Lecture
Chapter 1. Version Control Systems.
1.1 What is it?
1.2 Nakua necessary, and so everything works
1.3 How it works inside
1.4 How to work
1.5 Teamwork
1.6 Domashka
1.1 What are version control systems?
Version control systems are programs that allow you to track changes to your file and store them. At the same time, several people can immediately change the information in this file. We can move to earlier changes or vice versa to later ones.
In general, the monitoring system of versions of 2 types:
a) Centralized
b) Distributed.
Centralized.
Let's talk about the difference.
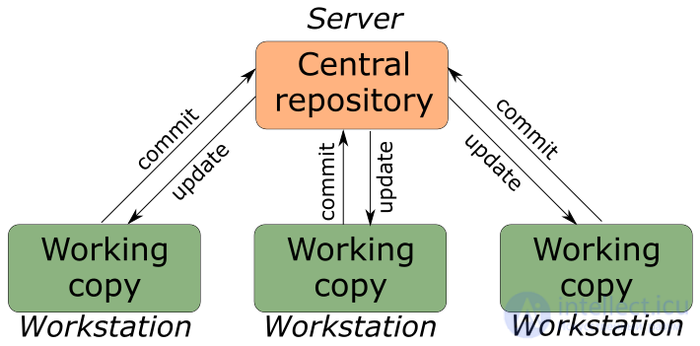
In centralized systems, all the code stores the central server (bla-bla-bla). All software developers have access. The disadvantages of this approach are that the developer does not have his own repository, and if the server fails, it will fall down, will be burned (underline the necessary). That no one will have a full working version of the software. The exchange also takes place as decentralized.
Currently, they are not very popular, so we will not dwell in detail, so as not to clog our heads. Who is interested can google a lot of information, for example: SVN
Decentralized
Here it is already much more interesting - let's dwell in more detail in the second part. While a brief description of how it works.

as we see, we have a central repository, and at the same time each developer has his own, so if something goes wrong, we can quickly restore the relevance of the state of the software.
Briefly reviewed, let's take a closer look now on decentralized.
1.2 Nakua need and how it works
Everyone is familiar with the situation:

----------------------------

Folders of course can be called in different ways. For example: "design rules", etc.
In the folder "Change Vasya" the index.php file, etc. has changed.
You can solve this problem in this way:
Vasya writes to fix the file
...
...
etc.
Peter writes to fix the file
...
...
etc.
So, imagine that you are working on a project so people are 20, how to quickly show the project to the customer with all the changes?
Correctly thought, opens the file and start copying the files with the changes in the folder "Working version". Doesn't anything seem strange to you? :) write in the comments what you think about this approach.
And we suddenly have a situation that Vasya and Petya edited one file.
What do we do?
To be honest, I xs, how to solve this, but the release period was postponed until the problem is solved.
The head does not stroke exactly.
This is where our repository comes to the rescue.
I will consider git, the materials given by me is a book on git
link to book:
https://git-scm.com/book/ru/v1/
and so we went.
I will not consider installing git server on my PC
Some moments, I will specifically omit, they are simple and most often found in the material to which I cite links. They will appear as questions by the end of a chapter or section.
And so we already know that our git is hard currency.
How does it work and why is it today a leader in this field?
Really all code is stored on the server, each file.
This is not the case.
Firstly, all the changes are happening to you locally. Those. the server does not know what you have done there. Infa comes esma after you sent her there.
Locally at the moment of adding a file, information about the name of the file is added, what is in it (if only added), and then information about the changes is entered (I would call it the change delta), who created it, the branch (I’ll tell you later) and the comment.
It turns out this picture:
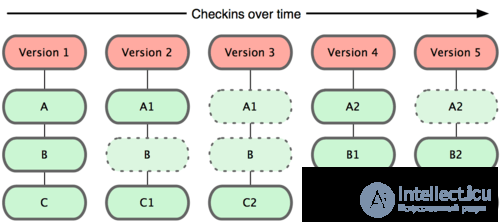
Let's take a closer look at what is displayed here:
Version - history of changes (commits)
A, B, C - files.
Probably you have any questions, che for ** but one dotted line, others not.
So this is the versioning. Git itself does not save the complete file to itself each time you save a state. It saves only changes to changed files. If the file has not changed, then it will be simply (conditionally) said (actually the link to the file), the file is unchanged.
It turns out that we can see what exactly in which line has changed in the file.
Removed or added. At the same time quite compact.
On this let's finish. The basis is set, then follow the link. And we will go further.
The most important.
File states in git. This is really important; without this, it is impossible to understand how the version control system works.
and so, there are three states:
a) prepared - will be included in the repository when commit
b) modified - changed file
c) fixed - fixed, then sent from a local repository (remember where it is, yes?)
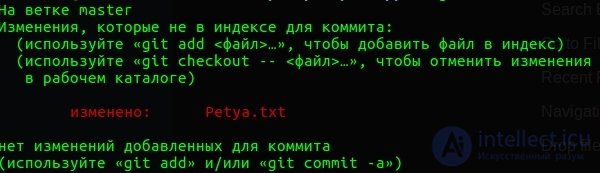
As you can see, we have a Petya.txt file. Git sees it and informs us that this file has not been added to our change tracking. now the file has none of the three states.
They are called non-monitored files. Well, it follows as if from this.

Now add the file to the tracking.
(For the time being, I omit the teams, we will come to them.)

Now we have the file took the state number 1 - prepared, i.e. when we save data locally to the repository, it will be included in the product for changes. In this case, changes have already begun to be tracked.

Now the file is recorded in our local repository. State number 3, when sent to the server from will be sent.
And now let's make state number 2. Let's write a line inside the file:
Petya the Best. As you can see in the picture below, git marked our file as modified.
Fuhhhh ....... Well. Take a break for half an hour, let the material settle down. And we will continue. The article is huge.
-------------------------------------------------- --------------------------------------------
Rested, poured tea. We go further.
And so, what to do to get started.
Further and throughout almost all posts I will use git for work, please take this post seriously.
First, let's put the necessary programs to work.
Linux: link to the installation manual
Windows: http://msysgit.github.com/For those using Windows, the git developers wrote:
"Please use Git only from the shell command included with msysGit, because this way you can run the complex commands shown in the examples in this book. The Windows command shell uses a different syntax, which may cause the examples in it to work incorrectly."
After you have installed the application, let's proceed to the practical part.
When the author of the article was taught to use team development technologies, we had 2 days of theory and 4 days of practice, we were given a whole server for 20 people and we did everything we wanted with them as part of the tasks. That is why I try to focus on just about a part of the entire course. Well, if you can say so (:
In fact, we have two ways to create a repository. Consider.
1. To clone ready, (let's say at work has long been created)
2. Create a new one locally.
And so the way is the 1st.
Go to bitbucket.org (github, etc.)
register, there is a button to create a repository, (I will not stop, the network is full of materials how to do it).
on the PC we create a directory in which there will be a copy of our software cloned from the server. We write the command:
git clone https://bitbucket.org/bla-bla-lba (in the newly created bitbucket repository there is already a link to the project).
We should see the project in our folder, folder name = project name.

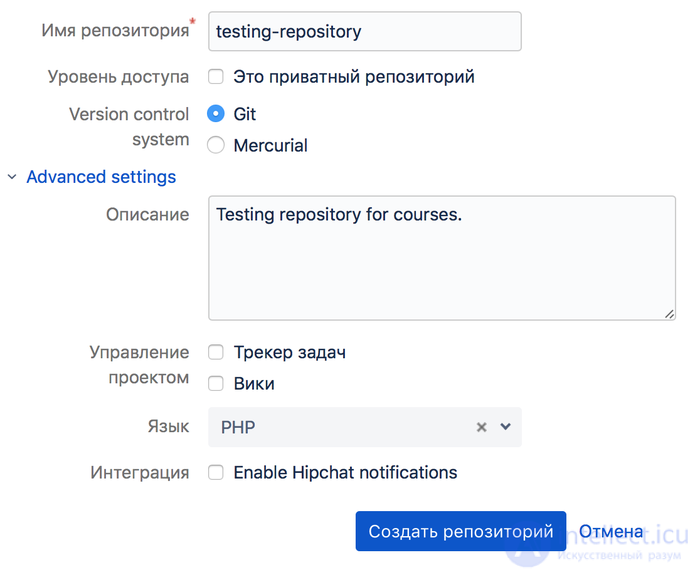
Click to create. All our bitbucket repository is created.
We can get to work. Below on the page we have two links:
I already have a project
I start completely from scratch
Now we choose, I start the project from scratch:
git clone https: //nibbler-ws@bitbucket.org/nibbler-ws/testing-repository.git
We get a link to the cloning of our project to our PC.
I would advise everyone who starts programming or who already knows how to use the console.
Now open the console and rushed.
1. Select the folder where we will clone our empty (for now) repository.
Actually my folder where we will perform this action.
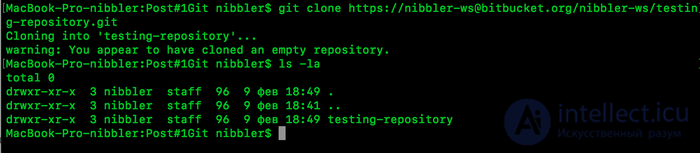
Oops, our repository is ready. Now we have two repositories, one on our server, the second on our PC.
And so the repository is ready, let's get down to working with files. But for starters let's start briefly through GUI applications for git:
GitKraken - in my opinion just beautiful :) This bastard is paid, but beautiful.
There is a free plan

Otherwise, you can get by with the console, since I work mainly on Ubuntu / Mac, I can name a couple more clients, but you can just google it.
Okay, breathed, let's start. Create a file in our Petya.txt folder
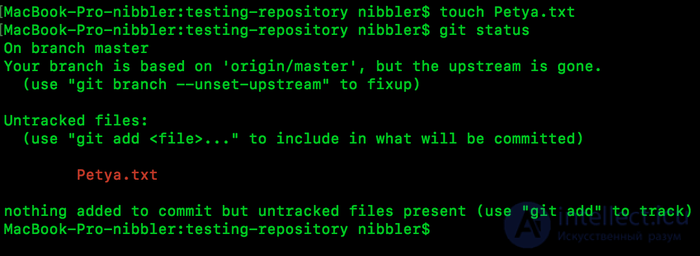
touch and the other commands I use, please search the Internet, they are simple, and you immediately learn the console.
and so we made a clone of the repository earlier, went to the folder, created the Petya.txt file and asked git to show the status (let's call it that). In this case, git tells us that it sees our file, but it does not track it. What does this mean, and this means that nothing that we write there will not get on our server. Let's try to capture our changes.
We were told what kind of guy? You have not added nichrome, let's work. And showed that there are files that simply does not track. Again :) We will always see them.
Well, let's say follow his file.

Strange, but we were not told anything. Of course, why :) we have already just added the file
But if we now request the status we will see the following picture:
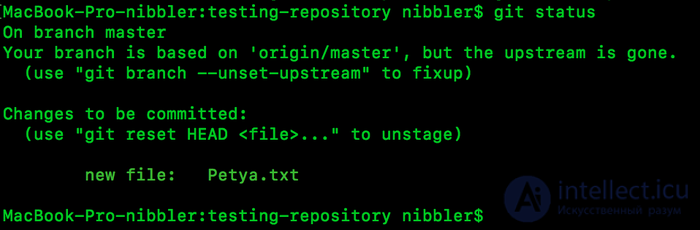
Yeah, we got the desired status, the file is tracked. Fine. Now I want to clarify.
The fact that the file is being tracked does not mean that you can return absolutely all changes. Here nifiga like :) you can return only the changes that were fixed in the state of your repository. It clearly looks like this:
A: (Line HAHA) fix the changes | (Line ХАХАХ) -> (Line ХАХАХ2) -> (Line ХАХАХ123) -> (Line ХАХАХ Кх-Кх) we fix the changes.
In the end, we will have a file in the repository in two states:
A: (Line HAHAH) -> (Line HAHAHA Khe-Khe).
I hope this is clear. We go further. Let's make the first commit now (commit changes).

We were informed that our file is fixed. 1 file changed, 0 lines added, 0 deleted.
and hash. Cool true :)
Let's look at the log (history of fixations):

Great, let's look at what we did:
commit - commit hash, for which he will tell later.
The author is the one who actually created the commit.
date
And a list of files that have been changed.
Now we will send our changes to the server. We already remember that our file was added and fixed, now that all developers see it we need to do a push (or send to our server).
For this we do git push.
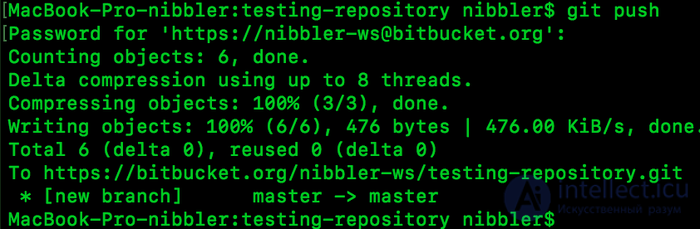
I still have the last block that I can add :) his mother and yes, my article didn’t fit completely first, you need to think something :)
Reading your comments and browsing the links came across such a comment from picabushnika.
"Here you write that your posts in the hot fuck are not needed. I only came across you on 30 lectures." Proof by reference
I now do not even know, ask somehow uncomfortable you. And people suffer: (
PY.SY. The second part is also ready already, everything just did not fit. Soon I hope I can publish in two parts. Tomorrow then home pancake.
By the nature of my work, I often witness "holy wars" between fellow programmers on which version control system to choose for a project. The role of the version control system is particularly acute in cases of developing and supporting projects with a long history. There are a lot of tool options, but I want to concentrate on two, in my opinion, the most promising: Mercurial and Git. Next, we will try to consider the capabilities of both systems from the perspective of their internal structure.
A bit of history
The impetus for the creation of both systems, both Mercurial and Git, was one 2005 event. The thing was that in the year 2005, the Linux kernel lost the opportunity to use the BitKeeper version control system for free. After using BitKeeper for three years, kernel developers are accustomed to its distributed workflow. Automated work with patches greatly simplified the process of recording and merging changes, and the presence of a history over a long period of time allowed for a regression.
The hierarchical organization of developers has become another important part of the Linux kernel development process. At the top of the hierarchy stood the Dictator and many Lieutenants in charge of the individual subsystems of the nucleus. Each Lieutenant accepted or rejected individual changes within his subsystem. Linus, in turn, dragged their changes and published them in the official repository of the Linux kernel. Any tool that replaced BitKeeper had to implement such a process.
The third critical requirement for the future system was the speed of work with a large number of changes and files. The Linux kernel is a very large project that accepts thousands of individual changes from thousands of different people.
Among the many tools suitable was not found. Almost simultaneously, Matt Mackall and Linus Torvalds release their version control systems: Mercurial and Git, respectively. Both systems were based on the ideas of the Monotone project that emerged two years earlier.
Similarity
Both version control systems have a number of common features:
Differences
Despite the commonality of ideas and high-level functionality, the implementation of systems at a low level is largely different.
History storage
Both Git and Mercurial identify file versions by their checksum. The checksums of the individual files are combined into manifests. In Git, manifests are called trees, in which some trees may point to others. Manifests are directly related to revisions / fixations.
Mercurial uses a special Revlog storage engine to improve performance. Each file placed in the repository is associated with two others: an index and a file with data. Data files contain nuggets and delta nuggets that are created only when the number of individual file changes exceeds a certain threshold value. The index serves as a tool for efficient access to the data file. Delta, resulting from the modification of files under version control, are added only to data files. In order to edit from different places of the file to merge into one revision, an index is used. The audits of individual files are manifested, and from the manifests, fixations. This method has proven to be very effective in creating, searching, and calculating file differences. Also, the advantages of the method include compactness with respect to disk space and a fairly effective protocol for transferring changes over the network.
The Git storage model is based on large object binary files (BLOBs). Each new revision of the file is a complete copy of the file, which results in the rapid saving of revisions. Copies of files are compressed, but still, large volumes of duplication take place. Git developers have applied data packaging techniques to reduce storage requirements. Essentially they created something similar to Revlog for a specified point in time. Packages obtained as a result of packaging differ from Revlog, but they pursue the same goal - to save data, effectively spending disk space. In view of the fact that Git saves file nuggets, rather than increment, commits can be easily created and destroyed. If the analysis requires to see the difference between two different fixations, then in Git the difference (diff) is calculated dynamically.
Branching
Branching is a very important part of configuration management systems, since it allows you to conduct a parallel development of new functionality, while maintaining the stability of the old. Branch support is present in both Git and Mercurial. The differences in the format of storing the history are reflected in the implementation of branching. For Mercurial, a branch is a kind of mark that is attached to a fix forever. This mark is global and unique. Any person pulling in changes from a remote repository will see all the branches in his repository and all the fixations in each of them. For Mercurial, a branch is a public development site outside the main trunk. Branch names are published to all participants, so the time-stable version numbers are usually used as names.
Branches of Git, in fact, are only pointers to commit. In different clones of the repository, branches with the same name may indicate different fixations. Branches in Git can be deleted and transferred separately (each is uniquely identified by its local name in the source repository).
Practical aspects of use
The differences in the implementations of Git and Mercurial can be illustrated with examples.
Mercurial makes it easy to commit changes, push and pull them with the support of all previous history. Git does not care about the support of the entire previous story, it only fixes the changes and creates pointers to them. For Git, the previous history doesn’t matter and what the pointers previously referred to, it’s important what’s relevant at the moment. There is even a tool that guarantees the preservation of local history when pulling changes from external storage — fast-forward merge. If this mechanism is enabled, Git will report changes that cannot be resolved without moving forward in history. These errors can be disregarded if the submitted changes are expected.
When performing a rollback commit or merge with merge, Git simply changes the branch pointer to the previous commit. In fact, at any time when you need to roll back to some previous state, Git searches the log for the corresponding checksum and tells which commit it corresponds to. Как только что-то зафиксируется в Git, то всегда можно к этому состоянию вернуться. Для Mercurial существуют случаи, когда невозможно полностью вернуться в исходное состояние. Because Mercurial для решения какой-либо проблемы создает фиксацию, то в некоторых случаях затруднительно переместиться назад с учётом свежего изменения.
Для решения различных проблем в Mercurial существуют расширения. Каждое расширение решает свои проблемы хорошо, если существует само по себе. Существует даже некоторые расширения, обеспечивающие сходную функциональность, но разными способами.
For example, consider the work with deferred history. Suppose we need to record changes from a working copy without committing to the repository. Git suggests using stash. Stash is a fix or a branch that is not stored in the usual place. Stash is not shown when a list of branches is displayed, but with all tools it is treated as a branch. If similar functionality is required by Mercurial, then attic or shelve extensions can be used. Both of these extensions store “deferred” history as files in the storage, which can be fixed if necessary. Each extension solves the problem in a slightly different way, so there is an inconsistency in the formats.
Другой пример, команда git commit --amend. Если нужно изменить самую последнюю фиксацию, например, добавить что-нибудь забытое или изменить комментарий, то команда git commit --amend создаст полностью новый набор файловых объектов, деревьев и объектов фиксации. После этого обновляется указатель ветки. Если далее потребуется откатить изменения, то необходимо только вернуть указатель на предыдущую фиксацию командой git reset --hard HEAD@{1}. Чтобы повторить это в Mercurial потребуется откатить фиксацию, затем создать новую, далее импортируем содержимое последней фиксации при помощи расширения queue, дополняем её и делаем новую фиксацию.
Следует заметить, что ни одно из перечисленных выше дополнений не использует возможности формата хранения Mercurial, и таким образом они существуют исключительно как самостоятельная надстройка над ним.
findings
В последнем разделе этой статьи хотел бы высказать собственное мнение по выбору системы контроля версий. И Mercurial, и Git хороши в своих сегментах.
Например, для целей ведения коммерческого программного проекта мне больше импонирует Mercurial.
Для хранения бинарных файлов, например, электронной библиотеки, Git подходит лучше. По сравнению с Mercurial он не ориентирован на расчет дельты файлов, что для бинарного содержимого не очень эффективно. Сами файлы меняются редко, а основные операции с ними — это перемещение и добавление. По моим собственным наблюдениям папка хранилища Git с историей моей библиотеки сопоставима по размерам с рабочей копией с окрестностью примерно 10%.
Источники знаний
 Для начала я хочу внести ясность в понятие коммерческой разработки и её отличий от других моделей. В коммерческой разработке принято ставить конкретные цели и отслеживать этапы выполнения работы. Тогда как, например, в open source моделях разработки, обычно цели ставит перед собой отдельный разработчик, а этапность их исполнения и привязка к бизнес требованиям никого не интересует.
Для начала я хочу внести ясность в понятие коммерческой разработки и её отличий от других моделей. В коммерческой разработке принято ставить конкретные цели и отслеживать этапы выполнения работы. Тогда как, например, в open source моделях разработки, обычно цели ставит перед собой отдельный разработчик, а этапность их исполнения и привязка к бизнес требованиям никого не интересует.
Зачем вообще нужна система контроля версий? Есть несколько причин:
— Обеспечить одновременную возможность работы коллектива над кодом;
— Сохранить лог всех изменений и версий для того чтобы при необходимости вернуть версию или часть кода, а также разобраться в проблеме на основе анализа изменений.
Главное отличие — «Its all in branches», как сформулировал однажды Felipe Contreras в своём блоге. В статье приведена масса аргументов, почему git технически лучше, чем mercurial, и большинство из этих аргументов бесспорны. Действительно, для программиста проекта open source на сегодняшний день git — лучший выбор.
Да и вообще, если спрашивать только программистов, в том числе на коммерческих проектах, выбор тоже будет преимущественно в пользу git. Видимо, процесс выбора системы контроля версий полностью отдаётся на откуп программистам, а они, конечно же, выберут самый технически совершенный инструмент на рынке, чем и является на сегодня git.
Но этот выбор может оказаться сомнительным, если взглянуть на него с точки зрения PM. А вот многие слабые места Mercurial оказываются, на поверку, его сильными сторонами.
I propose to consider the following differences git vs. mercurial in the context of their convenience for PM and the commercial project as a whole:
- the impossibility of deleting branches, commits, i.e. changes to the repository history;
- the level of difficulty of learning;
- “heavy” branches, in which commits the branch is tied directly.
Change Traceability
On all our projects, Traceability support allows us to work more efficiently. If you go back to the beginning of the article, the trace allows us to track:
- phased changes;
- binding changes to business requirements.
How this is implemented in practice: a bunch of tasks is encoded in the name of the branch, for example: 29277_pivot_table , 30249_summary_page , 30081_agroups , 28255_angularjs_todo . We work with those very “heavy” branches in which the branch is tied to a commit. The branch number encodes the task number and a brief description. Then, if suddenly in hg annotate (an analogue of the blame command) we try to understand who changed a specific line of code, it will not be difficult for us to open the tracking system with the task number. The task, in turn, lists (by usual comments) a list of all changes to this task.
And if suddenly the customer asks me a question: “Who cut the important banner on the first page with the advertisement of the main advertiser?” - I can clearly answer by indicating the link to the business requirement and the task associated with it.
Full tracing is not possible in Git for several reasons:
- Branch can be deleted. Git, as a more powerful tool, allows you to remove branches and other parts of the log from history. That is, it may well turn out that only merge commit will remain, in which only a common reason can be indicated (for example, “the infusion of version 11 in the master”).
- You may find commit developer, but this is not a solution. The commit may say: “I sawed a banner”. And why it happened - the mystery is covered with darkness. Here it is necessary to focus on the fact that developers must put the task number in commit msg. I regularly observe this picture in teams that work with git, and there I regularly observe 40-60% percent of commits without a task tag.
In order to somehow solve this problem, in Jira it is worth auto-tracking commits by the task number, which coincides with the name of the project. But this is not enough for a 100% guaranteed result.
The complexity of training and operation
Most people who use git don't understand what I'm talking about. Well, yes, they “already” work, in 90% of cases without going into details why this is so arranged. Some have a “cheat sheet” on a piece of paper that lists the most frequently used commands.
I can’t deny myself the pleasure of trolling git users, who consider its syntax logical and understandable.
1. Separating repository types in git and the clone command
Let's start with the first step, and here I immediately see some inconvenience of git in real life. Both the git and mercurial syntax for the clone command is the same:
git clone <where> <where>
hg clone <where> <where>
It seems everything is logical? Everything, but not quite. In Git, it turns out, there is a division of repositories into clones for developers (workers) and clones for the server (bare). This was done, apparently, for optimization purposes, but as a result, in order to exchange code with a neighbor programmer, it will not be enough for me to simply write hg push ssh: // otheruser @ othercomp , and you will need to create a bare repository and organize code exchange based on it.
2. Work with branches
Git will have to learn a whole section describing how to work with local and remote branches, how to clone them, commit them, etc. This, of course, is good if it is actually used. This superfish is important for open source, when you can play locally on different branches and send only those branches that are already completed and ready for consideration to be evaluated by the community.
In the commercial PM development model, it is important to see the volume and quality of the work done every day, and sometimes more often. And, accordingly, it is convenient that all working branches are uploaded to the server, which by default happens in mercurial.
I do not want to say that working with local / remote branches is bad. Optionally, I would not mind such a feature in mercurial. But its usefulness in our daily work is in great doubt.
In addition, this functionality rather complicates the command syntax. If in Mercurial, all you need to know are simply commands to create, transition between branches, then in git everything is much more complicated. And although complex functionality is rarely claimed, they have to use everything. Examples for comparison:
| hg | git | comment |
| hg diff | git diff HEAD | show current changes |
| hg up branchname | git checkout -b branchname origin / branchname | go to branch |
| hg push | git push git push origin master | send changes to the server |
At first it was difficult for me to understand what origin was and why it is necessary to specify a branch.
In terms of simplicity, Mercurial is really straightforward. Sends all local default branches to the server, the same happens in the opposite situation.
Be careful with the git call syntax. For example, to delete a branch in git, a not very clear construction of the type git push origin: the_remote_branch is used. That is, we send "empty" to replace the branch on the server - as a result of the command, the branch on the server is deleted.
From a management point of view, this is a dangerous team. I would forbid such if I could :) Or, alternatively, back up the main repository from time to time.
In Mercurial, nothing can be removed (in a trivial way). For me, as for PM, this is a plus, for a developer, rather a minus.
Ease of remembering commands in Mercurial
Compare:
| hg | git |
| hg in | git fetch && git log master..FETCH_HEAD |
| hg out | git fetch && git log FETCH_HEAD..master |
| hg purge | git clean -fd |
| hg revert -a | git reset --hard |
| hg addremove | git add.; git ls-files --deleted xargs git rm |
| hg glog | git log --graph --all --decorate |
Well, the encoded git config compared to the usual simple .hg / hgrc file
All of the above advantages in some way may be minuses. For example, the most problematic situation is that you should not add huge files to the repository. One of our customers decided that this way you can add media files, including commercials, and the size of the repository has grown dramatically by the size of the video, multiplied by two. It was impossible to delete them in a simple way; I had to use ConvertExtension.
The second minus - you get used to good quickly. Having worked a bit with mercurial, it is quite difficult to go back to git, because you have to remember the fuzzy syntax for simple things.
The third drawback is that you, like PM, most likely will not be able to convince your programmers of the need to switch to Mercurial. The reason is simple - they have already learned one syntax, they do not want to relearn themselves. Moreover, the obviously weaker features of the system. There is a chance if you start a new project.
The argument about what is better and what is worse depends heavily on the context of the tasks to be solved. My choice for today is simple - for Open Source I mainly use git, in commercial projects I use only Mercurial.
I want to wish the readers to make the right choice.
Virtually any software product is not the work of one person. If the project began to be developed by a single programmer, then one day the moment will come when an entire development team will be needed to support and further develop it. In this regard, the question arises about the correct and, most importantly, effective organization of joint development of systems, as well as control of the entire development process [12]. There is a need to keep track of all manipulations with project files and, if necessary, return them to a certain state [10].
Systems that solve this problem were called Version Control Systems (VCS). A version control system is a mechanism for storing intermediate code states of an application under development [13]. However, since the appearance of the first versions of such systems, a lot of time has passed, however, the needs have also grown: now version control systems allow for joint development, synchronization with the server and much more.
Version control systems are relevant not only in the field of software development. For example, the well-known Microsoft Office - office suite of applications - also allows you to control document versions: with a certain period of time, the document is automatically saved, which allows you to return to a certain version in the future. This is the most primitive version control system implementation, but for MS Office this is quite enough.
There are several different version control systems that differ in the principles of operation, the scope of their use and the concepts in general. Some of them are more popular, some - less, but each of them performs its main task - controls the version of the developed system.
Version control systems are divided into distributed and centralized. In centralized systems, there is a single code repository, managed by a special server, which performs most of the version control functions [7]. However, with this approach there are several serious flaws. The most obvious is that a centralized server is a vulnerability of the entire system. If the server is turned off for an hour, then within an hour the developers cannot interact, and no one can save the new version of their work [8].
Distributed systems work differently: here the latest version of files is not just downloaded from the server, but the repository is completely copied. This allows you to work with the system regardless of what happens to the system itself.
The most popular version control system at the moment is Git. It was developed by Linus Torvalds, the creator of the Linux open source operating system, in 2005. To this day, Git is used to manage the development of the GNU / Linux kernel, as well as for many other projects.
To understand the need to use version control systems, you need to find out what they control, what problems they solve, and how much they simplify development.
Version control systems allow you to track any changes in the code of the developed application and record them as a separate version of the entire application. This allows you at any time to roll back to any of the previous versions of the application, undo certain changes and just keep track of the development process. Version control systems store large amounts of information about when and what changes in the code were made [11].
File change control is the basic functionality of version control systems, which comes from their name. Modern version control systems allow you to develop an application in a team, as well as to synchronize all changes with the repository.
As mentioned earlier, there are several different version control systems: SVN, Mercurial, Bazaar, etc. Git has several advantages over its counterparts.
First, Git is different about storing information about changes. Most other version control systems, such as Subversion, use delta compression to store new versions, i.e. the system finds the differences of the new version from the previous one and writes only them, avoiding duplication of data [4]. Git also considers stored data as a collection of small file system snapshots. With each commit operation, Git essentially saves a snapshot of how all the project files currently appear. This saves memory, and also makes it possible to have the entire change history of the entire project on the local machine, without requiring access to the repository, which is an important aspect of using version control systems, and that other systems do not provide.
Secondly, Git works locally. For most operations, only local resources are needed. This allows you to achieve high speed with Git: for example, when viewing file changes, Git will not request any data from the server: all changes are stored on the local computer and are available at any time, and thanks to the unique principles for storing these changes, Git takes up less memory on the hard drive.
Git operates with a large number of commands, but only a few are enough for everyday work with it. Consider them in order.
Git clone is a command for cloning a remote repository to a local machine.
Git add - the command to add a working directory to the index (staging area) for the next commit.
Git status allows you to find out what state the files are in the working directory: changes, waiting for a commit, etc.
Git commit commits changes to files added to the index using git add. At the same time, in essence, a new version of the system is being created. It is important to understand that files in Git can be in one of three states (Figure 1).

Figure 1. File status in Git
The Working Directory is a copy of a specific version of a project. It is the working directory that is copied from the repository when the git clone command is executed.
The staging area is a file that stores information about changes that will be included in the next commit.
Repository (Repository) - a place to store the recorded changes.
Git push sends committed changes to the main repository.
Git pull - on the contrary, takes all new changes from the remote repository.
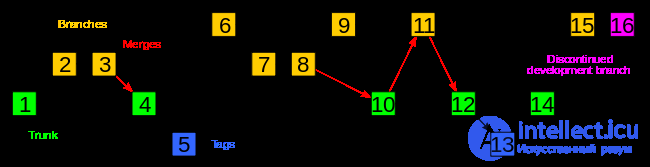
Git merge merges changes to several branches. Branches are a powerful tool in development. To understand its essence, let us imagine a situation where there is a task to develop a certain functional that will take quite a lot of time. However, at the same time, throughout this time there is a need to make other, minor changes to the project, but without affecting all the data of the new functionality. Branches are used in such situations: a new branch is created for the development of new modules, and all development is conducted in it. You can switch between branches, thus there are several different versions of the project, the development of which can be carried out in parallel. Branches, as a rule, are created for individual phases of project development and for pre-release versions, in which errors are fixed [5].
During the operation of merging branches, Git compares the contents of the corresponding commits, then merges the repository states of different versions of the project, forming a new version [2].
For distributed version control systems, a development branch is one of the fundamental concepts - in most cases, each copy of the version repository is a development branch [3].
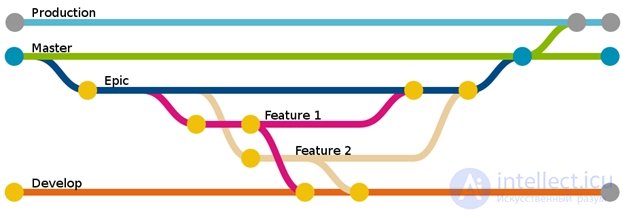
Figure 2. Branching and merging branches in Git
When new modules are developed and tested, the branches merge: all changes are entered into the main branch (master). In this case, of course, conflicts may arise if the same file was simultaneously modified by several developers. Usually in such cases, the system is not able to update the project on its own and requires intervention from the developer. [one]
Also, Git solves the problem of updating (deployment, deployment) on the server, where the system works directly (production). For this server, Git is also installed and updates the data from the repository with the git pull command. In order to automate this process, many services for storing projects that work with Git provide a mechanism for web hooks (WebHooks). It works as follows: for any change in the repository, an HTTP request is sent to the application server, where a pre-configured script runs a command to update data from the main repository.
On the basis of Git created a social network for developers called GitHub. This is not just a code storage service: network members can participate in the development of any open project, receive error messages from community members and offer their solutions. GitHub provides access to projects for both the development team and the controlling group. At the same time, the zones of authority of both groups do not overlap [6].
Git is the most popular version control system among developers. Corporations such as Google, Microsoft and others use it for part of their projects. In addition, to control versions of the most popular engine for displaying web pages called Webkit, which is used in most modern web browsers, developers use Git, and its source code is placed on GitHub. It is worth saying that the Webkit repository is one of the most popular in terms of the number of commits on Github, the number of which reached 180 thousand.
Development teams using Git are freed from a lot of team development problems. It can be said that Git solves most of the problems even before they appear, speeds up and cheapens the development process [9]. Each developer works in isolation on his task, without disturbing the others. Git backs up the project, allowing you to return to its original state when errors occur, and the application’s deployment becomes a task that can be solved with just a few git commands. All this saves developers time to perform routine (and not so) operations, allowing you to focus directly on development.
Git, compared to other version control systems, is more difficult to master, so developers are afraid to start using it. However, having gone to it and having worked with it for some time, comes the understanding that git is not just a fashionable trend of modern development of information systems, but a tool that allows developing development correctly.

Comments
To leave a comment
Software and information systems development
Terms: Software and information systems development