Lecture
Before proceeding with the direct presentation of the algorithms themselves, let us recall the internal structure of the hard disk and determine which query parameters we can use for planning.
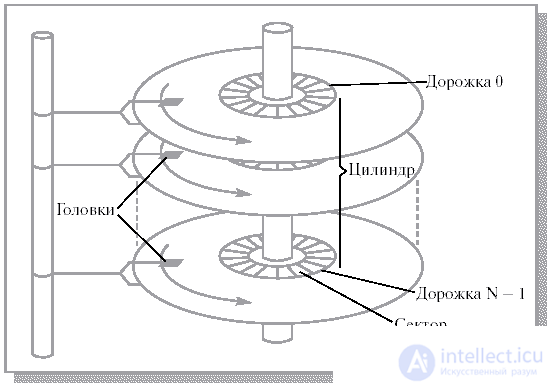
A modern hard magnetic disk is a set of circular plates that are on the same axis and are covered on one or both sides with a special magnetic layer (see. Fig. 13.2). Magnetic heads are located near each working surface of each plate for reading and writing information. These heads are attached to a special lever that can move the entire block of heads over the surfaces of the plates as a whole. The surfaces of the plates are divided into concentric rings, inside which, in fact, information can be stored. A set of concentric rings on all plates for one position of the heads (i.e., all rings equidistant from the axis) forms a cylinder. Each ring inside the cylinder received the name of the track (one or two tracks on each plate). All tracks are divided into an equal number of sectors. The number of tracks, cylinders and sectors can vary from one hard disk to another within fairly wide limits. As a rule, a sector is the minimum amount of information that can be read from a disk at a time.
When the disk is in operation, the set of plates rotates around its axis at high speed, substituting all their sectors in turn under the heads of the corresponding tracks. The sector number, track number and cylinder number unambiguously determine the position of the data on the hard disk and, along with the type of operation performed - read or write, fully characterize the part of the query associated with the device when exchanging information within the scope of one sector.
When planning to use a hard disk, the natural scheduling parameter is the time it takes to complete the next request. The time required to read or write a specific sector on a certain track of a certain cylinder can be divided into two components: the time of information exchange between the magnetic head and the computer, which usually does not depend on the position of the data and is determined by their transfer speed (transfer speed), and The positioning time necessary for positioning the head over a given sector is the positioning time. Positioning time, in turn, consists of the time required to move the heads to the desired cylinder, the seek time and the time it takes for the desired sector to turn under the head, rotational latency. Search times are proportional to the difference between the cylinder numbers of the previous and planned queries, and they are easy to compare. The rotational delay is determined by rather complicated relations between the numbers of cylinders and sectors of the previous and planned requests and the speeds of rotation of the disk and movement of the heads. Without knowledge of the correlation of these velocities, comparison becomes impossible. Therefore, it is natural that the set of planning parameters is reduced to the search time for various queries, determined by the current position of the head and the numbers of the required cylinders, and the difference in rotational delays is neglected.
The simplest algorithm that we should have gotten used to is the First Come First Served (FCFS) algorithm — first come, first served. All requests are organized into a FIFO queue and serviced in the order received. The algorithm is simple to implement, but it can lead to a fairly long total query service time. Consider an example. Suppose we have on the disk of 100 cylinders (from 0 to 99) there is the following request queue: 23, 67, 55, 14, 31, 7, 84, 10 and heads at the initial moment are on the 63rd cylinder. Then the position of the heads will change as follows:
63-> 23-> 67-> 55-> 14-> 31-> 7-> 84-> 10
and the entire head will move to 329 cylinders. The inefficiency of the algorithm is well illustrated by the last two movements from the 7th cylinder through the entire disk to the 84th cylinder and then again through the entire disk to the cylinder 10. Simple replacement of the order of the last two movements (7  ten 84) would significantly reduce the total service time requests. So let's move on to a different algorithm.
ten 84) would significantly reduce the total service time requests. So let's move on to a different algorithm.
As we have seen, it is quite reasonable to prioritize service requests, the data for which lie next to the current position of the heads, and only then far away. Algorithm Short Seek Time First (SSTF) - a short search time first - just comes from this position. For the next service, we will choose the request, the data for which lie closest to the current position of the magnetic heads. Naturally, in the presence of equidistant requests, the decision on the choice between them can be made on the basis of various considerations, for example, using the FCFS algorithm. For the previous example, the algorithm will give the following sequence of head positions:
63-> 67-> 55-> 31-> 23-> 14-> 10-> 7-> 84
and the whole head will move to 141 cylinder. Note that our algorithm is similar to the SJF process planning algorithm, if for the analogue of estimating the time of the next CPU burst process, choose the distance between the current head position and the position required to satisfy the request. And just like the SJF algorithm, it can lead to a long delay in the execution of a query. It is necessary to remember that requests in the queue can appear at any time. If we have all requests, except one, are constantly grouped in areas with large cylinder numbers, then this one request can be in the queue indefinitely.
The exact SJF algorithm was optimal for a given set of processes with given CPU burst times. Obviously, the SSTF algorithm is not optimal. If we transfer the service of the request of the 67th cylinder to the interval between the requests of the 7th and 84th cylinders, we will reduce the total service time. This observation leads us to the idea of a whole family of other algorithms - scanning algorithms.
In the simplest of scanning algorithms - SCAN - heads are constantly moving from one edge of the disk to the other, along the way serving all encountered requests. Upon reaching the other edge, the direction of movement changes, and everything repeats again. Suppose that in the previous example, at the initial time, the heads move in the direction of decreasing cylinder numbers. Then we get the order of service requests, peeped at the end of the previous section. The sequence of moving the heads is as follows:
63-> 55-> 31-> 23-> 14-> 10-> 7-> 0-> 67-> 84
and the entire head will move to 147 cylinders.
If we know that we have served the last passing request in the direction of the movement of the heads, then we can not reach the edge of the disk, but immediately change the direction of movement to the opposite:
63-> 55-> 31-> 23-> 14-> 10-> 7-> 67-> 84
and the whole head will move to 133 cylinder. The resulting modification of the SCAN algorithm is called LOOK.
Suppose that by the time the head changes direction in the SCAN algorithm, that is, when the head has reached one of the disk edges, this edge has accumulated a large number of new requests, which will take a lot of time to service (don't forget that not only move the head, but also transfer the read data!). Then requests related to the other edge of the disk and received earlier will wait for service unfairly long. To shorten the waiting time for requests, another modification of the SCAN algorithm is applied - a cyclic scan. When the head reaches one of the edges of the disk, it moves to the other edge without reading passing requests (sometimes significantly faster than when performing a normal cylinder search), from where it starts moving in the same direction again. For this algorithm, called C-SCAN, the sequence of movements will look like this:
63-> 55-> 31-> 23-> 14-> 10-> 7-> 0-> 99-> 84-> 67
By analogy with the LOOK algorithm for the SCAN algorithm, the C-LOOK algorithm for the C-SCAN algorithm can also be proposed:
63-> 55-> 31-> 23-> 14-> 10-> 7-> 84-> 67
There are other types of scanning algorithms, and very different algorithms, but we will end there, because it was said: "And I say it again: no one will embrace the immense."
As you can see, the algorithm is not very effective, but easy to implement.
The algorithm is more efficient, but it has a drawback: if new requests are constantly being received, the head will always be in a local place, most likely in the middle part of the disk from the edge of the border can never be out of sight.
The SCAN-heads algorithm constantly moves from one edge of the disk to the other edge, while cheating all the encountered requests. Simple, but not always effective.
The LOOK algorithm — if it is known that the last passing request was served in the direction of the heads movement, it may not reach the edge of the disk, but immediately change the direction of movement in the opposite direction.
Algorithm C-SCAN-cyclic sanitization when the head reaches one of the edges of the disk, it moves to the zero cylinder, from where it reads in passing requests, from where it starts moving again.

Comments
To leave a comment
Electromechanical devices of electronic devices
Terms: Electromechanical devices of electronic devices