Lecture
All routing information exchange protocols of the TCP / IP stack belong to the class of adaptive protocols, which in turn are divided into two groups, each of which is associated with one of the following types of algorithms:
In distance-vector type algorithms, each router periodically and broadcasts the distance vector from itself to all networks known to it. Distance is usually understood as the number of intermediate routers through which a packet must pass before it enters the corresponding network. Another metric can be used, taking into account not only the number of transshipment points, but also the transit time of packets through the connection between neighboring routers. Having received a vector from a neighboring router, each router adds to it information about other networks that it knows about, which it learned about directly (if they are connected to its ports) or from similar announcements of other routers, and then sends the new value of the vector again over the network. In the end, each router learns information about the networks available in the Internet and about the distance to them through neighboring routers.
Remote vector algorithms work well only in small networks. In large networks, they clog the communication lines with intense broadcast traffic, and configuration changes may not be worked out correctly using this algorithm, since routers do not have an accurate idea of the network connection topology, and have only generalized information — the distance vector, received through intermediaries. The operation of the router in accordance with the distance vector protocol resembles the operation of the bridge, since such a router does not have an accurate topological picture of the network.
The most common protocol based on distance vector algorithm is RIP.
Link state algorithms provide each router with enough information to build an accurate network link graph. All routers operate on the basis of identical graphs, which makes the routing process more resilient to configuration changes. Broadcasting is used here only when link state changes, which happens in reliable networks less frequently.
In order to understand the state of the communication lines connected to its ports, the router periodically exchanges short packets with its nearest neighbors. This traffic is also broadcast, but it only circulates between neighbors and therefore does not clog the network so much.
The protocol based on the link state algorithm in the TCP / IP stack is OSPF.
Routing (Routing Information Protocol) is one of the oldest routing information exchange protocols, but it is still extremely common in computer networks. In addition to the RIP version for TCP / IP networks, there is also a RIP version for Novell IPX / SPX networks.
In this protocol, all networks have numbers (the method of generating the number depends on the network layer protocol used in the network), and all routers are identifiers. The RIP protocol widely uses the concept of "distance vector". The distance vector is a set of pairs of numbers that are numbers of networks and distances to them in hops.
Distance vectors are iteratively distributed by routers over the network, and after several steps each router has information about the networks reachable by it and about the distances to them. If the connection with any network is terminated, the router notes this fact by assigning to the vector element corresponding to the distance to this network the maximum possible value that has a special meaning - “no connection”. This value in the RIP protocol is the number 16.
Figure 8.1 shows an example of a network consisting of six routers having identifiers from 1 to 6 and of six networks from A to F formed by direct point-to-point connections.
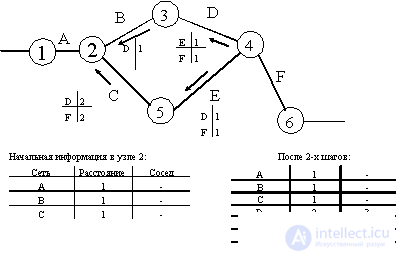
Fig. 8.1. RIP routing information exchange
The figure shows the initial information contained in the topological database of router 2, as well as information in the same database after two iterations of the exchange of routing packets of the RIP protocol. After a certain number of iterations, router 2 will be aware of the distances to all the networks of the internetwork, and it may have several alternatives for sending a packet to the destination network. In our example, suppose that the destination network is D.
If you need to send a packet to network D, the router looks at its route database and selects the port that has the shortest distance to the destination network (in this case, the port that connects it to router 3).
A timer is associated with each entry in the routing table to adapt to changes in the state of communications and equipment. If, during the timeout, a new message does not arrive confirming this route, it will be deleted from the routing table.
When using the RIP protocol, the heuristic Bellman-Ford dynamic programming algorithm works, and the solution found with its help is not optimal, but close to optimal. The advantage of the RIP protocol is its computational simplicity, and the disadvantages are the increase in traffic during the periodic broadcasting of broadcast packets and the nonoptimality of the route found.
Figure 8.2 shows the case of unstable network operation under the RIP protocol when the configuration changes — failure of the communication link of router M1 with network 1. When this connection is operational, there is an entry in the routing table of each router with network number 1 and the corresponding distance to it.
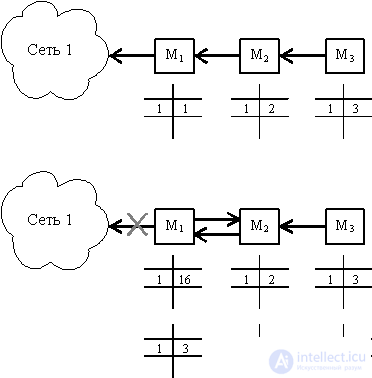
Fig. 8.2. An example of unstable network operation using RIP
When the connection with network 1 is broken, router M1 notes that the distance to this network has assumed the value 16. However, after receiving a routing message from router M2 after a while that the distance from network 1 to the network is 2 hops, router M1 increases this distance by 1 and notes that network 1 is reachable through router 2. As a result, a packet destined for network 1 will circulate between routers M1 and M2 until the storage time of the network record 1 in router 2 has expired and it does not transmit this information mar Schrutizator M1.
In order to avoid such situations, routing information about the network known to the router is not transmitted to the router from which it came.
There are other, more complex cases of unstable behavior of networks using the RIP protocol, with changes in the state of communications or routers of the network.
Most routing protocols used in modern packet-switched networks originate from the Internet and its predecessor, ARPANET. In order to understand their purpose and features, it is useful to first get acquainted with the structure of the Internet, which left an imprint on the terminology and types of protocols.
The Internet was originally built as a network uniting a large number of existing systems. From the very beginning, its structure was distinguished backbone network ( core backbone network ) , and networks connected to the backbone were considered autonomous systems (autonomous systems). The backbone network and each of the autonomous systems had their own administrative control and their own routing protocols. The general scheme of the architecture of the Internet network is shown in Figure 8.3 . Next, routers will be called gateways to follow traditional Internet terminology.
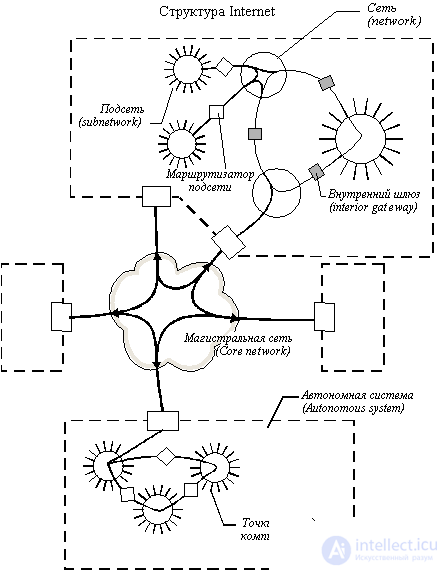
Fig. 8.3. Internet architecture
Gateways that are used to form subnets within an autonomous system are called interior gateways , and gateways through which autonomous systems connect to the network backbone are called exterior gateways . Directly with each other autonomous systems do not connect. Accordingly, the routing protocols used within autonomous systems are called internal gateway protocols ( interior gateway protocol, IGP ), and the protocols defining the exchange of route information between external gateways and backbone gateways - protocols of external gateways ( exterior gateway protocol, EGP ). Inside the backbone network, any of its own internal IGP protocol can also be used.
The meaning of the division of the entire Internet network into autonomous systems in its multi-level representation, which is necessary for any large system capable of expanding on a large scale. Internal gateways can use sufficiently detailed graphs of connections between themselves for internal routing in order to choose the most efficient route. However, if information of such a degree of detail will be stored in all routers of the network, the topological databases will grow so much that they will require memory of enormous size, and the time for making routing decisions will certainly increase.
Therefore, detailed topological information remains inside the autonomous system, and the autonomous system as a whole for the rest of the Internet is represented by external gateways that report the internal composition of the autonomous system with the minimum necessary information - the number of IP networks, their addresses and the internal distance to these networks from this external network. gateway.
During initialization, the external gateway recognizes the unique identifier of the autonomous system it serves, as well as the reachability table , which allows it to interact with other external gateways through the backbone network.
Then the external gateway begins to communicate via the EGP protocol with other external gateways and exchange route information with them, the composition of which is described above. As a result, when sending a packet from one autonomous system to another, the external gateway of this system, based on the routing information received from all external gateways with which it communicates via the EGP protocol, selects the most suitable external gateway and sends it a packet.
The EGP protocol defines three main functions:
Each function is based on the request-response messaging.
Since each autonomous system operates under the control of its administrative state, before the exchange of route information begins, external gateways must agree to such an exchange. First, one of the gateways sends a request for the establishment of neighbors (acquisition request) to another gateway. If he agrees to this, he responds with a message confirming the establishment of neighbor relations (acquisition confirm) , and if not, then he replies with a message that he does not establish neighbors relations (acquisition refuse) which also contains the reason for the refusal.
After establishing neighborly relations, the gateways begin to periodically check the state of reachability of each other. This is done either by using special messages ( hello (hello) and I-heard-you (I-heard-you) ) , or by embedding confirmation information directly into the header of a regular routing message.
The exchange of routing information begins with one of the gateways sending another data request message . (poll request) about the numbers of networks served by another gateway and distances to them from it. The response to this message is the updated route information. (routing update). If the request is incorrect, then an error message is sent to it.
All EGP messages are transmitted in the IP packet data field. EGP messages have a fixed format header (Figure 8.4).
The Type and Code fields together define the type of message, and the Status field - information depending on the type of message. The Autonomous System Number field is the number assigned to the autonomous system to which this external gateway is connected. The Sequence Number field is used to synchronize the request and response process.
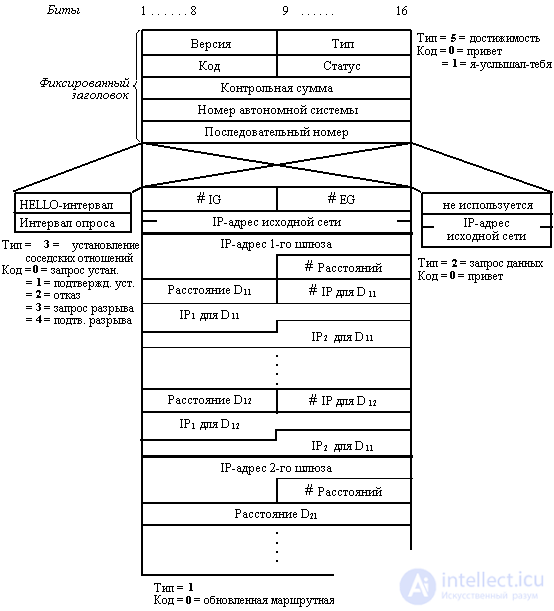
Fig. 8.4. EGP message format
The source network IP address in the request and update route information messages indicates the network connecting two external gateways (Figure 8.5).
The updated route information message contains a list of network addresses that are reachable on this autonomous system. This list is ordered by internal gateways that are connected to the source network and through which the network data is reachable, and for each gateway it is ordered by distance from each source network from the source network , and not from this internal gateway . For the example shown in Figure 8.5, external gateway R2 in its message indicates that network 4 is reachable using gateway R3 and its distance is 2, and network 2 is reachable through gateway R2 and its distance is 1 (and not 0, as if the gateway measured its distance from itself, as in the RIP protocol).
The EGP protocol has a lot of limitations due to the fact that it considers the backbone network as one indivisible backbone.
The development of the EGP protocol is the BGP (Border Gateway Protocol) protocol, which has much in common with the EGP and is used along with it in the Internet backbone.
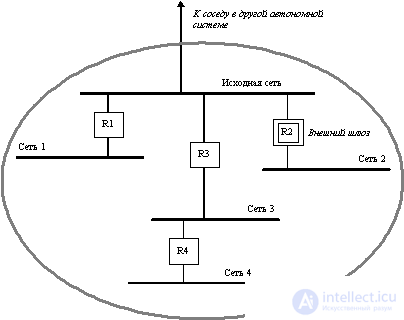
Fig. 8.5. Autonomous System Example
The OSPF (Open Shortest Path Firs) protocol is a fairly modern implementation of the link-state algorithm (it was adopted in 1991) and has many features that are oriented to use in large heterogeneous networks.
The OSPF protocol computes routes in IP networks while retaining other routing information exchange protocols.
Directly connected (that is, reachable without using intermediate routers) routers are called "neighbors." Each router stores information about the state in which it sees its neighbor. The router relies on neighboring routers and sends them data packets only if it is certain that they are fully operational. To determine the state of connections, the neighboring routers often exchange short messages HELLO.
Routers exchange messages of a different type to distribute link state data over the network. These messages are called router links advertisement - the announcement of the router's connections (more precisely, the state of the connections). OSPF routers exchange not only their own, but also other people's messages about connections, eventually receiving information on the status of all network connections. This information forms the network connection graph, which, naturally, is the same for all network routers.
In addition to information about the neighbors, the router in its ad lists the IP subnets with which it is directly connected, therefore, after receiving information about the network connection graph, the route to each network is calculated directly using this graph using the Daystra algorithm. More precisely, the router calculates the path not to a specific network, but to the router to which this network is connected. Each router has a unique identifier, which is transmitted in a link state advertisement. This approach makes it possible not to waste IP addresses on point-to-point communications between routers to which workstations are not connected.
The router calculates the optimal route to each addressable network, but remembers only the first intermediate router from each route. Thus, the result of the calculation of optimal routes is a list of lines that indicate the network number and the identifier of the router to which you want to forward a packet for this network. The specified route list is a routing table, but it is calculated on the basis of complete information about the network connection graph, and not partial information, as in the RIP protocol.
The described approach leads to a result that cannot be achieved using RIP or other distance-vector algorithms. RIP assumes that all subnets of a specific IP network are the same size, that is, that they can all potentially have the same number of IP nodes whose addresses do not overlap. Moreover, the classic implementation of RIP requires that point-to-point dedicated lines have an IP address, which results in additional IP address costs.
There are no such requirements in OSPF: networks may have a different number of hosts and may overlap. Overlap means having multiple routes to the same network. In this case, the network address in the incoming packet may coincide with the network address assigned to several ports.
If the address belongs to several subnets in the route database, then the packet-forwarding router uses the most specific route, that is, the address of the subnet that has a longer mask.
For example, if a workgroup branches off from the main network, then it has the address of the main network along with the more specific address defined by the subnet mask. При выборе маршрута к хосту в подсети этой рабочей группы маршрутизатор найдет два пути, один для главной сети и один для рабочей группы. Так как последний более специфичен, то он и будет выбран. Этот механизм является обобщением понятия "маршрут по умолчанию", используемого во многих сетях.
Использование подсетей с различным количеством хостов является вполне естественным. Например, если в здании или кампусе на каждом этаже имеются локальные сети, и на некоторых этажах компьютеров больше, чем на других, то администратор может выбрать размеры подсетей, отражающие ожидаемые требования каждого этажа, а не соответствующие размеру наибольшей подсети.
В протоколе OSPF подсети делятся на три категории:
Транзитная сеть является для протокола OSPF особым случаем. В транзитной сети несколько маршрутизаторов являются взаимно и одновременно достижимыми. В широковещательных локальных сетях, таких как Ethernet или Token Ring, маршрутизатор может послать одно сообщение, которое получат все его соседи. Это уменьшает нагрузку на маршрутизатор, когда он посылает сообщения для определения существования связи или обновленные объявления о соседях. Однако, если каждый маршрутизатор будет перечислять всех своих соседей в своих объявлениях о соседях, то объявления займут много места в памяти маршрутизатора. При определении пути по адресам транзитной подсети может обнаружиться много избыточных маршрутов к различным маршрутизаторам. На вычисление, проверку и отбраковку этих маршрутов уйдет много времени.
Когда маршрутизатор начинает работать в первый раз (то есть инсталлируется), он пытается синхронизировать свою базу данных со всеми маршрутизаторами транзитной локальной сети, которые по определению имеют идентичные базы данных. Для упрощения и оптимизации этого процесса в протоколе OSPF используется понятие "выделенного" маршрутизатора, который выполняет две функции.
Во-первых, выделенный маршрутизатор и его резервный "напарник" являются единственными маршрутизаторами, с которыми новый маршрутизатор будет синхронизировать свою базу. Синхронизировав базу с выделенным маршрутизатором, новый маршрутизатор будет синхронизирован со всеми маршрутизаторами данной локальной сети.
Во-вторых, выделенный маршрутизатор делает объявление о сетевых связях, перечисляя своих соседей по подсети. Другие маршрутизаторы просто объявляют о своей связи с выделенным маршрутизатором. Это делает объявления о связях (которых много) более краткими, размером с объявление о связях отдельной сети.
Для начала работы маршрутизатора OSPF нужен минимум информации - IP-конфигурация (IP-адреса и маски подсетей), некоторая информация по умолчанию (default) и команда на включение. Для многих сетей информация по умолчанию весьма похожа. В то же время протокол OSPF предусматривает высокую степень программируемости.
Интерфейс OSPF (порт маршрутизатора, поддерживающего протокол OSPF) является обобщением подсети IP. Подобно подсети IP, интерфейс OSPF имеет IP-адрес и маску подсети. Если один порт OSPF поддерживает более, чем одну подсеть, протокол OSPF рассматривает эти подсети так, как если бы они были на разных физических интерфейсах, и вычисляет маршруты соответственно.
Интерфейсы, к которым подключены локальные сети, называются широковещательными (broadcast) интерфейсами, так как они могут использовать широковещательные возможности локальных сетей для обмена сигнальной информацией между маршрутизаторами. Интерфейсы, к которым подключены глобальные сети, не поддерживающие широковещание, но обеспечивающие доступ ко многим узлам через одну точку входа, например сети Х.25 или frame relay, называются нешироковещательными интерфейсами с множественным доступом или NBMA (non-broadcast multi-access). Они рассматриваются аналогично широковещательным интерфейсам за исключением того, что широковещательная рассылка эмулируется путем посылки сообщения каждому соседу. Так как обнаружение соседей не является автоматическим, как в широковещательных сетях, NBMA-соседи должны задаваться при конфигурировании вручную. Как на широковещательных, так и на NBMA-интерфейсах могут быть заданы приоритеты маршрутизаторов для того, чтобы они могли выбрать выделенный маршрутизатор.
Интерфейсы "точка-точка", подобные PPP, несколько отличаются от традиционной IP-модели. Хотя они и могут иметь IP-адреса и подмаски, но необходимости в этом нет.
В простых сетях достаточно определить, что пункт назначения достижим и найти маршрут, который будет удовлетворительным. В сложных сетях обычно имеется несколько возможных маршрутов. Иногда хотелось бы иметь возможности по установлению дополнительных критериев для выбора пути: например, наименьшая задержка, максимальная пропускная способность или наименьшая стоимость (в сетях с оплатой за пакет). По этим причинам протокол OSPF позволяет сетевому администратору назначать каждому интерфейсу определенное число, называемое метрикой, чтобы оказать нужное влияние на выбор маршрута.
Число, используемое в качестве метрики пути, может быть назначено произвольным образом по желанию администратора. Но по умолчанию в качестве метрики используется время передачи бита в 10-ти наносекундных единицах (10 Мб/с Ethernet'у назначается значение 10, а линии 56 Кб/с - число 1785). Вычисляемая протоколом OSPF метрика пути представляет собой сумму метрик всех проходимых в пути связей; это очень грубая оценка задержки пути. Если маршрутизатор обнаруживает более, чем один путь к удаленной подсети, то он использует путь с наименьшей стоимостью пути.
В протоколе OSPF используется несколько временных параметров, и среди них наиболее важными являются интервал сообщения HELLO и интервал отказа маршрутизатора ( router dead interval).
HELLO - это сообщение, которым обмениваются соседние, то есть непосредственно связанные маршрутизаторы подсети, с целью установить состояние линии связи и состояние маршрутизатора-соседа. В сообщении HELLO маршрутизатор передает свои рабочие параметры и говорит о том, кого он рассматривает в качестве своих ближайших соседей. Маршрутизаторы с разными рабочими параметрами игнорируют сообщения HELLO друг друга, поэтому неверно сконфигурированные маршрутизаторы не будут влиять на работу сети. Каждый маршрутизатор шлет сообщение HELLO каждому своему соседу по крайней мере один раз на протяжении интервала HELLO. Если интервал отказа маршрутизатора истекает без получения сообщения HELLO от соседа, то считается, что сосед неработоспособен, и распространяется новое объявление о сетевых связях, чтобы в сети произошел пересчет маршрутов.
Пример маршрутизации по алгоритму OSPF
Представим себе один день из жизни транзитной локальной сети. Пусть у нас имеется сеть Ethernet, в которой есть три маршрутизатора - Джон, Фред и Роб (имена членов рабочей группы Internet, разработавшей протокол OSPF). Эти маршрутизаторы связаны с сетями в других городах с помощью выделенных линий.
Пусть произошло восстановление сетевого питания после сбоя. Маршрутизаторы и компьютеры перезагружаются и начинают работать по сети Ethernet. После того, как маршрутизаторы обнаруживают, что порты Ethernet работают нормально, они начинают генерировать сообщения HELLO, которые говорят о их присутствии в сети и их конфигурации. Однако маршрутизация пакетов начинает осуществляться не сразу - сначала маршрутизаторы должны синхронизировать свои маршрутные базы (рисунок 8.6).
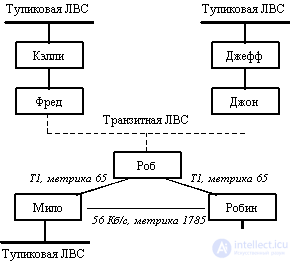
Fig. 8.6. Гипотетическая сеть с OSPF маршрутизаторами
На протяжении интервала отказа маршрутизаторы продолжают посылать сообщения HELLO. Когда какой-либо маршрутизатор посылает такое сообщение, другие его получают и отмечают, что в локальной сети есть другой маршрутизатор. Когда они посылают следующее HELLO, они перечисляют там и своего нового соседа.
Когда период отказа маршрутизатора истекает, то маршрутизатор с наивысшим приоритетом и наибольшим идентификатором объявляет себя выделенным (а следующий за ним по приоритету маршрутизатор объявляет себя резервным выделенным маршрутизатором) и начинает синхронизировать свою базу данных с другими маршрутизаторами.
С этого момента времени база данных маршрутных объявлений каждого маршрутизатора может содержать информацию, полученную от маршрутизаторов других локальных сетей или из выделенных линий. Роб, например, вероятно получил информацию от Мило и Робина об их сетях, и он может передавать туда пакеты данных. Они содержат информацию о собственных связях маршрутизатора и объявления о связях сети.
Базы данных теперь синхронизированы с выделенным маршрутизатором, которым является Джон. Джон суммирует свою базу данных с каждой базой данных своих соседей - базами Фреда, Роба и Джеффа - индивидуально. В каждой синхронизирующейся паре объявления, найденные только в какой-либо одной базе, копируются в другую. Выделенный маршрутизатор, Джон, распространяет новые объявления среди других маршрутизаторов своей локальной сети. Например, объявления Мило и Робина передаются Джону Робом, а Джон в свою очередь передает их Фреду и Джеффри. Обмен информацией между базами продолжается некоторое время, и пока он не завершится, маршрутизаторы не будут считать себя работоспособными. После этого они себя таковыми считают, потому что имеют всю доступную информацию о сети.
Посмотрим теперь, как Робин вычисляет маршрут через сеть. Две из связей, присоединенных к его портам, представляют линии T-1, а одна - линию 56 Кб/c. Робин сначала обнаруживает двух соседей - Роба с метрикой 65 и Мило с метрикой 1785. Из объявления о связях Роба Робин обнаружил наилучший путь к Мило со стоимостью 130, поэтому он отверг непосредственный путь к Мило, поскольку он связан с большей задержкой, так как проходит через линии с меньшей пропускной способностью. Робин также обнаруживает транзитную локальную сеть с выделенным маршрутизатором Джоном. Из объявлений о связях Джона Робин узнает о пути к Фреду и, наконец, узнает о пути к маршрутизаторам Келли и Джеффу и к их тупиковым сетям.
После того, как маршрутизаторы полностью входят в рабочий режим, интенсивность обмена сообщениями резко падает. Обычно они посылают сообщение HELLO по своим подсетям каждые 10 секунд и делают объявления о состоянии связей каждые 30 минут (если обнаруживаются изменения в состоянии связей, то объявление передается, естественно, немедленно). Обновленные объявления о связях служат гарантией того, что маршрутизатор работает в сети. Старые объявления удаляются из базы через определенное время.
Представим, однако, что какая-либо выделенная линия сети отказала. Присоединенные к ней маршрутизаторы распространяют свои объявления, в которых они уже не упоминают друг друга. Эта информация распространяется по сети, включая маршрутизаторы транзитной локальной сети. Каждый маршрутизатор в сети пересчитывает свои маршруты, находя, может быть, новые пути для восстановления утраченного взаимодействия.
Сравнение протоколов RIP и OSPF по затратам на широковещательный трафик
В сетях, где используется протокол RIP, накладные расходы на обмен маршрутной информацией строго фиксированы. Если в сети имеется определенное число маршрутизаторов, то трафик, создаваемый передаваемой маршрутной информацией, описываются формулой (1):
(one) F = (число объявляемых маршрутов/25) x 528 (байтов в сообщении) x
(число копий в единицу времени) x 8 (битов в байте)
В сети с протоколом OSPF загрузка при неизменном состоянии линий связи создается сообщениями HELLO и обновленными объявлениями о состоянии связей, что описывается формулой (2):
(2) F = { [ 20 + 24 + 20 + (4 x число соседей)] x
(число копий HELLO в единицу времени) }x 8 +
[(число объявлений x средний размер объявления) x
(число копий объявлений в единицу времени)] x 8,
где 20 - размер заголовка IP-пакета,
24 - заголовок пакета OSPF,
20 - размер заголовка сообщения HELLO,
4 - данные на каждого соседа.
Интенсивность посылки сообщений HELLO - каждые 10 секунд, объявлений о состоянии связей - каждые полчаса. По связям "точка-точка" или по широковещательным локальным сетям в единицу времени посылается только одна копия сообщения, по NBMA сетям типа frame relay каждому соседу посылается своя копия сообщения. В сети frame relay с 10 соседними маршрутизаторами и 100 маршрутами в сети (подразумевается, что каждый маршрут представляет собой отдельное OSPF-обобщение о сетевых связях и что RIP распространяет информацию о всех этих маршрутах) трафик маршрутной информации определяется соотношениями (3) и (4):
(3) RIP: (100 маршрутов / 25 маршрутов в объявлении) x 528 x
(10 копий / 30 сек) = 5 632 б/с
(4) OSPF: {[20 + 24 + 20 + (4 x 10) x (10 copies / 10 seconds)] +
[100 routes x (32 + 24 + 20) + (10 copies / 30 x 60 seconds]} x 8 = 1,170 bps
As can be seen from the results, for our hypothetical example, the traffic generated by the RIP protocol is almost five times more intense than the traffic generated by the OSPF protocol.
Using other routing protocols
The case of using only the OSPF routing protocol network is unlikely. If the network is connected to the Internet, then such protocols as EGP (Exterior Gateway Protocol), BGP (Border Gateway Protocol , Border Router Protocol), the old RIP routing protocol, or the manufacturers' own protocols can be used.
When OSPF begins to be used on the network, existing routing protocols can continue to be used until they are completely replaced. In some cases, it will be necessary to declare static routes configured manually.
In OSPF, there is the concept of autonomous systems of routers (autonomous systems), which are routing domains that are under common administrative control and use a single routing protocol. OSPF refers to a router that connects an autonomous system with another autonomous system, using a different routing protocol, as an autonomous system boundary router (ASBR).
In OSPF, routes (namely routes, that is, network numbers and distances to them in the external metric, and not topological information) from one autonomous system are imported into another autonomous system and distributed using special external link ads.
External routes are processed in two stages. The router chooses the route with the smallest external metric among the external routes. If it turns out that there are more than 2, then the path with the lower cost of the internal path to the ASBR is chosen.
An OSPF area is a collection of contiguous interfaces (territorial lines or local area network channels). Introducing the concept of "area" serves two purposes - information management and the definition of routing domains.
To understand the principle of information management, consider a network that has the following structure: a central local area network is connected using 50 routers with a large number of neighbors via X.25 networks or frame relay (Figure 8.7). These neighbors represent a large number of small remote units, for example, sales departments or bank branches. Due to the large size of the network, each router must store a huge amount of routing information that must be transmitted on each of the lines, and each of these circumstances increases the cost of the network. Since the network topology is simple, most of this information and the traffic it creates does not make sense.
For each of the remote branches, it is not necessary to have detailed routing information about all other remote offices, especially if they interact mainly with central computers connected to central routers. Similarly, central routers do not need to have detailed information about the topology of communications with remote offices connected to other central routers. At the same time, central routers need the information needed to transfer packets to the next central router. The administrator could easily divide this network into smaller routing domains in order to limit the amount of storage and transmission over communication lines that are not necessary information. Summarizing routing information is the main purpose of introducing areas into OSPF.

Fig. 8.7. Large network with star topology
OSPF also defines the area border router (ABR). ABR is a router with interfaces in two or more areas, one of which is a special area called the backbone area. Each area works with a separate route information base and independently calculates routes using the OSPF algorithm. Border routers transfer data about the area topology to neighboring areas in a generalized form - in the form of calculated routes with their weights. Therefore, in the network, divided into areas, is no longer valid statement that all routers operate with identical topological databases.
The ABR router takes the OSPF route information computed in one area and transmits it to another area by including this information in a generalized summary (summary) for the database of another area. Summary information describes each subnet of a region and provides a metric for it. Summary information can be used in three ways: to announce a separate route, to summarize several routes, or to serve as a default route.
A further reduction in resource requirements for routers occurs when the area is a stub area. This attribute can be applied by the network administrator to any area except the trunk. The stub ABR does not distribute external ads or summary ads from other areas. Instead, it makes one summary ad that will satisfy any IP address that has a network number different from the network numbers of the stub area. This announcement is called the default route. The dead-end routers have the information necessary only to calculate the routes between each other, plus instructions that all other routes should pass through the ABR. This approach allows us to reduce the amount of routing information in remote offices in our hypothetical network without reducing the ability of routers to transmit packets correctly.


Border gateway protocol
BGP (English Border Gateway Protocol, Border Gateway Protocol) is a dynamic routing protocol.
It belongs to the class of external gateway routing protocols (EGP - External Gateway Protocol).
BGP protocol:
• External routing
• Integration of autonomous systems in the Internet
Remote vector protocol:
• Path Vector
Routing policies:
• You can choose which autonomous systems to announce

Comments
To leave a comment
Computer networks
Terms: Computer networks