Lecture
The Turing test proposed by Alan Turing was developed as a satisfactory functional definition of intelligence. Turing decided that it makes no sense to develop an extensive list of requirements for creating artificial intelligence, which, moreover, may be contradictory, and proposed a test based on the fact that the behavior of an object with artificial intelligence cannot be ultimately distinguished from the behavior of such undoubtedly intellectual entities like human beings. The computer will successfully pass this test if the experimenter who asked certain questions in writing cannot determine whether written answers were received from another person or from some device. Chapter 26 discusses this test in detail and discusses whether a computer that successfully passed a similar test can truly be considered an intelligent computer. At the moment, we simply note that the solution of the problem of drawing up a program for a computer in order for it to pass this test requires a lot of work. A computer programmed in this way must have the following capabilities.
- Means of word processing in natural languages (Natural Language Processing — NLP), which allow to communicate successfully with a computer, say in English.
- Means of knowledge representation, with the help of which a computer can write into memory what it learns or reads.
- Means of automatic generation of logical conclusions, providing the ability to use stored information to search for answers to questions and display new conclusions.
- Machine learning tools that allow you to adapt to new circumstances, as well as detect and extrapolate signs of standard situations.
In the Turing test, direct physical interaction between the experimenter and the computer is deliberately excluded, since the creation of artificial intelligence does not require physical imitation of a person. But in the so-called full Turing test, the use of a video signal is provided so that the experimenter can test the subject's ability to perceive, and also had the opportunity to present physical objects "in incomplete form" (pass them "through the hatching"). To pass the full Turing test, the computer must have the following abilities.
- Machine vision for perception of objects.
- Means of robotics for manipulating objects and moving in space.
The six research directions listed in this section constitute the main part of artificial intelligence, and Turing deserves our thanks for having offered such a test, which has not lost its significance even after 50 years. Nevertheless, researchers of artificial intelligence practically do not solve the problem of passing the Turing test, believing that it is much more important to study the fundamental principles of intelligence than to duplicate one of the carriers of natural intelligence. In particular, the problem of “artificial flight” was successfully solved only after the Wright brothers and other researchers stopped imitating birds and began to study aerodynamics. In scientific and technical works on aeronautics, the goal of this field of knowledge is not defined as “creating machines that during their flight resemble pigeons so much that they can even deceive real birds.”
The Turing test is an empirical test, the idea of which was proposed by Alan Turing in the article “Computers and Mind”, published in 1950 in the philosophical journal Mind . Turing set out to determine whether the machine can think.
The standard interpretation of this test is: “ A person interacts with one computer and one person. Based on the answers to the questions, he must determine with whom he is talking: with a person or a computer program. The task of a computer program is to mislead a person by making a wrong choice . ”
All test participants do not see each other. If the judge cannot say for sure which interlocutor is a person, then the car is considered to have passed the test. In order to test the intellect of the machine, and not its ability to recognize oral speech, the conversation is conducted in the “text only” mode, for example, using the keyboard and screen (computer intermediary). Correspondence should be made at controlled intervals so that the judge cannot draw conclusions based on the speed of replies. In the times of Turing, computers reacted more slowly than humans. Now this rule is also necessary, because they react much faster than people.
Although research in the field of artificial intelligence began in 1956, their philosophical roots go deep into the past. The question whether a car can think or not has a long history. It is closely related to the differences between dualistic and materialistic views. From the point of view of dualism, thought is not material (or, at least, has no material properties), and therefore reason cannot be explained only with the help of physical concepts. On the other hand, materialism says that the mind can be explained physically (for example, as a combination of a set of ones and zeros, protruding data and / or commands of the being), thus leaving the possibility of the existence of minds created artificially.
In 1936, the philosopher Alfred Ayer considered the usual question for philosophy regarding other minds: how do you know that other people have the same conscious experience as we do? In his book Language, Truth and Logic, Ayer proposed an algorithm for recognizing a conscious person and a non-aware machine: “The only basis on which I can say that an object that seems reasonable is not really a rational being, but simply a stupid machine, is that he cannot pass one of the empirical tests, according to which the presence or absence of consciousness is determined. ” This statement is very similar to the Turing test; however, it is not precisely known whether the popular philosophical classic Ayer was known to Turing.
Despite the fact that more than 50 years have passed, the Turing test has not lost its significance. But at present, researchers of artificial intelligence are practically not engaged in solving the problem of passing the Turing test, believing that it is much more important to study the fundamental principles of intelligence than to duplicate one of the carriers of natural intelligence. In particular, the problem of “artificial flight” was successfully solved only after the Wright brothers and other researchers stopped imitating birds and began to study aerodynamics. In scientific and technical works on aeronautics, the goal of this field of knowledge is not defined as “the creation of machines that in their flight resemble pigeons so much that they can even deceive real birds.” [one]
By 1956, British scientists have been exploring “machine intelligence” for 10 years. This question was a common subject for discussion among members of the Ratio Club, an informal group of British cybernetics and electronics researchers, in which Alan Turing was a member, after whom the test was named.
Turing was particularly concerned with the problem of machine intelligence, at least since 1941. One of his first mentions of "computer intelligence" was made in 1947. In the “Intelligent Machines” report, Turing explored the question of whether a machine can detect rational behavior, and as part of this study, he suggested what might be considered the forerunner of his further research: “It is not difficult to develop a machine that will play chess well. Now take three people - subjects of the experiment. A, B and C. Let A and C play chess unimportantly, and B the machine operator. [...] Two rooms are used, as well as some mechanism for transmitting progress messages. Participant C plays either with A or with the machine. Participant C may not be able to answer with whom he plays. ”
Thus, by the time of publication in 1950 of the article “Computers and Mind”, Turing had been considering the possibility of the existence of artificial intelligence for many years. However, this article was the first Turing article, which dealt exclusively with this concept.
Turing begins his article with the statement: "I propose to consider the question" Can machines think? "." He emphasizes that the traditional approach to this issue is to first define the concepts of "machine" and "intelligence". Turing, however, chose a different path; instead, he replaced the original question with another, “which is closely related to the original one and is formulated relatively unambiguously.” In essence, he proposes to replace the question “Do machines think?” With the question “Can machines do what we (as thinking creatures) can do?” The advantage of the new question, according to Turing, is that it draws a “clear line between the physical and intellectual capabilities of a person.”
To demonstrate this approach, Turing offers a test designed by analogy with a game for parties “Imitation game” - an imitation game. In this game, a man and a woman are sent to different rooms, and the guests try to distinguish them by asking them a series of written questions and reading typed answers to them. According to the rules of the game, both the man and the woman try to convince the guests that the opposite is true. Turing proposes to remake the game as follows: “Now we ask the question, what happens if in this game machine A plays the role? Does the questioner make mistakes as often as if he played with a man and a woman? These questions replace the original one.” Can a car think? ”.
In the same report, Turing later proposes an "equivalent" alternative wording, including a judge who talks only with a computer and a person. Along with the fact that none of these formulations exactly correspond to the version of the Turing test that is most known today, in 1952 the scientist proposed a third one. In this version of the test, which Turing discussed on the BBC Radio, the jury asks the computer questions, and the role of the computer is to make a significant part of the jury members believe that he is actually a man.
The Turing article takes into account 9 proposed questions, which include all the main objections against artificial intelligence raised after the article was first published.
Bleigh Whitby points to four major turning points in the history of the Turing test - the publication of the article "Computing Machines and Mind" in 1950, a message about the creation of the ELIZA program (ELIZA) in 1966, the creation of the PARRY program by Kenneth Colby, which was first described in 1972 , and the Turing Colloquium in 1990.
The principle of Eliza’s work is to research user-entered comments for keywords. If a keyword is found, then the rule is applied, according to which the user's comment is converted and the result-sentence is returned. If the keyword is not found, Eliza either returns the general answer to the user, or repeats one of the previous comments. In addition, Weisenbaum programmed Eliza to imitate the behavior of a psychotherapist working in a client-centered manner. This allows Eliza to "pretend that she knows almost nothing about the real world." Using these methods, the Wisenbaum program could mislead some people who thought they were talking to a real person, and some were “very difficult to convince that Eliza [...] is not a person." On this basis, some argue that Eliza is one of the programs (possibly the first) that were able to pass the Turing test. However, this statement is very controversial, since the people “asking questions” were instructed so that they would think that a real psychotherapist would talk to them and did not suspect that they could talk to a computer.
Colby's work, PARRY, was described as “Eliza with opinions”: the program tried to simulate the behavior of a paranoid schizophrenic, using a similar (if not more advanced) approach from Wiesenbaum to Eliza. In order to test the program, PARRY was tested in the early 70s using a modification of the Turing test. A team of experienced psychiatrists analyzed a group made up of real patients and computers running PARRY using a teletype. Another team of 33 psychiatrists later showed transcripts of conversations. Then both teams were asked to determine which of the “patients” was a person and which one was a computer program. Psychiatrists were only 48% able to make the right decision. This figure is consistent with the probability of a random choice. These experiments were not Turing's tests in the full sense, since to make a decision, this test requires that questions be asked interactively, instead of reading the transcript of the last conversation.
Almost all developed programs didn’t come close to passing the test. Although programs such as Eliza ( ELIZA ) sometimes made people believe that they were talking to a person, such as in an informal experiment called AOLiza , these cases cannot be considered a correct Turing test for a number of reasons:
In 1980, in the article “Mind, Brain and Programs,” John Searle put forward an argument against the Turing test, known as the “China Room” thought experiment. Searle insisted that programs (such as Eliza) were able to pass the Turing test, simply by manipulating characters whose meaning they did not understand. And without understanding, they cannot be considered “reasonable” in the same sense as people. "Thus," concludes Searle, "the Turing test is not proof that the machine can think, and this is contrary to Turing's initial assumption."
Arguments such as those proposed by Sirlem, as well as others based on the philosophy of mind, gave rise to much more heated discussions about the nature of mind, the possibility of the existence of intelligent machines and the significance of the Turing test, which continued throughout the 80s and 90s.
In 1990, the fortieth anniversary of the publication of Turing's article “Computing Machines and Mind” took place, which renewed interest in the test. This year there were two important events.
One of them is the Turing Colloquium, which was held in April at the University of Sussex. Academicians and researchers from various fields of science met to discuss the Turing test from the standpoint of its past, present, and future. The second event was the establishment of the annual Löbner Prize competition.
The AI Loebner annual competition for the Löbner Prize is a platform for the practical implementation of Turing tests. The first competition was held in November 1991. The prize is guaranteed by Hugh Loebner. The Cambridge Center for the Study of Behavior, located in Massachusetts (USA), provided prizes until 2003 inclusive. According to Löbner, the competition was organized in order to move forward in research related to artificial intelligence, in part because "no one took measures to accomplish this."
Серебряная (текстовая) и золотая (аудио и зрительная) медали никогда ещё не вручались. Тем не менее, ежегодно из всех представленных на конкурс компьютерных систем судьи награждают бронзовой медалью ту, которая, по их мнению, продемонстрирует «наиболее человеческое» поведение в разговоре. Не так давно программа «Искусственное лингвистическое интернет-компьютерное существо» (Artificial Linguistic Internet Computer Entity — ALICE) трижды завоевала бронзовую медаль (в 2000, 2001 и 2004). Способная к обучению программа Jabberwacky (англ.) побеждала в 2005 и 2006. Её создатели предложили персонализированную версию: возможность пройти имитационный тест, пытаясь более точно сымитировать человека, с которым машина тесно пообщалась перед тестом.
Конкурс проверяет способность разговаривать; победителями становятся обычно чат-боты или «Искусственные разговорные существа» (Artificial Conversational Entities (ACE)s). Правилами первых конкурсов предусматривалось ограничение. Согласно этому ограничению каждая беседа с программой или скрытым человеком могла быть только на одну тему. Начиная с конкурса 1995 года это правило отменено. Продолжительность разговора между судьей и участником была различной в разные годы. В 2003 году, когда конкурс проходил в Университете Суррея, каждый судья мог разговаривать с каждым участником (машиной или человеком) ровно 5 минут. С 2004 по 2007 это время составляло уже более 20 минут. В 2008 максимальное время разговора составляло 5 минут на пару, потому что организатор Кевин Ворвик (Kevin Warwick) и координатор Хьюма Ша (Huma Shah) полагали, что ACE не имели технических возможностей поддерживать более продолжительную беседу. Как ни странно, победитель 2008 года, Elbot (англ.), не притворялся человеком, но всё-таки сумел обмануть трёх судей. В конкурсе проведенном в 2010 году, было увеличено время до 25 минут при общении между системой и исследователем, по требованию спонсора. Что только подтверждает, программы подросли в имитации человеку и только лишь при длительной беседе появляются минусы, позволяющие вычислять собеседника. А вот конкурс проведенный 15 мая 2012 года, состоялся впервые в мире с прямой трансляцией беседы, что только поднимает интерес к данному конкурсу.
Появление конкурса на получение премии Лёбнера привело к возобновлению дискуссий о целесообразности теста Тьюринга, о значении его прохождения. В статье «Искусственная тупость» газеты The Economist отмечается, что первая программа-победитель конкурса смогла выиграть отчасти потому, что она «имитировала человеческие опечатки». (Тьюринг предложил, чтобы программы добавляли ошибки в вывод, чтобы быть более хорошими «игроками».) Существовало мнение, что попытки пройти тест Тьюринга просто препятствуют более плодотворным исследованиям.
Во время первых конкурсов была выявлена вторая проблема: участие недостаточно компетентных судей, которые поддавались умело организованным манипуляциям, а не тому, что можно считать интеллектом.
Тем не менее, с 2004 года в качестве собеседников в конкурсе принимают участие философы, компьютерные специалисты и журналисты.
Стоит заметить, что полного диалога с машиной пока не существует. А то, что есть, больше напоминает общение в кругу друзей, когда отвечаешь на вопрос одного, а следом задаёт вопрос другой или как бы на твой вопрос отвечает кто-то совершенно посторонний. На этом и можно ловить машинную программу, если проверять её по тесту Тьюринга. Можно отметить, что судейство на конкурсе премии Лёбнера — очень забавное занятие, позволяющее с интересом скоротать время.
The judging of the competition is very strict. Experts are preparing for the tournament in advance and pick up very intricate questions in order to understand with whom they communicate. Their conversation with the programs resembles the interrogation of the investigator. Judges, for example, like to repeat some questions after a certain time, since weak bots do not know how to follow the dialogue history and can be caught in the same answers [2] .
In November 2005, a one-day meeting of ACE developers took place at the University of Surrey, which was attended by the winners of the Turing practical tests that were held as part of the Löbner Prize competition: Robby Garner, Richard Wallace, Rollo Carpenter. Guest speakers included David Hamill, Hugh Löbner and Hume Sha.
В 2008 году наряду с проведением очередного конкурса на получение премии Лёбнера, проходившего в Университете Рединга (University of Reading), Общество изучения искусственного интеллекта и моделирования поведения (The Society for the Study of Artificial Intelligence and Simulation of Behavior — AISB) провело однодневный симпозиум, на котором обсуждался тест Тьюринга. Симпозиум организовали Джон Бенден (John Barnden), Марк Бишоп (Mark Bishop), Хьюма Ша и Кевин Ворвик. В числе докладчиков были директор Королевского института баронесса Сьюзан Гринфилд (Susan Greenfield), Сельмер Брингсорд (Selmer Bringsjord), биограф Тьюринга Эндрю Ходжес (Andrew Hodges) и ученый Оуэн Холланд (Owen Holland). Никакого соглашения о каноническом тесте Тьюринга не появилось, однако Брингсорд предположил, что более крупная премия будет способствовать тому, что тест Тьюринга будет пройден быстрее.
В 2012 году отмечался юбилей Алана Тьюринга. На протяжении всего года проходило множество больших мероприятий. Многие из них проходили в местах, имевших большое значение в жизни Тьюринга: Кембридж, Манчестер и Блетчи Парк. Год Алана Тьюринга курируется организацией TCAC (Turing Centenary Advisory Committee), осуществляющей профессиональную и организационную поддержку мероприятий в 2012 году. Также поддержкой мероприятий занимаются: ACM, ASL, SSAISB,BCS, BCTCS, Блетчи Парк, BMC, BLC, CCS, Association CiE, EACSL, EATCS, FoLLI, IACAP, IACR, KGS и LICS.
Для организации мероприятий по празднованию в июне 2012 года столетия со дня рождения Тьюринга создан специальный комитет, задачей которого является донести мысль Тьюринга о разумной машине, отраженную в таких голливудских фильмах, как «Бегущий по лезвию», до широкой публики, включая детей. В работе комитета участвуют: Кевин Ворвик, председатель, Хьюма Ша, координатор, Ян Бланд (Ian Bland), Крис Чапмэн (Chris Chapman), Марк Аллен (Marc Allen), Рори Данлоуп (Rory Dunlop), победители конкурса на получение премии Лёбнера Робби Гарне и Фред Робертс (Fred Roberts). Комитет работает при поддержке организации «Женщины в технике» (Women in Technology) и Daden Ltd.
На этом конкурсе россияне, имена которых не разглашались, представили программу «Eugene» [3] . В 150 проведённых тестах (а по факту пятиминутных разговорах) участвовали пять новейших программ, которые «затерялись» среди 25 обычных людей. Программа «Eugene», изображавшая 13-летнего мальчика, проживающего вОдессе, стала победителем, сумев в 29,2 % своих ответов ввести экзаменаторов в заблуждение. Таким образом, программа не добрала всего 0,8 % для полного прохождения теста.
Существуют, по крайней мере, три основных варианта теста Тьюринга, два из которых были предложны в статье «Вычислительные машины и разум», а третий вариант, по терминологии Саула Трейджера (Saul Traiger), является стандартной интерпретацией.
Along with the fact that there is a certain discussion, whether the modern interpretation corresponds to what Turing described, or whether it is the result of a misinterpretation of his works, all three versions are not considered equivalent, their strengths and weaknesses differ.
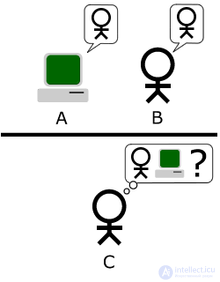
Turing, as we already know, described a simple party game that includes at least three players. Player A is a man, Player B is a woman and Player C, who plays as a conversation leader, of any gender. According to the rules of the game, C sees neither A nor B and can communicate with them only by means of written messages. By asking questions to players A and B, C is trying to determine which of them is a man and who is a woman. The task of player A is to confuse player C so that he makes a wrong conclusion. At the same time, the task of player B is to help player C to make a correct judgment.
In the version that SG Sterret calls the “Original Imitation Game Test” (Initial Imitation Game Test), Turing suggests that the role of Player A be played by a computer. Thus, the task of a computer is to pretend to be a woman in order to confuse player C. The success of such a task is estimated based on a comparison of the outcomes of the game, when player A is a computer, and outcomes when player A is a man:
|
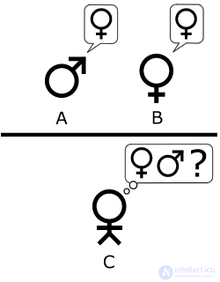
The second option is proposed by Turing in the same article. As in the "Initial Test", the role of Player A is performed by a computer. The difference lies in the fact that the role of player B can play both a man and a woman.
“Let's look at a specific computer. Is it true that modifying this computer to have enough space to store data, increasing its speed and setting it a suitable program, you can construct such a computer so that it satisfactorily performs the role of player A in a simulation game, while the role of player B does a man perform? ”, Turing, 1950, p. 442.
In this variant, both players A and B are trying to persuade the leader to the wrong decision.
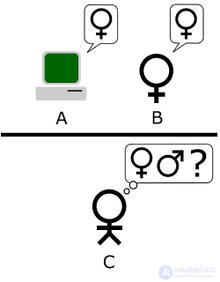
The main idea of this version is that the goal of the Turing test is to answer not to the question whether the machine can fool the leader, but to the question whether the machine can imitate a person or not. Although there are disputes over whether this option was implied by Turing or not, Sterret believes that this option was implied by Turing and, thus, combines the second option with the third. At the same time, a group of opponents, including Trader, does not think so. But it still led to what can be called the "standard interpretation." In this variant, player A is a computer, player B is a person of any gender. The task of the presenter is now not to determine which of them is a man and a woman, and who among them is a computer, and who is a man.
There is disagreement about which option Turing was referring to. Sterret insists that two different test versions follow from Turing's work, which, according to Turing, are not equivalent to each other. The test, which uses a party game and compares the success rate, is called the Initial Test based on a simulation game, while the test based on the judge’s conversation with the person and the machine is called the Standard Turing Test, noting that Sterret equates it to the standard interpretation. and not to the second version of the simulation game.
Sterret agrees that the Standard Turing Test (STT) has the flaws pointed out by his criticism. But he believes that, on the contrary, the initial test based on a simulation game (OIG Test - Original Imitation Game Test) is deprived of many of them due to key differences: unlike STT, he does not consider human-like behavior as the main criterion, although takes into account human behavior as a sign of rationality of the machine. A person may not pass the OIG test, in connection with which there is an opinion that this is the advantage of the test for the presence of intelligence. Failure to pass the test means the lack of resourcefulness: in the OIG test, by definition, it is considered that intelligence is associated with resourcefulness and is not simply “an imitation of a person’s behavior during a conversation”. In general, the OIG test can even be used in non-verbal terms.
However, other writers interpreted Turing's words as a suggestion to consider the simulation game itself as a test. And it does not explain how to relate this position and Turing's words that the test proposed by him on the basis of a game for parties is based on the criterion of comparative frequency of success in this simulation game, and not on the possibility of winning a round of a game.
In his works, Turing does not explain whether the judge knows that there will be a computer among the test participants or not. As for the OIG, Turing only says that Player A should be replaced by a car, but he is silent whether Player C knows it or not. When Kolby, F. D. Hilf (FD Hilf), A. D. Kramer (AD Kramer) tested PARRY, they decided that the judges did not have to know that one or several interlocutors would be computers. According to A. Saygin (A. Saygin), as well as other specialists, this leaves a significant imprint on the implementation and results of the test.
The strength of the Turing test is that you can talk about anything. Turing wrote that "the method of questions and answers seems suitable for discussing almost any of the spheres of human interests that we want to discuss." John Hogelend added that “understanding words alone is not enough; you also need to understand the topic of conversation. " To pass a well-established Turing test, the machine must use natural language, reason, have knowledge and learn. The test can be complicated by turning on the input with the help of video, or, for example, having equipped the gateway for the transfer of objects: the car will have to demonstrate its ability to see and robotics. All these tasks together reflect the main problems facing the theory of artificial intelligence.
The strength and appeal of Turing's test comes from its simplicity. The philosophers of consciousness, psychology in modern neuroscience are not able to define “intellect” and “thinking”, as far as they are sufficiently accurate and generally applicable to machines. Without such a definition, in the central questions of the philosophy of artificial intelligence there can be no answer. The Turing test, even if imperfect, at least ensures that it can really be measured. As such, it is a pragmatic solution to difficult philosophical questions.
It is worth noting that in Soviet psychology Vygotsky LS and Luria A.R. they gave quite clear definitions of “intellect” and “thinking” [4] .
Despite all its advantages and fame, the test is criticized on several grounds.
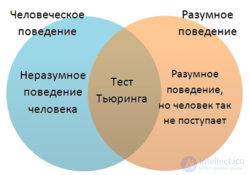
The orientation of the Turing test is pronounced in the direction of man (anthropomorphism). Only the ability of the machine to be like a person is checked, and not the intelligence of the machine at all. The test is unable to assess the overall intelligence of the machine for two reasons:
Stuart Russel and Peter Norvig argue that the anthropocentrism of the test leads to the fact that it cannot be truly useful in developing intelligent machines. “Tests on aviation design and construction,” they are building an analogy, “do not set as the goal of their industry the creation of machines that fly just like pigeons fly, that even pigeons themselves take them for their own” [5] . Because of this impracticality, passing the Turing test is not the goal of leading scientific or commercial research (as of 2009). Today's research in the field of artificial intelligence has set more modest and specific goals.
“Researchers in the field of artificial intelligence pay little attention to passing the Turing test,” noted Russell and Norvig, “since simpler ways of checking programs appeared, for example, giving a task directly, rather than in a roundabout way, be the first to identify some question in the chat room to which both cars and people are connected. ” Turing never intended to use his test in practice, in the daily measurement of the degree of reasonableness of programs; he wanted to give a clear and understandable example to support the discussion of the philosophy of artificial intelligence.
It should be emphasized that Turing did not disclose in a detailed form his goals and the idea of creating a test. Based on the conditions of passage, it can be assumed that in his time the human intellect dominated in all areas, that is, it was stronger and faster than any other. At the present time, some programs that imitate intellectual activity are so effective that they surpass the mind of the average inhabitant of the Earth in certain narrow areas. Therefore, under certain conditions they can pass the test.
Also, the Turing test is clearly behavioral or functionalistic: it only checks how the subject acts. A machine undergoing a test can imitate a person’s behavior in conversation, simply “non-intellectually” by following the mechanical rules. Two well-known counterexamples that express this viewpoint are the Chinese Room by Searle (1980) and the Blockhead by Ned Block (Ned Block, 1981). According to Searle, the main problem is to determine whether the machine “imitates” the thinking, or “actually” thinks. Even if the Turing test is suitable for determining the presence of intelligence, Searle notes that the test will not show that the machine has reason, consciousness, the ability to “understand” or have goals that have some meaning (philosophers call this goal-setting).
In his work, Turing wrote about these arguments about the following: “I don’t want to create the impression that I think that consciousness has no mystery. There is, for example, a kind of paradox associated with any attempt to locate it. But I do not think that these riddles must be solved before we can answer the question to which this work is devoted. ”
Turing predicted that cars would eventually be able to pass the test; in fact, he expected that by 2000, machines with a memory capacity of 10 9 bits (about 119.2 MiB or 125 MB) would be able to deceive 30% of judges according to the results of a five-minute test. He also suggested that the phrase "thinking machine" will no longer be considered an oxymoron. He further suggested that machine learning would be an important link in building powerful machines, which is plausible among modern researchers in the field of artificial intelligence [6] .
Extrapolating the exponential growth of technology for several decades, futurist Raymond Kurzweil suggested that machines capable of passing the Turing test will be made, according to rough estimates, around 2020. This echoes Moore's law.
The Long Bet Project includes a bet worth $ 20,000 between Mitch Kapoor (Mitch Kapor - pessimist) and Raymond Kurzweil (optimist). The meaning of betting: will the computer pass the Turing test by 2029? Certain betting conditions have also been determined [7] .
Numerous versions of the Turing test, including those described earlier, have been discussed for quite a while.
A modification of the Turing test, in which the target or one or more of the roles of the machine and the person is reversed, is called the reverse Turing test. An example of this test is given in the work of the psychoanalyst Wilfred Bion, who was particularly fascinated by how mental activity is activated when confronted with another mind.
Developing this idea, RD Hinshelwood (RD Hinshelwood) described the mind as an “apparatus that discriminates the mind”, noting that this can be considered as a “complement” to the Turing test. Now the task of the computer will be to determine with whom he spoke: with a person or with another computer. It was precisely this addition to the question that Turing tried to answer, but perhaps it introduces a high enough standard to determine whether a machine can “think” in the way we usually attribute this concept to a person.
CAPTCHA is a type of reverse turing test. Before allowing the execution of some action on the site, the user is given a distorted image with a set of numbers and letters and a suggestion to enter this set in a special field. The purpose of this operation is to prevent automatic attacks on the site. The rationale for such an operation is that while there are no programs powerful enough to recognize and accurately reproduce the text from a distorted image (or they are not available to ordinary users), it is considered that a system that could do this is highly likely to be human. . The conclusion will be (though not necessarily) that artificial intelligence has not yet been created.
This variation of the test is described as follows: the answer of the machine should not differ from the answer of an expert who is a specialist in a particular field of knowledge.
The immortality test is a variation of the Turing test, which determines whether the character of a person is qualitatively conveyed, namely, it is possible to distinguish the copied character from the character of the person who served as its source.
MIST is proposed by Chris McKinstry. In this variation of the Turing test, only two types of answers are allowed - “yes” and “no”. Usually MIST is used to collect statistical information, with which you can measure the performance of programs that implement artificial intelligence.
In this variation of the test, the subject (say, the computer) is considered reasonable if he has created something that he himself wants to test for rationality.
The organizers of the Hatter Prize believe that compressing a natural language text is a difficult task for artificial intelligence, equivalent to taking the Turing test.
The information compression test has certain advantages over most of the variations and variations of the Turing test:
The main disadvantages of this test are:
There are many tests on the level of intelligence that are used to test people. It is possible that they can be used to test artificial intelligence. Some tests (for example, C-test), derived from the "Kolmogorov complexity", are used to test people and computers.
Two teams of programmers managed to win the competition BotPrize, which is called the "gaming version" of the Turing test. The report on the test results is given on the BotPrize website, and its results are briefly analyzed by NewScientist. The BotPrize test took place in the form of a multiplayer computer game (Unreal Tournament 2004), whose characters were controlled by real people or computer algorithms [8] .
According to the University of Reading (English), Russian, in testing on June 6, 2014, organized by the School of Systems Engineering [9] at the University and RoboLaw companies under the guidance of Professor Kevin Warwick, a full-fledged Turing test was passed for the first time in the program “Eugene Goostman » [10] [11] , разработанной в Санкт-Петербурге выходцем из России Владимиром Веселовым и выходцем из Украины Евгением Демченко [12] . Всего в тестировании участвовали пятьсуперкомпьютеров. Испытание представляло собой серию пятиминутных письменных диалогов. Тест Тьюринга считался пройденным, если компьютеру удалось бы вводить собеседника (человека) в заблуждение на протяжении хотя бы 30 % суммарного времени. Программа Eugene c результатом 33 % и стала тем устройством, которое искусственным путём воссоздало человеческий интеллект — в данном случае, тринадцатилетнего подростка из Одессы, который «претендует на то, что знает всё на свете, но в силу своего возраста не знает ничего». Это вторая победа программы, однако в 2012 году на конкурсе в честь юбилея Алана Тьюринга (см. выше) она не добрала 0,8 % для полного прохождения теста.
Однако критики утверждают, что Женя Густман является лишь «чатботом»:
…Машина прикидывается всего лишь ребёнком, ну а полноценное прохождение теста Тьюринга невозможно ею в принципе. Ибо тест всего лишь бихевиористичен; на принципиальный вопрос — мыслит ли машина? — он ответа дать не может… Данные вопросы, конечно, могут обеспечить работой поколения философов-профессионалов, равно как и досугом — обширные круги философов-самоучек. Но вот с точки зрения инженерного дела или бизнеса они никакого смысла не имеют [13] .

Comments
To leave a comment
Models and research methods
Terms: Models and research methods