Lecture
Programming languages are quite different from each other in purpose, structure, semantic complexity, methods of implementation. This imposes its own specific features on the development of specific translators.
Programming languages are tools for solving problems in different subject areas, which determines the specifics of their organization and differences in purpose. As an example, such languages as Fortran, focused on scientific calculations, C, designed for system programming, Prolog, effectively describing problems of inference, Lisp, used for recursive processing of lists. These examples can be continued. Each of the subject areas has its own requirements for the organization of the language itself. Therefore, we can note the variety of forms of representation of operators and expressions, the difference in the set of basic operations, the decrease in the efficiency of programming in solving problems not related to the subject area. Language differences are reflected in the structure of translators. Lisp and Prolog are most often performed in the interpretation mode due to the fact that they use dynamic formation of data types during calculations. For Fortran translators, aggressive optimization of the resulting machine code is typical, which becomes possible due to the relatively simple semantics of the language constructs - in particular, due to the lack of alternative naming mechanisms for variables through pointers or links. The presence of pointers in the C language has specific requirements for dynamic memory allocation.
The structure of a language characterizes the hierarchical relations between its concepts, which are described by syntactic rules. Programming languages can vary widely in the organization of individual concepts and in the relationships between them. The PL / 1 programming language allows arbitrary nesting of procedures and functions, whereas in C all functions must be at the outer nesting level. The C ++ language allows the description of variables at any point of the program before its first use, and in Pascal the variables must be defined in a special description area. PL / 1 goes further in this question, which allows the description of a variable after its use. Or the description can be omitted altogether and follow the rules adopted by default. Depending on the decision made, the translator can analyze the program in one or several passes, which affects the speed of the broadcast.
The semantics of programming languages varies widely. They differ not only in the specifics of the implementation of individual operations, but also in programming paradigms, which determine fundamental differences in the methods of program development. The specifics of the implementation of operations may concern both the structure of the data being processed and the rules for processing the same data types. Languages such as PL / 1 and APL support matrix and vector operations. Most languages mostly work with scalars, providing for the processing of arrays of procedure and functions written by programmers. But even with the addition of two integers, languages such as C and Pascal may behave differently.
Along with the traditional procedural programming, also called imperative, there are such paradigms as functional programming, logic programming and object-oriented programming. I hope that the procedural-parametric programming paradigm proposed by me [Legalov2000] will take its place in this series. The structure of concepts and objects of languages strongly depends on the chosen paradigm, which also affects the implementation of the translator.
Even the same language can be implemented in several ways. This is due to the fact that the theory of formal grammars allows different methods for parsing the same sentences. In accordance with this, translators in different ways can get the same result (object program) in the original source text.
However, all programming languages have a number of common characteristics and parameters. This community also defines the principles of the organization of translators similar for all languages.
Regardless of the specifics of the language, any translator can be considered a functional converter F, providing a one-to-one mapping of X to Y, where X is a program in the source language, Y is a program in the target language. Therefore, the translation process itself can be formally presented quite simply and clearly:
Y = F (x)
Formally, each correct program X is a string of characters from some alphabet A, transformed into its corresponding string Y, composed of the characters of alphabet B.
A programming language, like any complex system, is defined through a hierarchy of concepts that defines the relationships between its elements. These concepts are interconnected according to syntactic rules. Each of the programs built according to these rules has a corresponding hierarchical structure.
In this regard, for all languages and their programs, the following common features can be singled out: each language should contain rules that allow generating programs corresponding to this language or recognizing the correspondence between written programs and a given language.
The connection of the program structure with the programming language is called syntactic mapping .
As an example, consider the relationship between the hierarchical structure and a string of characters that defines the following arithmetic expression:
a + (b + c) * d
In most programming languages, this expression defines the hierarchy of software objects, which can be displayed as a tree (Fig. 1.1.):
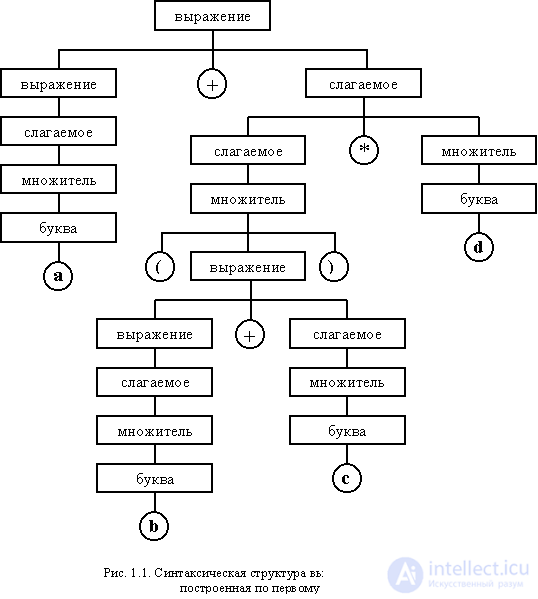
Circles represent symbols used as elementary constructions, and in rectangles, composite concepts are defined that have a hierarchical and, possibly, recursive structure. This hierarchy is defined with the help of syntax rules written in a special language called the metal language (more detailed metal languages will be considered when studying formal grammars):
<expression> :: = <term> | <expression> + <addend>
<term> :: = <multiplier> | <addendum> * <multiplier>
<multiplier> :: = <letter> | (<expression>)
<letter> :: = a | b | c | d | i | f | g | h | i | j | k | l | m | n | o | p | q | r | s | t | u | v | w | x | y | z
Note The ":: =" sign reads "this is". Vertical bar "|" read as "or."
If the rules are written differently, the hierarchical structure will also change. As an example, the following way to write rules:
<expression> :: = <operand> | <expression> + <operand> | <expression> * <operand>
<operand> :: = <letter> | (<expression>)
<letter> :: = a | b | c | d | i | f | g | h | i | j | k | l | m | n | o | p | q | r | s | t | u | v | w | x | y | z
As a result of the syntactic analysis of the same arithmetic expression, a hierarchical structure will be constructed, as shown in Fig. 1.2.
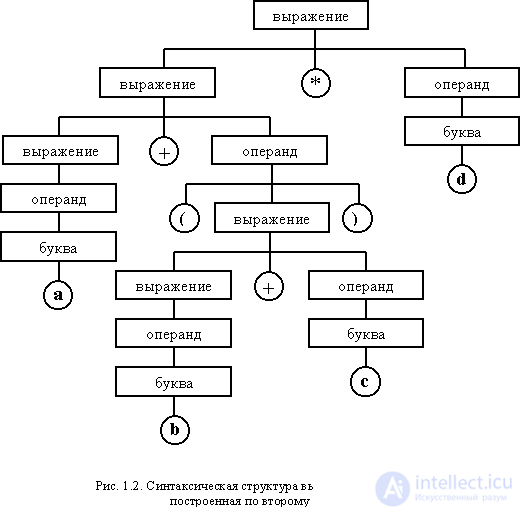
It should be noted that the hierarchical structure in the general case may not be in any way connected with the semantics of the expression. In either case, the priority of performing operations can be implemented in accordance with generally accepted rules when multiplication precedes addition (or vice versa, all operations can have the same priority for any set of rules). However, the first structure clearly supports the further implementation of generally accepted priority, while the second is more suitable for the implementation of operations with the same priority and their execution from right to left.
The process of finding the syntactic structure of a given program is called parsing .
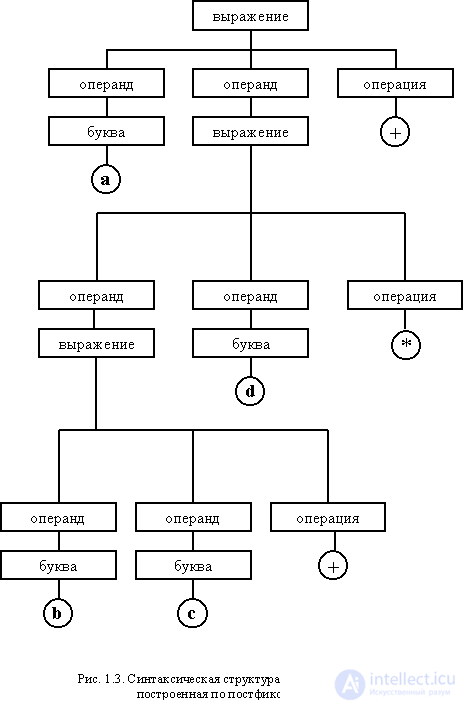
A syntactic structure that is correct for one language may be erroneous for another. For example, in the Fort language, the above expression will not be recognized. However, for this language, the postfix expression will be correct:
abc + d * +
Its syntactic structure is described by the rules:
<expression> :: = <letter> | <operand> <operand> <operation>
<operand> :: = <letter> | <expression>
<operation> :: = + | *
<letter> :: = a | b | c | d | i | f | g | h | i | j | k | l | m | n | o | p | q | r | s | t | u | v | w | x | y | z
The hierarchical tree defining the syntactic structure is shown in fig. 1.3.
Another characteristic feature of all languages is their semantics. It determines the meaning of the operations of the language, the correctness of the operands. Chains that have the same syntactic structure in different programming languages may differ in semantics (as, for example, observed in C ++, Pascal, Basic for the above fragment of an arithmetic expression).
Knowledge of the semantics of the language allows you to separate it from its syntax and use it to convert it into another language (to generate code).
Description of semantics and recognition of its correctness is usually the most time-consuming and volumetric part of the translator, since it is necessary to search and analyze a variety of options for admissible combinations of operations and operands.

Comments
To leave a comment
Programming Languages and Methods / Translation Theory
Terms: Programming Languages and Methods / Translation Theory