal. Nevertheless, this statement is true in many respects.
The theory of information by Claude Shannon, which, following the example of Shannon himself, should still be called the “theory of data transfer,” can in no way correspond to modern ideas about information. Recall that it arose as a response to the need to solve problems associated with data transfer, and proposes an appropriate measure for the transmitted data. In other words, the Shannon theory reflects the vision of information that was developed in connection with the data transfer processes. Therefore, it is quite natural that its scope cannot extend to many modern applications like processing unstructured data, working with multimedia content, etc. Strange as it may seem, IT specialists in the overwhelming majority do not know the theory of information, and the words “information” and “data” are often used as synonyms. It is significant that even the most diligent students of computer specialties who have attended a thorough course in information theory cannot relate the content of this course to the profile specialties. Because of the existing gap between the practical work with information and the theory of information, the technologies, called “information”, deal not with information at all, but with ordinary data. There is no single recognized idea of what information is and what technology is for it *.
The inability to establish a correspondence between data and information gives rise to, conditionally speaking, built on the knee technology. These include useful methods such as minimizing data duplication (that is, excluding data that correspond to the same information) or improving data quality (excluding different data sets that correspond to the same information). Fully sought-after, they are nonetheless based on intuitive representations, without any rigorous determination of how the data compares with the information contained in them. It is clear that such amateur work in the work with information can be a serious barrier. The exponential growth of the volumes of stored data, the shift towards unstructured data, the emergence of new data disciplines, the need to bring to the practical realization of old ideas like speech recognition are impossible without developing a new information theory . However, its formation is hampered by the so-called “mentality wall”.
Another “aged” whale is the archaic von Neumann architecture that has now become archaic. That it is the most serious brake on the way of further improvement of hardware and software. The moral aging of the von Neumann architecture leads to the fact that the entire data processing industry, despite its apparent prosperity, despite countless conversations about the information society, etc., inevitably approaches a critical state. What causes aging? The point is quantitative and qualitative growth. The computer world is becoming more and more tightly united with the real world. The special term “pervasive computing” has appeared. The computer has ceased to be a computer, an electronic computer, and it suddenly turned out that in its original form the computer did not quite match the environment. The real world in all its manifestations is parallel, and the modern computer world is consistent in nature: data is transmitted through serial channels, commands are executed one after another, as a result, any attempts to parallelize and adapt to the conditions of the real world give rise to extremely complex and artificial solutions.
One of the fundamental weaknesses of modern computers was revealed in 1977 by John Backus in a speech he gave when he received the Turing Prize. Since then, the phrase “von Neumann’s bottle throat”, which symbolizes the organic flaw in the architectural scheme associated with the name of John von Neumann, has been used. But in spite of everything, from 1945 and until now, the architectural scheme of von Neumann serves as the basis for all computers, with the exception of a small number of specialized microcontrollers built using the “Harvard scheme”, named after the Howard Aiken machine Harvard Mark I, where the programs were stored on perforated tapes, and the processed data - in relay arrays (Fig. 1). In modern microcontrollers, puncture tapes replaced the ROM memory, the relay — the RAM memory, but the essence remains the same: there are two independent commands and data flow in the processor. As a result, such specialized devices have the performance needed to work in technical systems in real time.
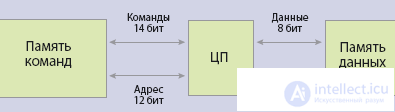
Fig. 1 (a). Architecture Neumann Background
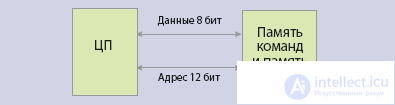
Fig. 1 (b). Harvard architecture
But if the crisis of von Neumann architecture comes, then why does a limited number of specialists think about it? Most likely, the reason for the tranquility of the majority is that the picture of apparent well-being artificially supports Moore's law **.
At first, Moore's law was perceived as a kind of incident. He was more surprised than he served as a guide to action, but over time, the correctness of the law ceased to be in doubt, and now there is confidence in its effectiveness for many years to come, with hopes for the future. It is significant that Moore’s law was widely spoken only five years ago; oddly enough, before that he was little known, and his exact wording was even more so. For a long time, it was mistakenly interpreted as the law of periodic doubling of performance, and only when the specific performance began to fall, was it remembered of the original formulation, which refers to the density of transistors on the chip. Until the complexity of the processors started to restrain further development, Moore's law was perceived solely as a guarantor of progress, but today the complexity has become a serious problem. Attitude to Moore's law and its place in computer history needs to be rethought. In the general evolutionary process, Moore's law plays a dual role, being both a brake and a stimulus at the same time.
A brake— or rather, a conservative factor — Moore’s law can be considered because for the good ten years he has allowed him to maintain the dynamics of development, dispensing with radical innovative steps. There was a kind of positive feedback; by increasing the number of transistors, the processor developers compensated for the lower quality of the architecture. As a result, performance continued to grow, but more slowly than the number of transistors. However, at what cost was it achieved? As shown in fig. 2, over the past decade, the specific performance of processors in terms of the number of transistors has fallen by one to two orders of magnitude. The further development of semiconductor technology according to Moore’s law cannot compensate for the monstrous inefficiency of modern processors. The disproportion between the number of transistors on a chip and the specific performance expressed in terms of speed, referred to the area, is sometimes called the “Moore Gap”.
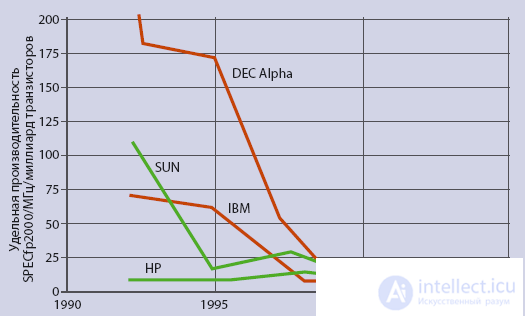
Fig. 2. The fall in the specific performance of processors. For six years, the specific performance of DEC Alpha decreased by 100 times, and IBM processors six times
But on the other hand, the quantitative growth postulated by Moore's law predetermines inevitable changes, and at some point the dialectical transition of quantity into quality should work. Legendary Dave Patterson, a professor at the University of California at Berkeley, the inventor of RISC processors and RAID arrays, believes that a new time is coming when the old truths will cease to operate and they will be replaced by new ones. However, this transition is complicated by the presence of three “walls”.
Some authors believe that there is another wall, the "wall of mentality" (educational wall). For 60 years of the existence of computers, a certain educational tradition has developed. For those who grew up as a specialist on unquestioned dogmas, it is not easy to recognize their vulnerability. Generally speaking, the imperfection and excessive cost of modern computer systems is becoming a popular topic of discussion. For example, Bill Inmon spoke about this recently, during his stay in Moscow. The “father” of data warehouses indicates that all modern solutions for working with data are united by the fact that the cost of functional components (transistors, drives, etc.) is becoming less and less important, while the main cost of products falls on supporting infrastructure.
In addition to the obvious technological claims to the von Neumann architecture (excessive complexity, inability to parallelize, low efficiency of the use of transistors, etc.), there is another group of claims. It is worth remembering what a few decades ago hopes were pinned on artificial intelligence, how smart future machines seemed, and how it all ended in failure. Adherents of artificial intelligence see the reason for failures in the monopoly position of one architecture, which is capable of impeccably performing a limited set of actions, but is unable to adapt to solving problems with intellectual elements. It is impossible to recognize that the monsters from IBM, by the method of busting the beating grandmasters, really play chess. The same can be said about various recognition tasks and many other things. Von Neumann machines (in fact, sequential digital processors) are capable of accepting a single input stream of ones and zeros and processing data consisting of the same ones and zeros. In order to adapt the machine to solve intellectual problems, there are only very limited language capabilities. Over time, they are exhausted, and there is no reason to talk about any real use of modern computers for solving intellectual problems. But this does not mean that computers are in principle only suitable for solving routine tasks. Sooner or later they must become human intellectual assistants, as Vannevar Bush and Doug Engelbart represented them.
However, claims to the von Neumann scheme by failed researchers cannot be taken as the main critical argument. An effective reason for a radical revision of the fundamental computer architecture can be changed business requirements, and direct stimuli are the problems of increasing the complexity of single-core processors and multi-core as the only cure for this complexity.
Let us return to the duplicity of Moore's law. The history of the Itanium processor perfectly illustrates how it can be used to preserve the current paradigm. In a year, it will be 20 years since that memorable moment, when HP, having come to the conclusion that RISC’s future development of the architecture was limited, opted for a more promising architecture with obvious parallelism EPIC, which allows to execute a very long command word in one clock cycle. But both they and those who became their ally miscalculated; Contrary to expectations, a processor with one core (and they did not know about others then) turned out to be incredibly complex, and compilers able to realize its capabilities were even harder. The period of development itself was delayed for 12 years, but after seven more years of refinement the desired result remains unachieved. Products built on Itanium could not compete with either RISC servers (according to Gartner, in 2007 they were released an order of magnitude more than servers on Itanium), nor even the standard servers on x86 processors, which were planned to replace Itanium. (here it is inferior to more than two orders of magnitude). Even in the HPC segment, where the seemingly superior performance on floating-point operations gives Itanium advantages, it lags behind; in the current Top 500 list, it accounts for only 3.2% of the total number of supercomputers.
It is not difficult to conclude that if one cannot use the possibilities of Moore's law on one core due to the exceptional complexity of such a core, then one should take the path of increasing the number of cores. This is exactly what Sun Microsystems did by releasing an 8-core Niagara processor. The idea of multi-core became obvious for those who staked on EPIC, and at the next IDF forum in the fall of 2004, Paul Otellini, general director of Intel, said: “We connect our future with multi-core products; we believe that this is a key inflection point for the entire industry ”***. At that time, this prospect was considered to be limited, therefore Otellini’s words referred to the quite expected dual-core or quad-core processors and did not pay special attention to the transparent hint about the predicted bend. Aside from public attention, there was one more significant statement about the future increase in the number of nuclei, made by him at the same time: “This is not a race. This is a radical change in computing, we have no right to consider what is happening as a simple technological race. ”
Three years later, one of the most respected modern specialists in the field of multi-core processor architectures, a professor at the Massachusetts Institute of Technology, Anand Agarwal, speaking at a conference on the problems of modern processors, having his own development experience at the Tilera company founded by him, “ the system becomes more uniform and impersonal, the system becomes more critical, and then gave an aphorism: "The processor is the transistor of modernity."
His idea was developed by Andy Bechtolsheim of Sun Microsystems: “Performance can no longer be viewed as a serious limitation. Now the main limitation is I / O, and I / O performance cannot be improved by simply increasing the density of transistors. ”
One can speak of two noticeably different trends in the process of increasing the number of nuclei. One is now called multi-core, in this case it is assumed that the cores are high-performance and relatively few; now their number is two to four, and according to Moore's law, it will periodically double. This path has two main disadvantages: the first is high energy consumption, the second is the high complexity of the chip and, as a result, the low percentage of the output of finished products. When producing an 8-core IBM Cell processor, only 20% of the crystals produced are usable. The other way is multi-core (many-core). In this case, a larger number, but at the same time, the simplest milliwatts, is assembled on the crystal. Suppose there are one hundred cores for the beginning, but this number doubles with the same frequency, and consequently, processors with thousands and tens of thousands of cores will appear in the foreseeable future. This approach falls into the category of so-called “disruptive innovation”. This kind of technology hacks into existing markets; For example, before our eyes, the replacement of hard drives with solid-state drives begins, digital photography has replaced analog.
Впрочем, эти революционные процессы прошли или происходят достаточно безболезненно для потребителей, чего нельзя сказать о многоядерности. Действительно, ни одна из современных школ программирования не в состоянии справиться с грядущими проблемами, не случайно на суперкомпьютерной конференции, прошедшей в Дрездене в 2007 году, один из центральных докладов назывался «Развал системы традиционных знаний в многоядерную эру. Все, что вы знаете,— неверно».
Очевидно, что увеличение в десятки и сотни раз числа все тех же фон-неймановских ядер на одной подложке не является панацеей. В недавнем интервью не нуждающийся в представлении Дональд Кнут сказал по поводу упрощенного подхода к увеличению числа ядер следующее: «Мне кажется, у проектировщиков процессоров иссякли идеи, и они хотят переложить ответственность за невозможность повышать производительность компьютеров в соответствии с законом Мура на тех, кто создает программы. Они предлагают процессоры, отлично работающие на отдельных тестах, но я не удивлюсь, что вся эта эпопея многоядерности закончится не меньшим провалом, чем Itanium, где все выглядело прекрасным, пока не выяснилось, что компиляторы с соответствующими ему возможностями предвидения невозможно написать.
Сколько вы знаете программистов, относящихся с энтузиазмом к будущим многоядерным процессорам? У всех, кого я знаю, они лишь вызывают огорчение, хотя разработчики процессоров говорят, что я не прав. Я знаю приложения, адаптируемые к параллельному исполнению; это графический рендеринг, сканирование изображений, моделирование биологических и физических процессов, но все они требуют подходов, которые чрезвычайно специализированы. Моих знаний хватило, чтобы написать о них в 'Искусстве программирования', но я считаю время, затраченное на них, потерянным, в этой области все быстро меняется, и совсем скоро написанное мной никому не будет нужным. Мультиядерность в том виде, как ее представляют, сейчас не прибавляет мне счастья».
Что же получается? Одноядерные процессоры бесперспективны, в этом убеждает пример Itanium. Но и многоядерные процессоры, если все сводится к размещению большего числа классических простых ядер на одной подложке, нельзя воспринимать как решение всех проблем. Их чрезвычайно сложно программировать, они могут быть эффективны только на приложениях, обладающих естественной многопотоковостью, таковых особенно много среди Web-приложений, но как быть со сложными задачами? Где же выход? Когда-то в моде была бионика, наука о применении в технических системах принципов организации, свойств, функций и структур живой природы. Пик бионических публикаций о промышленных аналогах форм живой природы пришелся на 60-е годы, потом о ней почти забыли. Многоядерность заставляет о ней вспомнить: из общих системных соображений понятно, что, если ядер будет много и количество их будет продолжать увеличиваться, то дальше все будет развиваться по сценарию биологической эволюции, когда вслед за одноклеточными организмами появились их многоклеточные преемники, а затем и еще более сложные создания. Однако остаются аргументы, высказываемые Кнутом. Какими должны стать эти ядра, чтобы не перекладывать ответственность на программистов?
The transition to a new world with new truths, to the world as Patterson represents it, is impossible without an understanding of the fundamental causes of the crisis of the old world. One of the most interesting points of view on the origin of the "walls" and other shortcomings of the existing computer world order has a German professor Reiner Hartenstein. He has extensive experience in teaching and research at leading universities in Germany and at the University of Berkeley. Since 1977, the head of the laboratory Xputer Lab, one of the few where he was engaged in topics related to reconfigurable computing (Reconfigurable Computing), Хартенштайн является создателем KARL, новаторского языка для проектирования аппаратного обеспечения. Профессор Хартенштайн— автор таких терминов, как «антимашина» (anti machine), «конфигурируемое аппаратное обеспечение» (сonfigware), «структурное проектирование аппаратного обеспечения» (structured hardware design) и ряда других. Реконфигурирование— это перепрограммирование аппаратуры; теоретически его можно применять к массивам, собранным из ядер с фон-неймановской архитектурой, но гораздо перспективнее— к ядрам, представляющим собой антимашины.
В последние годы Хартенштайна, как многих ветеранов, приглашают в качестве докладчика на многочисленные конференции и семинары. Основную тему, с которой он выступает, сегодня называют «синдромом фон Неймана». Авторство этого термина приписывают профессору из Беркли Чандуру Рамамути, однажды прослушавшему выступление Хартенштайна, а затем образно выразившему его взгляды. (Сам Рамамути в ряде своих работ показал, что чаще всего компьютеры с массовым параллелизмом, содержащие тысячи и десятки тысяч процессоров, оказываются менее продуктивными, чем ожидается при их проектировании. Основные причины этого эффекта, называемого самим Рамамути «суперкомпьютерным кризисом»,— наличие «стены памяти» и сложность программирования параллельных задач, что тоже является следствием фон-неймановской архитектуры.)
Целесообразно уточнить использование слова «синдром» в данном контексте. В русском языке его употребляют в медицинском смысле, как комплекс симптомов, но в данном случае его следует понимать шире, как цепь взаимосвязанных событий или сочетание явлений. В интерпретации Хартенштайна «синдром фон Неймана»— это цепочка событий, приведшая компьютерные технологии от изобретения архитектуры фон Неймана к нынешнему состоянию, хотя можно его понимать и в медицинском смысле, как застарелую болезнь. В качестве философской предпосылки для своих рассуждений Хартенштайн ссылается на Артура Шопенгауэра, писавшего: «Примерно каждые 30 лет наука, литература, искусство переживают период банкротства, коллапсируя под тяжестью накопленных ошибок». Хартенштайн считает, что в компьютерных технологиях и в компьютерных науках наступление кризиса было отложено лет на 30 благодаря опережающему развитию полупроводниковых технологий, зафиксированному в законе Мура.
Главный вывод Хартенштайна состоит в том, что и энергетическая стена, и стена памяти, и стена параллелизма на уровне команд являются прямым следствием фон-неймановской архитектуры. Из-за технологических ограничений Джоном фон Нейманом была избрана схема, в основе которой лежит управляемый поток команд, программа, выбирающая необходимые для команд данные. Этим определяется канонический состав архитектурных компонентов, составляющих любой компьютер,— счетчик команд, код операции и адреса операндов; он остается неизменным по сей день. Все мыслимые и немыслимые усовершенствования архитектуры фон Неймана в конечном счете сводятся к повышению качества управления потоком команд, методам адресации данных и команд, кэшированию памяти и т.п. При этом последовательная архитектура не меняется, но сложность ее возрастает. Очевидно, что представление о компьютере как об устройстве, выполняющем заданную последовательность команд, лучше всего подходит для тех случаев, когда объем обрабатываемых данных невелик, а данные являются статическими. Но в современных условиях приходится сталкиваться с приложениями, где относительно небольшое количество команд обрабатывает потоки данных. В таком случае целесообразно предположить, что компьютером может быть и устройство, которое имеет каким-то образом зашитые в него алгоритмы и способно обрабатывать потоки данных. Такие компьютеры могли бы обладать естественным параллелизмом, а их программирование свелось бы к распределению функций между большим числом ядер.
So, we can assume the existence of two alternative schemes. One, von Neumann, assumes that the computational process is controlled by a stream of commands, and the data, mostly static, are selected from some storage systems or from memory. The second scheme is based on the fact that the computation process is controlled by the input data streams that enter the prepared computing infrastructure with natural parallelism at the system input. From the point of view of implementation, the first scheme is much simpler, in addition, it is universal, programs are compiled and written into memory, and the second requires a special assembly of the necessary hardware configuration for a particular task. Most likely, these two schemes should coexist, reflecting the two sides of computing, a kind of yang and yin. Oddly enough, but the second scheme is older; An example of this is the tabulators invented by Herman Hollerith and successfully used for several decades. IBM has reached its power and has become one of the most influential companies in the United States, producing electromechanical tabs for processing large amounts of information that does not require logical operations. Their programming was carried out by means of switching on the remote control, and then the control device coordinated the work of other devices in accordance with a given program.
The antipode of the von Neumann machine is in almost all of its properties (see the table) antisymmetric to it, therefore Hartenstein called it anti-machine. The antimachine differs from the von Neumann machine by the presence of one or several data counters that control the flow of data, it is programmed using streaming software (Flowware), and the role of the central processor in it is played by one or more data processors (Data Path Unit, DPU). The central part of the anti-machine can be a memory with an automatic sequence (Auto-Sequence Memory).
Table.

Antisymmetry between the machine and the anti-machine is observed in everything, except that the anti-machine allows for parallelism of internal cycles, which means that it solves the problem of parallel data processing.
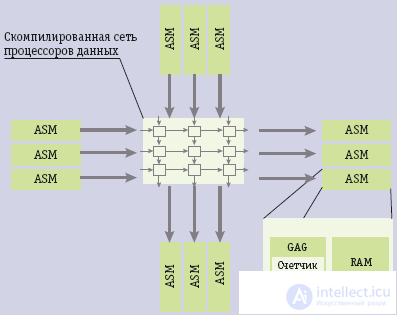
Fig. 3. The general scheme of anti-cars
In anti-machine access to the memory is provided not by the address of the command or data fragment recorded in the corresponding register, but by means of the universal address generator (Generic Address Generator, GAG). Its advantage is that it allows the transmission of blocks and data streams. At the same time, compilation, through which a specialized system is created for a specific task, is to combine the required number of configured data processors into a common array (Data Process Array, DPA), which runs Flowware algorithms and which can be reconfigurable.
The GAG methodology is inconsistent, and therefore has such advantages as the ability to work with two-dimensional addresses, which provides undeniable advantages when working with video data and when performing parallel calculations. Data counter - an alternative to the command counter in the von Neumann machine; its content is managed by Flowware. For the new methodology, a new name was invented - twin.paradigm; it reflects the symbiosis of the computational cores of the two classes, both ordinary central processors, built on a von Neumann scheme, and data processors that implement anti-machines.
The main differences between the anti-machine and the von Neumann machine are that the anti-machine is by its nature parallel and, moreover, non-static — it needs to be programmed itself, and not just load various programs into a universal machine. Fortunately, there are developments that can at least give an idea of how and from what an anti-machine can be assembled. It can be implemented by means of reconfigurable computing (however, it should be noted that anti-engine and reconfigurable computing are not the same thing).
Reconfigurable computing has been actively talked about in recent years, but the very idea of adapting hardware for a specific task is far from new. She was nominated in 1959 by the physicist and mathematician John Pasta, who was, surprisingly, a colleague of John von Neumann and, together with Enrico Fermi, worked on the creation of the atomic bomb. In addition to his other achievements, he is known for being the first to use a computer as a tool for modeling physical processes. His experience allowed him to conclude that the manufacturers of commercial computers from the very first steps lost interest in the development of alternative computer architectures, concentrating entirely on the von Neumann architecture. And then Pasta decided that first it was necessary to perform a certain amount of academic research and thereby create an incentive to continue similar work in the private sector. He shared his thoughts on adaptable computer architectures with Gerald Estrin, a staff member at the University of California at Los Angeles, who by that time had a good track record, having managed to build the first Israeli computer WEIZAC (Weizmann Automatic Computer). A year later, in 1960, Estrin spoke at the Western Joint Computer Conference conference, well-known in those years, with the report "Organization of a computer system consisting of constant and variable structures." The purpose of Estrin's work was to develop computing systems that differ from traditional ones in that they were a set of modules for building specialized computers for a specific task. Subsequently, an attempt was made to create a modular kit from which reconfigurable computers could be assembled, but on the technological foundation of the early 60s it was unsuccessful, but nevertheless the theoretical foundations were formulated.
The technological mainstream pushed Estrin’s work to the side of the road, but occasionally they remembered it. Thus, in the experimental computer PDP-16, intended for control of technological processes, which was built by the corporation Digital Equipment in the 70s, the Register-Transfer Modules modular scheme was implemented. The PDP-16 was a kind of constructor from which it was possible to assemble a computer adapted to specific control algorithms.
Theoretically, there are three possible approaches to the creation of reconfigurable processors.
The first two categories acquire their own specifics in the manufacturing process, and the third can be programmed; we will dwell on her in more detail.
About 15-20 years ago, several attempts were made to create a hybrid processor consisting of variable and constant parts. Then they remembered Estrin; he was even devoted to a special publication in The Economist magazine "The reconfigurable systems are preparing for resuscitation." The opportunity for reconfiguration was created by Xilinx's programmable logic arrays that had appeared by that time, and immediate interest was caused by the emergence of a PRISM (Processor Reconfiguration through Instruction-Set Metamorphosis) architecture, where core operations could be expanded to speed up individual applications. One of the most well-known processors with reconfiguration capabilities was Garp, developed at Berkeley, which combined the MIPS core and FPGA-based infrastructure.
From this wave, a generation of reconfigurable signal processors has grown. The most interesting of the modern projects is the XiRix processor developed in Italy (Extended Instruction Set Risc). Those who are seriously interested in programming such processors should turn to Caudio Mucci's dissertation in the Network (Software tools for embedded reconfigurable processors).
Hot heads were carried away by the idea of reconfiguration. In 1995, Gartner analyst Jordan Selbourne suggested that over the next ten years the market of reconfigurable chips would amount to $ 50 billion, but this forecast did not come true? Most likely because even then the level of development of semiconductor technologies was insufficient. But the lessons should be learned from unsuccessful predictions, in particular, from what the embedded processors can teach.
As a rule, signal processors are built on the Harvard architecture, with the separation of command and data memory, so their reconfiguration is simpler and more natural. These processors have always constituted a separate subset, which, due to its specificity, does not intersect with the main set of computing processors. But it is worth thinking about why this separation has developed and whether it will remain forever. The developers of the signal processors were put in conditions when they needed to meet the requirements of the surrounding world, and they offered their “microsolution”. Pervasive computer systems extend similar requirements to a wider range of applications. It seems that some approaches, including reconfiguration, which originated in the development of embedded processors, will be distributed to the macro level.
For the general enthusiasm for high-performance clusters, the activities of Cray, SGI and SRC companies, which actively use FPGA-based computing accelerators, remain not very noticeable. Such devices are equipped with Cray XD1 machines and SGI Reconfigurable Application-Specific Computing (RASC) server. According to analysts, these solutions are examples that indicate that FPGAs can be used outside traditional embedded applications.
SRC, created by Seymour Cream shortly before his death, links his entire production program with reconfigurable computer systems. It develops the Implicit + Explicit architecture, consisting of the traditional components of a Dense Logic Device and reconfigurable Direct Execution Logic devices. The SRC Carte Programming Environment software environment supports C and Fortran programming, without requiring the programmer to have knowledge related to hardware programming.
Foreseeing a global crisis raises more questions than answers. This topic concerns the best minds, but they are also in difficulty. The same Dave Patterson said: “All that we can now is to include certain things that are understandable today in graduate programs. We must inform students about upcoming trends, admitting honestly that we do not yet know what the next model of computing will be. ”
One thing is for sure, the great epoch is ending. Its symbol is the mainframe, with which it all began and that all, apparently, and will end. The mainframe is the highest point of the von Neumann architecture, the most universal of all universal computers.
* Over the years, I have been doing an experiment, offering to give a definition of what information is to dozens of authoritative domestic and foreign representatives of the computer community. None of them gave a direct and strict answer. In the overwhelming majority of cases, first “well, you know” followed with a hint that the question was not completely correct, and then, after some embarrassment, something like “this is data plus metadata” or something else in the same way. . the author.
** It should be noted that this “world constant” managing branch was first noticed not by Gordon Moore, as many people think, but by the great Doug Engelbart. It was he who made a forecast about the periodic doubling of density in 1960, five years before the appearance of the famous article by Moore . - Comm . the author.
*** To emphasize the degree of radicalization of the upcoming transformations, Otellini used a very strong and emphatically elitist epithet sea change. This expression is first encountered in Shakespeare, and it was introduced by the American poet Ezra Pound into the modern revolution. Such expressions do not choose randomly . - Approx. the author.

Comments
To leave a comment
Highly loaded projects. Theory of parallel computing. Supercomputers. Distributed systems
Terms: Highly loaded projects. Theory of parallel computing. Supercomputers. Distributed systems