Lecture
The objectives and objectives of the course: the study of the main factors determining the reliability of the software, as well as the means and methods to ensure their quality and reliability.
1.1. Software quality
The quality of software (software) can be described by a large number of heterogeneous characteristics. It is necessary to take into account the totality of all characteristics that are important for all interested parties. The concept of software quality can be expressed in a structured system of characteristics. Such a system of characteristics is called a quality model.
In 1991, the software quality model defined by the international standard ISO 9126 was adopted as the standard. It assesses the quality of software based on a three-level review:
1. characteristics
2. subcharacteristics
3. metrics.
The ISO 9126 standard defines 6 characteristics of software quality:
1. functionality (functionality)
2. reliability
3. practicality or usability,
4. efficiency (efficiency)
5. maintainability
6. portability or portability.
Functionality is the ability of a software product to perform specified functions under certain conditions. Functionality is defined by the following sub-characteristics:
1. suitability for a particular job (suitability)
2. accuracy, correctness (accuracy),
3. interoperability,
4. security (security)
5. compliance with standards and rules (compliance).
Reliability is a property of a software product to maintain its working capacity (that is, to perform specified functions with parameters established by technical documentation) under specified conditions. Reliability is defined by the following sub-characteristics:
1. maturity, completeness (inverse to the failure rate) (maturity),
2. fault tolerance (fault tolerance)
3. the ability to recover from failures (recoverability),
4. compliance with reliability standards.
Practicality or applicability is the ability of a software product to be understandable, studied, applicable and attractive to the user in the given conditions. Practicality is determined by the following sub-characteristics:
1. understandability
2. ease of learning (learnability)
3. operability
4. attractiveness
5. Compliance with the standards of practicality (usability comp-liance).
Efficiency is a property of software that characterizes the conformity of resources used by a software product to the quality of performing its functions under specified conditions.
Subcharacteristics of effectiveness:
1. time characteristics (time behavior),
2. use of resources (resource utilization),
3. compliance with efficiency standards (efficiency comp-liance).
Maintenance is the property of a software product to be modified. Maintenance is determined by the following subcharacteristics:
1. analyzability
2. variability, convenience of making changes (change-ability),
3. the risk of unexpected effects when making changes or stability (stability),
4. testability, testability,
5. compliance with maintainability standards (maintaina-bility compliance).
Portability - the ability of a software product to be portable from one medium to another. Portability is defined by the following sub-characteristics:
1. adaptability (adaptability)
2. installability, ease of installation (installability),
3. ability to coexist with other software (coexistence),
4. the convenience of replacing other software data (replaceability)
5. compliance with portability standards.
Adopted in 2001, parts 2 and 3 of ISO 9126 define a set of software quality metrics. As an example of such metrics we give the following:
1. The completeness of the functions. Used to measure fitness.
2. The correctness of the implementation of functions. Used to measure fitness.
3. The ratio of the number of detected defects to the predicted. Used to determine maturity.
4. The ratio of the number of tests performed to their total number. Used to determine maturity.
5. The ratio of the number of available project documents to the specified in their list. Used to measure analyzability.
Note that the third and fourth metrics show that the quality of software depends not only on the software itself as an object of the material world, but also on its perception by stakeholders: developers, users, customers, etc. Indeed, without changing the software itself, you can improve its quality only through some tests not yet conducted, since the value of the fourth metric will increase.
1.2. The main ways to certify the quality and reliability of software
Software verification, validation and certification processes serve to certify and validate their quality and reliability.
Verification is the process of determining whether a software tool is developed in accordance with all requirements for it, or that the results of the next development stage comply with the constraints formulated in previous steps.
Verification is an integral part of the work in the collective development of the PS. At the same time, verification tasks include monitoring the results of some developers when transferring them as source data to other developers.
Validation is a check that the software itself is correct, i.e. confirmation that it truly meets the needs and expectations of users, customers and other interested parties.
According to the standard IEEE 1012-1986, verification is the process of evaluating a system or component in order to determine whether a certain phase results satisfy the conditions imposed at the beginning of this phase. Validation in the same standard is defined as the process of evaluating a system or component during or at the end of the development process in order to determine whether it meets the specified requirements.
The international standard ISO / IEEE 0002 defines conformity certification as a 3rd party action, proving that it provides the necessary assurance that a product, process or service conforms to a particular standard or other regulatory document.
In the process of determining the reliability of the PS, the following concepts are used:
Failure is an event that consists in the termination of the execution of the required functions by the software with the given restrictions. The cause of failure, as a rule, is the manifestation of defects that remain undetected.
A defect is a software anomaly, an incorrect definition of an operation, process, data in a program or software specification.
A fault is a condition in which the program is unable to perform the required functions. A fault condition occurs after a fault occurs.
Error is the action of a person, as a result of which a defect is introduced into the software.
Measurement is the process of determining the quantitative or qualitatively the values of the attributes of the subject property.
The indicator is the absolute value of the attributes of a program or a development process, that is, a quantitative assessment of the extent to which the PS or process has a given property.
A metric is a qualitative or quantitative characteristic of a software or its development process. When determining metrics, the scale and method of measurement play an important role. Metrics allow you to assess the level of quality and reliability of software products and processes and to identify existing problems.
1.3. Software Reliability Theory
The uneven distribution and instability of the appearance of errors when using complex software systems does not allow to calculate their reliability by classical methods of the theory of reliability of technical systems. The performance of complex programs in real time is the subject of study of the theory of software reliability. Its main tasks are:
1. The formulation of the basic concepts used in the study and application of indicators of the reliability of software.
2. Identification and study of the main factors determining the reliability characteristics of complex PS.
3. Selection and justification of the reliability criteria for software packages of various types and purposes.
4. Investigation of defects and errors, as well as the dynamics of their changes during debugging and maintenance.
5. Research and development of methods for the structural construction of complex PS, providing them with the necessary reliability.
6. The study of methods and means of control and protection against distortion of programs, the computational process and data through the use of various types of redundancy.
7. Development of methods and means for determining and predicting the reliability characteristics in the life cycle of program complexes, taking into account their functional purpose, complexity and development technology.
The results of solving these problems are the basis for the creation of modern complex PS with specified reliability parameters.
Software reliability analysis is based on the interaction model of the following components:
objects of vulnerability
destabilizing factors and threats to reliability,
methods to prevent threats to reliability
methods to improve reliability.
The model of interaction between these components is presented in Figure 1.1.
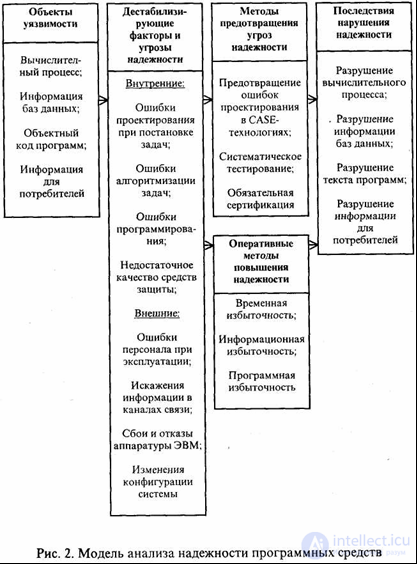
Figure 1.1 - Software Reliability Analysis Model
Objects of vulnerability that affect the reliability of the PS are:
dynamic computing data processing;
information accumulated in databases;
object code of programs executed by computational means in the course of PS operation;
information issued to consumers.
Objects of vulnerability are affected by various destabilizing factors , which are divided into internal and external.
Internal sources of threats to the reliability of complex software tools are inherent in the objects of vulnerability. They are:
system errors when setting goals and objectives for creating a PS, when formulating requirements for functions and characteristics of problem solving, defining conditions and parameters of the external environment in which PS is to be applied;
algorithmic development errors in the direct specification of software functions, in determining the structure and interaction of components of program complexes, as well as in using database information;
programming errors in the texts of the programs and data descriptions, as well as in the source and resulting documentation for the components and the PS as a whole;
the lack of effectiveness of the methods and means of operational protection of programs and data from failures and failures and ensuring the reliability of the PS in conditions of accidental negative impacts.
External destabilizing factors are due to the environment in which the objects of vulnerability operate. They are:
personnel errors during operation;
distortion of information in communication channels;
equipment failures and failures;
reconfiguration of information systems equipment.
In practice, it is impossible to completely eliminate destabilizing factors; therefore, it is necessary to develop means and methods for reducing their influence on PS reliability.
In modern automated technologies for creating complex PS from the standpoint of providing them with the necessary and given reliability, it is possible to distinguish methods and means allowing:
- create software modules and functional components of high, guaranteed quality;
- prevent design defects due to efficient technologies and automation tools to ensure the entire life cycle of program complexes and databases;
- detect and eliminate various defects and errors in the design, development and maintenance of programs through systematic testing at all stages of the PS life cycle;
- certify the achieved quality and reliability of the PS in the process of their testing and certification before being transferred to regular operation;
- promptly identify the consequences of program and data defects and restore normal, reliable functioning of the program complexes.
External destabilizing factors have a different nature. Modern achievements of microelectronics have significantly reduced the impact of failures and failures of computational tools on the reliability of software operation. However, personnel errors, data distortions in telecommunications channels, as well as occasional (in case of failure of a part of equipment) and necessary changes in the configuration of computing facilities remain significant external threats to the reliability of software. The negative impact of these factors can be significantly reduced by appropriate methods and means of protecting and restoring programs and data.
The degree of influence of all internal destabilizing factors and some external threats to the reliability of PS is determined to the greatest extent by the quality of design technologies, development, maintenance and documentation of PS and their main components. With limited resources for developing software to achieve specified reliability requirements, quality assurance management is needed during the entire cycle of creating programs and data.
To detect and eliminate design errors, all stages of software development and maintenance should be supported by systematic testing methods and tools. Testing is the main method of measuring quality, determining the correctness and real reliability of the programs at each stage of development. Test results should be compared with the requirements of the specification or specification.
In addition, quality assurance of software systems involves the formalization and certification of technology for their development, as well as the allocation to a special process of step-by-step measurement and analysis of the current quality of the components created and applied.
So, the main methods of preventing threats to reliability:
prevention of design errors in CASE technologies;
systematic testing;
mandatory certification
The combined use of these methods can significantly reduce the impact of threats. Thus, the level of reliability achieved depends on the resources allocated to its achievement and on the quality of the technologies used at all stages of the software life cycle.
In order to ensure high reliability of the PS operation, computational resources are required for the fastest detection of the manifestation of defects and the implementation of automatic measures that ensure the rapid restoration of normal PS operation. For these purposes, the following operational methods of improving reliability are used:
temporary redundancy
information redundancy
software redundancy.
Temporary redundancy consists in using some part of the computer's performance to control the execution of programs and restore the computational process. To this end, when designing an information system, a performance margin should be provided for, which will then be used to monitor and quickly increase the reliability of operation. The magnitude of the temporal redundancy depends on the requirements for reliability and ranges from 5-10% of computer performance to 3-4 times the duplication of individual machine performance in multiprocessor computing systems. Temporal redundancy is used to monitor and detect distortions, to diagnose them and make decisions to restore the computational process or information, as well as to implement recovery operations.
Information redundancy is the duplication of the accumulated source and intermediate data processed by programs. Redundancy is used to preserve the reliability of the data that most affect the normal functioning of the PS and take considerable time to recover. They are protected by a 2-3 fold duplication with periodic updates.
Software redundancy is used to control and ensure the reliability of the most important information processing solutions. It consists in comparing the results of processing the same source data by programs that differ in the algorithms used, and in eliminating distortion when the results do not match. Software redundancy is also necessary for the implementation of automatic control and data recovery programs using information redundancy and for the operation of all reliability tools using temporary redundancy.
The means of operational program control are turned on after using application and service programs, therefore program control tools usually cannot directly detect the cause of the distortion of the computational process or data and only fixes the consequences of the primary distortion, i.e. secondary error. The results of primary distortion can become catastrophic in the event of delay in their detection and localization. To ensure reliability, defects must be detected with minimal delay, while minimal hardware resources are desirable, therefore hierarchical control schemes are used, in which several methods are used consistently to increase control and increase costs until the source of distortion is detected. Целесообразно акцентировать ресурсы на потенциально наиболее опасных дефектах и достаточно частых режимов восстановления: при искажениях программ и данных, при перегрузках по производительности и при параллельном использовании программ.
При тестировании и отладке обычно сначала обнаруживаются вторичные ошибки, т. е. результаты проявления исходных дефектов, которые являются первичными ошибками. Локализация и корректировка таких первичных ошибок приводит к устранению ошибок, первоначально обнаруживаемых в результатах функционирования программ.
Проявление дефектов и ошибок в разной степени влияет на работоспособность программ. По величине ущерба проявление вторичных ошибок делятся на 3 группы:
сбои, которые не отражаются на работоспособности программ, ущербом от которым можно пренебречь,
ordinary failures, the damage from which is in some acceptable limits,
catastrophic failures, the damage from which is so great that it determines the safety of the application of this PS.
Characteristics and specific implementations of primary errors do not allow one to unambiguously predict the types and degree of manifestation of secondary errors. In practice, the simplest errors of programs and data can lead to disastrous consequences.At the same time, system defects can only slightly degrade performance and do not affect the safety of the PS. Error statistics in software packages and their characteristics can serve as a guide for developers in distributing debugging efforts. However, the registration, collection and analysis of the characteristics of errors in programs is a complex and time-consuming process. In addition, software developers do not advertise their mistakes. All this prevents the receipt of objective error data.
Первичные ошибки в порядке усложнения их обнаружения можно разделить на следующие виды:
технологические ошибки подготовки данных и документации,
программные ошибки из-за неправильной записи текста программ на языке программирования и ошибок трансляции программы в объектный код,
алгоритмические ошибки, связанные с неполным формулированием необходимых условий решения и некорректной постановкой задач,
системные ошибки, обусловленные отклонением функционирования ПС в реальной системе и отклонением характеристик внешних объектов от предполагаемых при проектировании.
Перечисленные ошибки различаются по частоте и методам их обнаружения на разных этапах проектирования. При автономной и в начале комплексной отладки доля системных ошибок составляет около 10%. На завершающих этапах комплексной отладки она возрастает до 35-40%. В процессе сопровождения системные ошибки являются преобладающими и составляют около 80% от всех ошибок. Частота появления вторичных ошибок при функционировании программ и частота их обнаружения при отладке зависит от общего количества первичных ошибок в программе. Наиболее доступно для измерения число вторичных ошибок в программе, выявленных в единицу времени в процессе тестирования. Возможна также регистрация отказов и искажение результатов при эксплуатировании программ.
Путем анализа и обобщения экспериментальных данных в реальных разработках было предложено несколько математических моделей, описывающих основные закономерности изменения суммарного количества вторичных ошибок в программах.
Модели имеют вероятностный характер, и достоверность прогнозов в значительной степени зависит от точности исходных данных. Модели дают удовлетворительные результаты при относительно высоких уровнях интенсивности проявления ошибок, т.е. при невысокой надежности ПС. В этих условиях математические модели предназначены для приближенной оценки:
потенциально возможной надежности функционирования программ в процессе испытаний и эксплуатации;
числа ошибок, оставшихся не выявленными в анализируемых программах;
времени тестирования, требующегося для обнаружения следующей ошибки в функционирующей программе;
времени, необходимого для выявления всех имеющихся ошибок с заданной вероятностью.
Построение математических моделей базируются на предположении о жесткой связи между следующими тремя параметрами:
суммарным количеством первичных ошибок в программе,
числом ошибок, выявленных в единицу времени в процессе тестирования и отладки,
интенсивностью искажения результатов в единицу времени на выходе комплекса программ при нормальном его функционировании из-за невыявленных первичных ошибок.
Предполагается, что все три показателя связаны коэффициентом пропорциональности (рис.1.2).
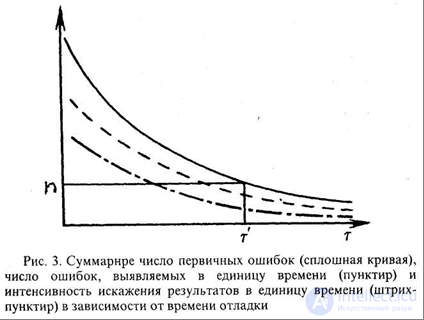
Рисунок 1.2 – Суммарное число первичных ошибок (сплошная кривая), число ошибок, выявляемых в единицу времени (пунктир), интенсивность искажения результатов в единицу времени (штрих-пунктир) в зависимости от времени отладки
В настоящее время описаны несколько математических моделей, основой которых являются различные гипотезы о характере проявления вторичных ошибок в программах. Экспоненциальная математическая модель распределения ошибок в программах основана на следующих предположениях:
Интервалы времени между обнаруживаемыми искажениями результатов предполагаются статистически независимыми.
Интенсивность проявления ошибок остается постоянной пока не произведено исправление первичной ошибки или не изменена программа по другой причине. Если каждая обнаруженная ошибка исправляется, то значения интервалов времени между их проявлениями изменяются по экспоненциальному закону.
Интенсивность обнаружения вторичных ошибок пропорциональна суммарному числу первичных ошибок, имеющихся в данный момент в комплексе программ.
Приведенные предположения позволяют построить экспоненциальную математическую модель распределения ошибок в программах и установить связь между интенсивностью обнаружения ошибок при отладке dn/dt, интенсивностью проявления ошибок при нормальном функционировании комплекса программ l и числом первичных ошибок . Предположим, что в начале отладки комплекса программ при t=0 в нем содержалось N первичных ошибок. После отладки в течение времени t осталось п о первичных ошибок и устранено п ошибок ( n 0 +n = N ). При этом время t соответствует длительности исполнения программ на компьютере для обнаружения ошибок и не учитывает время, необходимое для анализа результатов и проведения корректировок. Календарное время отладочных и испытательных работ с реальным комплексом программ больше, так как после тестирования программ, на которое затрачивается машинное время t , необходимо время на анализ результатов, на обнаружение и локализацию ошибок, а также на их устранение. Однако для определения характеристик проявления ошибок играет роль только длительность непосредственного функционирования программ на компьютере.
При постоянных усилиях на тестирование и отладку интенсивность обнаружения искажений вычислительного процесса, программ или данных вследствие еще невыявленных ошибок пропорциональна количеству оставшихся первичных ошибок в комплексе программ. Как уже отмечалось, предположение о сильной корреляции между значениями n и dn/dt достаточно естественно и проверено анализом реальных характеристик процесса обнаружения ошибок. Then
dn/dt=K1k=Kn0=K(N0-n) , (1.1)
где коэффициенты К и К 1 учитывают: масштаб времени, используемого для описания процесса обнаружения ошибок, быстродействие компьютера, распределение тестовых значений на входе проверяемого комплекса и другие параметры. Значение коэффициента К можно определить как изменение темпа проявления искажений при переходе от функционирования программ на специальных тестах к функционированию на нормальных типовых исходных данных. В начале отладки это различие может быть значительным, однако, при завершении отладки и при испытаниях тестовые данные практически совпадают с исходными данными нормальной эксплуатации. Поэтому ниже К 1 полагается равным единице ( К 1 =1 ). Таким образом, интенсивность обнаружения ошибок в программе и абсолютное число устраненных первичных ошибок связываются уравнением:
dn/dt + Kn = KN0 (1.2)
Так как выше предполагалось, что в начале отладки при t =0 отсутствуют обнаруженные ошибки, то решение уравнения (2) имеет вид:
n=N0 [1-exp(-Kt)] . (1.3)
Число оставшихся первичных ошибок в комплексе программ
n0 = N0 exp(-Kt) (1.4)
пропорционально интенсивности обнаружения dn/dt с точностью до коэффициента К.
Наработка между проявлениями ошибок, которые рассматриваются как обнаруживаемые искажения программ, данных или вычислительного процесса, равна величине, обратной интенсивности обнаружения ошибок
T = 1 / (dndt) = 1/KN0 * exp (Kt) (1.5)
Следует подчеркнуть статистический характер приведенных соотношений. Дальнейшая детализация модели описания характеристик программных ошибок связана с уточнением содержания и значения коэффициента пропорциональности К и с учетом затрат на отладку. При исследовании ошибок в программах различными авторами был сформулирован ряд уточнений и допущений, отличных от приведенных выше. Эти допущения, а также специфические методы построения послужили основой создания нескольких более сложных математических моделей, отличающихся от простейшей экспоненциальной. Однако ни одна из этих моделей не имеет явных преимуществ по точности аппроксимации распределений и прогнозирования числа программных ошибок по сравнению с простейшей экспоненциальной моделью.

Comments
To leave a comment
Software reliability
Terms: Software reliability